Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
2401.17167
0
0
👁️
Abstract
The recent trend of using Large Language Models (LLMs) as tool agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools. However, existing benchmarks typically focus on simple synthesized queries that do not reflect real-world complexity, thereby offering limited perspectives in evaluating tool utilization. To address this issue, we present UltraTool, a novel benchmark designed to improve and evaluate LLMs' ability in tool utilization within real-world scenarios. UltraTool focuses on the entire process of using tools - from planning and creating to applying them in complex tasks. It emphasizes real-world complexities, demanding accurate, multi-step planning for effective problem-solving. A key feature of UltraTool is its independent evaluation of planning with natural language, which happens before tool usage and simplifies the task solving by mapping out the intermediate steps. Thus, unlike previous work, it eliminates the restriction of pre-defined toolset. Through extensive experiments on various LLMs, we offer novel insights into the evaluation of capabilities of LLMs in tool utilization, thereby contributing a fresh perspective to this rapidly evolving field. The benchmark is publicly available at https://github.com/JoeYing1019/UltraTool.
Create account to get full access
Overview
- The paper presents a new benchmark called UltraTool to evaluate the ability of Large Language Models (LLMs) to utilize tools in real-world scenarios.
- Existing benchmarks typically focus on simple, synthesized queries that do not reflect the complexity of real-world tool usage, which involves planning, creating, and applying tools effectively.
- UltraTool aims to address this gap by focusing on the entire process of tool utilization, emphasizing accurate, multi-step planning for problem-solving.
Plain English Explanation
The paper discusses the growing use of Large Language Models (LLMs) as "tool agents" in various applications. However, the researchers argue that the current benchmarks used to evaluate these models' capabilities are limited, as they typically focus on simple, artificial scenarios that don't reflect the complexities of real-world tool usage.
To address this issue, the researchers have developed a new benchmark called UltraTool. This benchmark focuses on the entire process of using tools, from planning and creating to applying them in complex tasks. It emphasizes the importance of accurate, multi-step planning for effective problem-solving, which is a crucial aspect of real-world tool utilization.
One key feature of UltraTool is its independent evaluation of planning with natural language, which happens before the actual tool usage. This approach simplifies the task-solving process by mapping out the intermediate steps, unlike previous benchmarks that restricted the available tool set. By evaluating the planning capabilities separately, UltraTool aims to provide a more comprehensive assessment of an LLM's ability to utilize tools effectively.
Technical Explanation
The paper presents the UltraTool benchmark, which is designed to improve the evaluation of LLMs' capabilities in tool utilization within real-world scenarios. Unlike existing benchmarks that focus on simple, synthesized queries, UltraTool emphasizes the entire process of using tools, including planning, creating, and applying them in complex tasks.
The researchers argue that the current benchmarks offer limited perspectives in evaluating tool utilization, as they do not reflect the real-world complexities involved. To address this, UltraTool focuses on accurate, multi-step planning for problem-solving, which is a crucial aspect of effective tool usage.
A key feature of UltraTool is its independent evaluation of planning with natural language, which happens before the actual tool usage. This approach simplifies the task-solving process by mapping out the intermediate steps, eliminating the restriction of pre-defined tool sets that was present in previous work.
Through extensive experiments on various LLMs, the researchers offer novel insights into the evaluation of these models' capabilities in tool utilization, contributing a fresh perspective to this rapidly evolving field. The benchmark is publicly available at https://github.com/JoeYing1019/UltraTool.
Critical Analysis
The researchers acknowledge that the UltraTool benchmark, while addressing the limitations of existing benchmarks, may still have some caveats and areas for further research. For example, the paper does not provide a detailed analysis of the specific challenges or complexities encountered in the real-world scenarios used in the benchmark.
Additionally, the paper does not delve into the potential biases or limitations of the natural language planning component of UltraTool. It would be valuable to explore how the planning phase may influence the subsequent tool usage and problem-solving, and whether there are any potential issues or edge cases that should be considered.
Furthermore, the researchers could have provided a more in-depth discussion of the implications and potential applications of the insights gained from their experiments on various LLMs. Exploring how these findings could inform the development of more robust and versatile tool-utilizing LLMs would be a valuable contribution to the field.
Conclusion
The paper presents the UltraTool benchmark, which aims to improve the evaluation of Large Language Models' (LLMs) capabilities in tool utilization within real-world scenarios. By focusing on the entire process of using tools, from planning and creating to applying them in complex tasks, UltraTool provides a more comprehensive assessment of an LLM's abilities.
The researchers' experiments on various LLMs offer novel insights into the evaluation of tool utilization, contributing a fresh perspective to this rapidly evolving field. The public availability of the UltraTool benchmark [https://aimodels.fyi/papers/arxiv/evaluating-llms-at-evaluating-temporal-generalization] presents an opportunity for further research and development in this area, ultimately leading to the creation of more robust and versatile tool-utilizing LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A User-Centric Benchmark for Evaluating Large Language Models
Jiayin Wang, Fengran Mo, Weizhi Ma, Peijie Sun, Min Zhang, Jian-Yun Nie
0
0
Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
4/24/2024

CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jie Feng, Jun Zhang, Junbo Yan, Xin Zhang, Tianjian Ouyang, Tianhui Liu, Yuwei Du, Siqi Guo, Yong Li
0
0
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
6/21/2024
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, Yang Liu
0
0
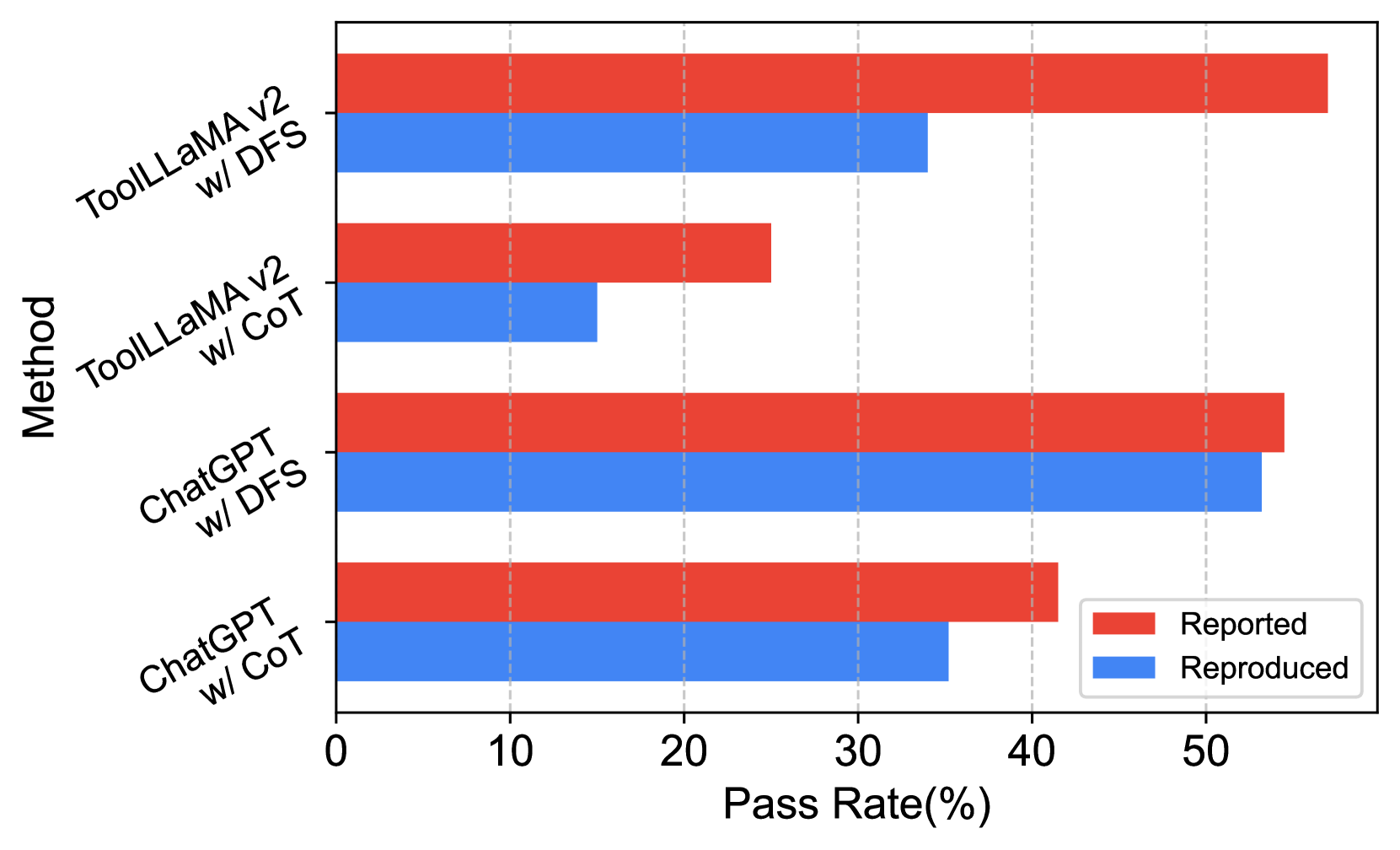
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
6/21/2024

Towards Practical Tool Usage for Continually Learning LLMs
Jerry Huang, Prasanna Parthasarathi, Mehdi Rezagholizadeh, Sarath Chandar
0
0
Large language models (LLMs) show an innate skill for solving language based tasks. But insights have suggested an inability to adjust for information or task-solving skills becoming outdated, as their knowledge, stored directly within their parameters, remains static in time. Tool use helps by offloading work to systems that the LLM can access through an interface, but LLMs that use them still must adapt to nonstationary environments for prolonged use, as new tools can emerge and existing tools can change. Nevertheless, tools require less specialized knowledge, therefore we hypothesize they are better suited for continual learning (CL) as they rely less on parametric memory for solving tasks and instead focus on learning when to apply pre-defined tools. To verify this, we develop a synthetic benchmark and follow this by aggregating existing NLP tasks to form a more realistic testing scenario. While we demonstrate scaling model size is not a solution, regardless of tool usage, continual learning techniques can enable tool LLMs to both adapt faster while forgetting less, highlighting their potential as continual learners.
4/16/2024