StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
2403.07714
0
0
Abstract
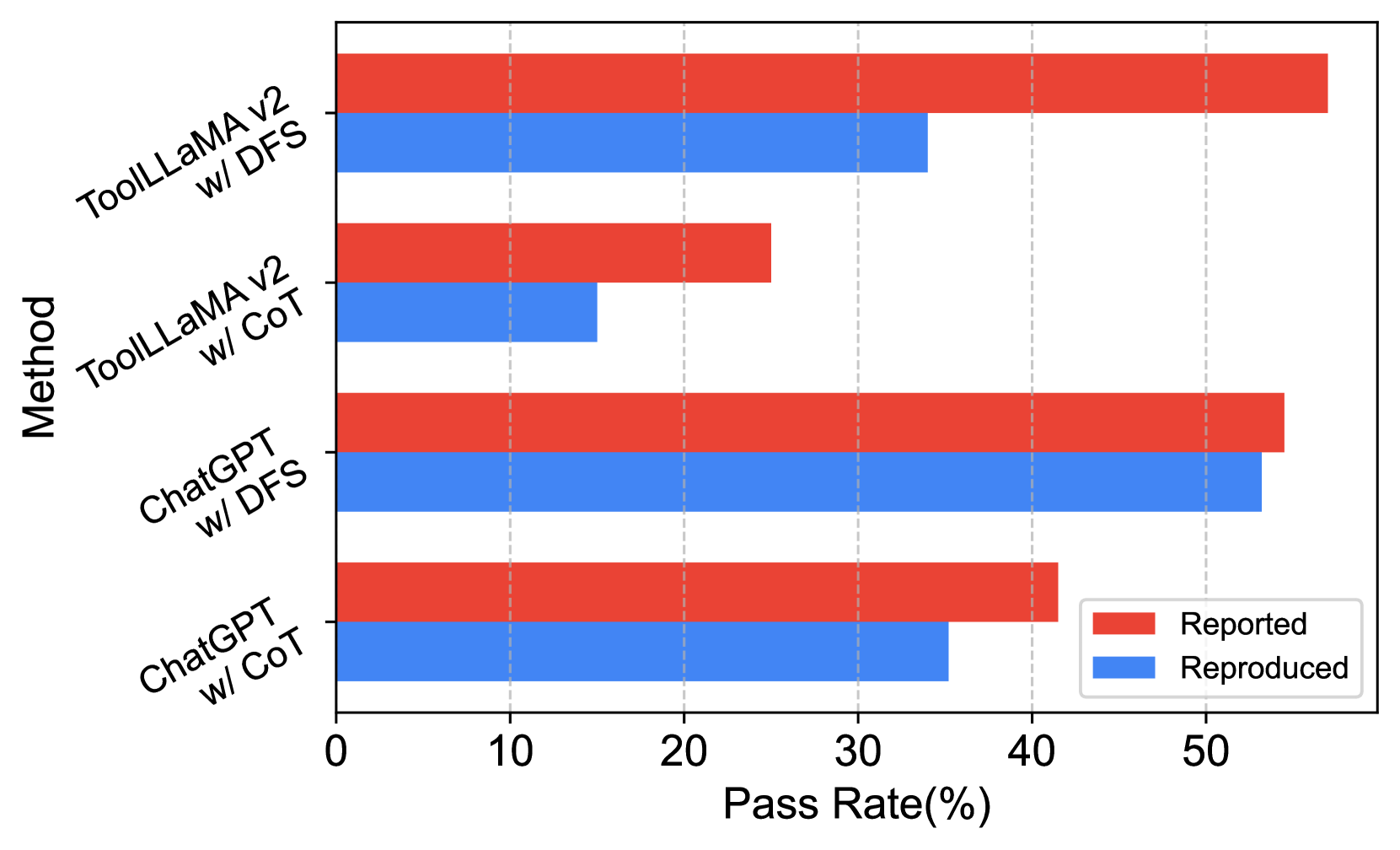
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
Create account to get full access
Overview
• This paper introduces StableToolBench, a new benchmarking framework for evaluating the tool learning capabilities of large language models (LLMs).
• The key focus is on ensuring the stability and reliability of the benchmark, which is critical for accurately measuring and comparing the tool-related performance of different LLMs.
• The paper explores various aspects of stability, including performance stability, prompt stability, and dataset stability, to provide a comprehensive evaluation of LLM tool learning abilities.
Plain English Explanation
The paper proposes a new benchmark called StableToolBench to assess how well large language models (LLMs) can learn and use various tools. The goal is to create a reliable and consistent way to measure and compare the tool-related capabilities of different LLMs.
One of the main challenges in benchmarking tool learning is ensuring the stability of the results. This means that the performance of an LLM on the benchmark should be consistent and not heavily influenced by factors like the specific prompts used or the composition of the dataset.
The paper explores different aspects of stability, such as:
- Performance Stability: Ensuring that an LLM's tool-related performance is stable and not overly sensitive to small changes in the input.
- Prompt Stability: Verifying that the LLM's performance is not heavily dependent on the specific prompts used to test its tool-related capabilities.
- Dataset Stability: Confirming that the LLM's performance is not unduly affected by the composition or characteristics of the dataset used for the benchmark.
By addressing these stability concerns, the researchers aim to create a more reliable and meaningful way to assess the tool-learning abilities of large language models. This could help advance the development of LLMs that can effectively leverage a wide range of tools to solve complex problems.
Technical Explanation
The paper introduces StableToolBench, a new benchmarking framework designed to evaluate the tool learning capabilities of large language models (LLMs) in a stable and reliable manner.
The researchers focus on three key aspects of stability:
-
Performance Stability: The paper examines the stability of an LLM's tool-related performance, ensuring that its results are not overly sensitive to small changes in the input. This is crucial for accurately measuring and comparing the tool-learning abilities of different LLMs.
-
Prompt Stability: The researchers investigate the impact of the specific prompts used to test the LLM's tool-related capabilities. They aim to ensure that the LLM's performance is not heavily dependent on the particular prompts, allowing for more generalizable and meaningful comparisons.
-
Dataset Stability: The paper also explores the stability of the LLM's performance concerning the composition and characteristics of the dataset used for the benchmark. This helps to ensure that the benchmark results are not unduly influenced by the specific dataset.
By addressing these stability concerns, the authors aim to create a more robust and reliable benchmarking framework for evaluating the tool-learning abilities of large language models. This could lead to the development of LLMs that can more effectively leverage a wide range of tools to solve complex problems.
Critical Analysis
The paper's focus on stability is commendable, as it recognizes the importance of reliable and consistent benchmarking for accurately measuring and comparing the tool-related capabilities of different large language models.
One potential limitation, however, is the scope of the benchmark itself. While the authors strive for stability, it's unclear how the specific set of tools and tasks included in StableToolBench may impact the generalizability of the results. The paper does not discuss the process of selecting the tools and tasks, or how representative they are of real-world tool-related challenges.
Additionally, the paper does not address the potential impact of dataset biases or other dataset-related issues that could influence the LLM's performance. While the authors examine dataset stability, they do not delve into the potential biases or limitations of the datasets used in the benchmark.
Further research could explore the robustness of StableToolBench across a wider range of tools and tasks, as well as investigating the impact of dataset characteristics and potential biases on the LLM's tool-related performance.
Conclusion
The StableToolBench framework introduced in this paper represents a significant step towards more reliable and consistent benchmarking of large language models' tool-learning capabilities. By addressing key aspects of stability, including performance, prompts, and datasets, the researchers aim to create a more meaningful and comparable way to assess the tool-related skills of different LLMs.
The emphasis on stability is crucial, as it can help ensure that the benchmark results accurately reflect the LLMs' true tool-learning abilities, rather than being unduly influenced by external factors. This, in turn, can contribute to the development of LLMs that can more effectively leverage a wide range of tools to tackle complex problems, with potential applications across various domains.
While the paper does not address all possible limitations, its focus on stability and the rigorous approach to benchmarking make it a valuable contribution to the field of large language model research and evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
Shijue Huang, Wanjun Zhong, Jianqiao Lu, Qi Zhu, Jiahui Gao, Weiwen Liu, Yutai Hou, Xingshan Zeng, Yasheng Wang, Lifeng Shang, Xin Jiang, Ruifeng Xu, Qun Liu
0
0
The recent trend of using Large Language Models (LLMs) as tool agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools. However, existing benchmarks typically focus on simple synthesized queries that do not reflect real-world complexity, thereby offering limited perspectives in evaluating tool utilization. To address this issue, we present UltraTool, a novel benchmark designed to improve and evaluate LLMs' ability in tool utilization within real-world scenarios. UltraTool focuses on the entire process of using tools - from planning and creating to applying them in complex tasks. It emphasizes real-world complexities, demanding accurate, multi-step planning for effective problem-solving. A key feature of UltraTool is its independent evaluation of planning with natural language, which happens before tool usage and simplifies the task solving by mapping out the intermediate steps. Thus, unlike previous work, it eliminates the restriction of pre-defined toolset. Through extensive experiments on various LLMs, we offer novel insights into the evaluation of capabilities of LLMs in tool utilization, thereby contributing a fresh perspective to this rapidly evolving field. The benchmark is publicly available at https://github.com/JoeYing1019/UltraTool.
6/4/2024

CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jie Feng, Jun Zhang, Junbo Yan, Xin Zhang, Tianjian Ouyang, Tianhui Liu, Yuwei Du, Siqi Guo, Yong Li
0
0
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
6/21/2024

Chain of Tools: Large Language Model is an Automatic Multi-tool Learner
Zhengliang Shi, Shen Gao, Xiuyi Chen, Yue Feng, Lingyong Yan, Haibo Shi, Dawei Yin, Zhumin Chen, Suzan Verberne, Zhaochun Ren
0
0
Augmenting large language models (LLMs) with external tools has emerged as a promising approach to extend their utility, empowering them to solve practical tasks. Existing work typically empowers LLMs as tool users with a manually designed workflow, where the LLM plans a series of tools in a step-by-step manner, and sequentially executes each tool to obtain intermediate results until deriving the final answer. However, they suffer from two challenges in realistic scenarios: (1) The handcrafted control flow is often ad-hoc and constraints the LLM to local planning; (2) The LLM is instructed to use only manually demonstrated tools or well-trained Python functions, which limits its generalization to new tools. In this work, we first propose Automatic Tool Chain (ATC), a framework that enables the LLM to act as a multi-tool user, which directly utilizes a chain of tools through programming. To scale up the scope of the tools, we next propose a black-box probing method. This further empowers the LLM as a tool learner that can actively discover and document tool usages, teaching themselves to properly master new tools. For a comprehensive evaluation, we build a challenging benchmark named ToolFlow, which diverges from previous benchmarks by its long-term planning scenarios and complex toolset. Experiments on both existing datasets and ToolFlow illustrate the superiority of our framework. Analysis on different settings also validates the effectiveness and the utility of our black-box probing algorithm.
5/28/2024
STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, Jingping Bi
0
0
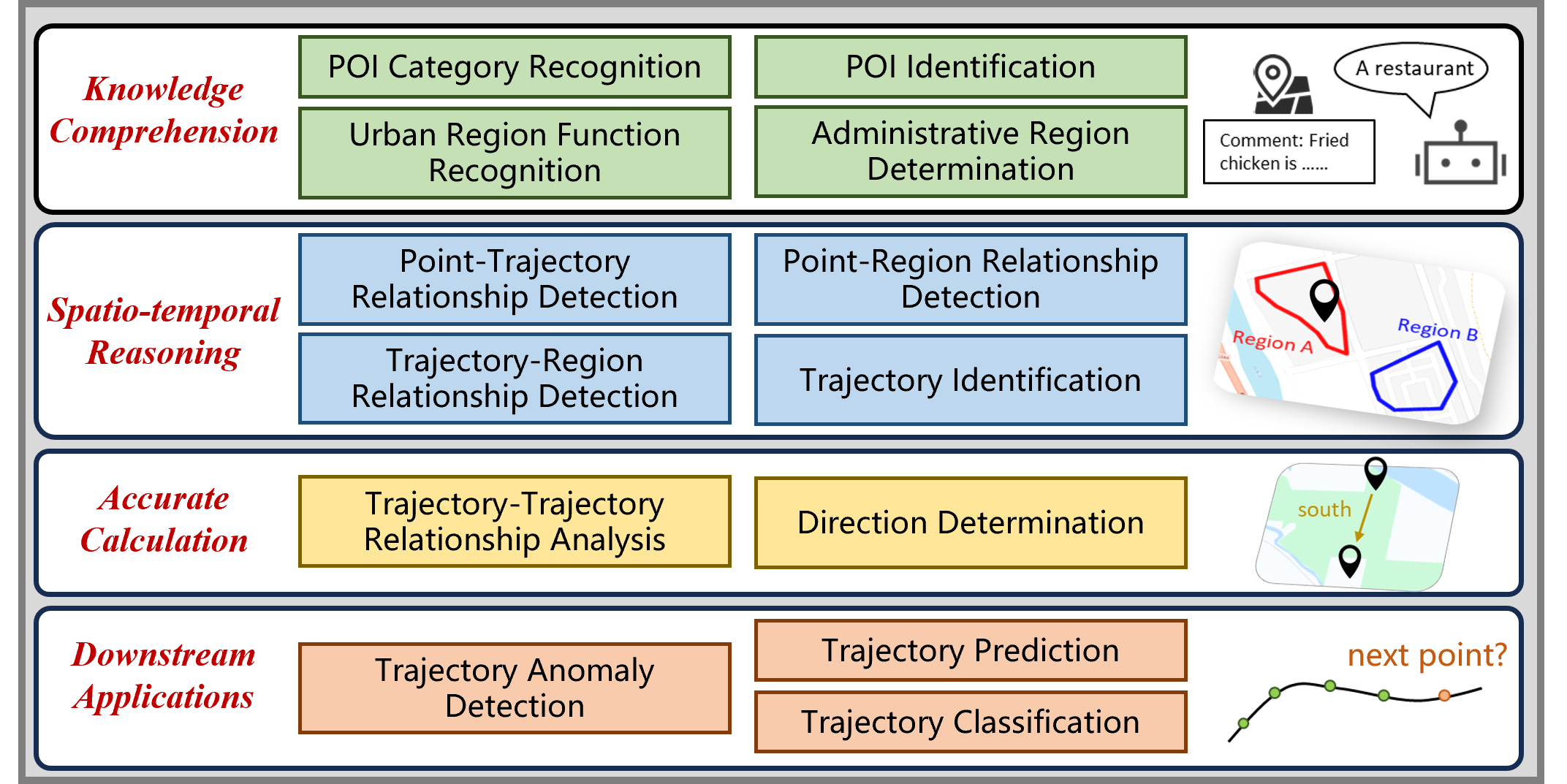
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
6/28/2024