STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
2406.19065
0
0
Abstract
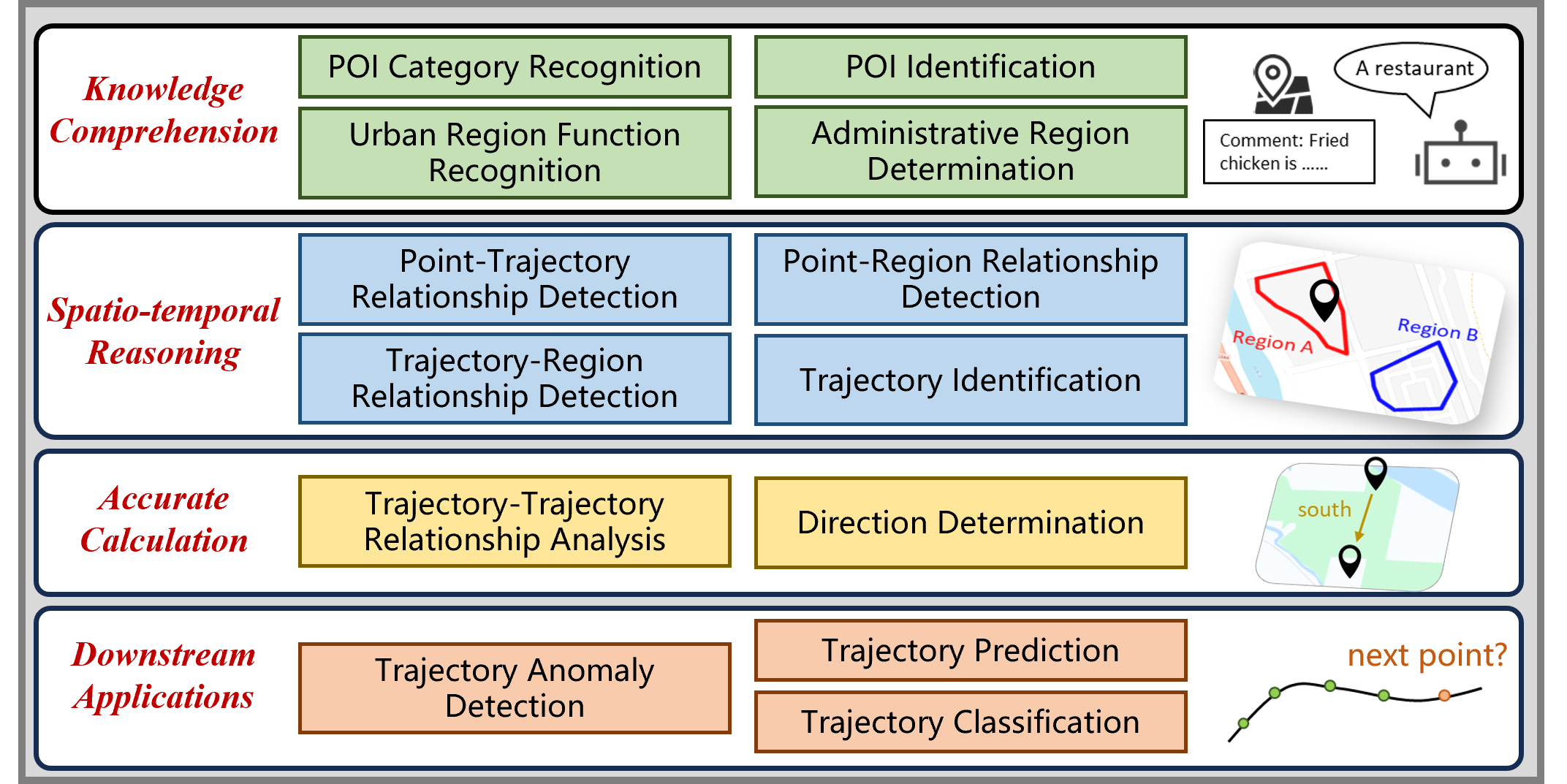
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
Create account to get full access
Overview
- This paper presents STBench, a benchmark for evaluating the spatio-temporal analysis capabilities of large language models (LLMs).
- It explores how well LLMs can understand and reason about spatial and temporal relationships in text-based tasks.
- The benchmark covers a range of tasks, including spatial understanding, temporal reasoning, and time series feature extraction.
- The authors use STBench to assess the performance of several state-of-the-art LLMs, providing insights into their current capabilities and limitations in spatio-temporal analysis.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can process and generate human-like text. However, their ability to understand and reason about spatial and temporal relationships in text-based tasks has not been well-studied.
The researchers created a benchmark called STBench to address this gap. STBench is a collection of tasks that test how well LLMs can handle spatial and temporal information in text. For example, one task might ask the model to determine the relative locations of objects described in a passage, while another might require the model to infer the timeline of events.
By applying STBench to several state-of-the-art LLMs, the researchers were able to assess the models' strengths and weaknesses in spatio-temporal analysis. This provides valuable insights into the current capabilities of these AI systems and highlights areas where further development is needed.
Technical Explanation
The paper describes the development and application of STBench, a comprehensive benchmark for evaluating the spatio-temporal analysis capabilities of large language models (LLMs).
The benchmark consists of a suite of tasks that assess various aspects of spatial and temporal reasoning, including spatial understanding, temporal reasoning, and time series feature extraction. These tasks are designed to challenge LLMs in their ability to comprehend and reason about the spatial and temporal information present in text-based inputs.
The researchers applied STBench to several state-of-the-art LLMs, including GPT-3, BERT, and RoBERTa, to assess their performance on the benchmark. The results provide a comprehensive evaluation of the models' spatio-temporal analysis capabilities, highlighting their strengths and weaknesses across the different task categories.
The insights gained from this research can inform the development of more capable LLMs that can better understand and reason about the spatial and temporal aspects of language, which is crucial for a wide range of applications, such as natural language understanding, question answering, and decision-making systems.
Critical Analysis
The STBench benchmark presented in this paper provides a valuable contribution to the field of spatio-temporal analysis for large language models. By designing a comprehensive set of tasks that challenge the models' understanding of spatial and temporal information, the researchers have developed a robust tool for assessing the current state of LLM capabilities in this area.
One potential limitation of the study is the specificity of the tasks included in STBench. While the researchers have made an effort to cover a broad range of spatio-temporal reasoning skills, it's possible that there are other aspects of language understanding that are not fully captured by the benchmark. Additionally, the performance of LLMs on these tasks may not necessarily translate directly to their real-world application in complex, open-ended scenarios.
The researchers acknowledge these limitations and suggest that further research is needed to explore the generalizability of the STBench findings and to continue improving the spatio-temporal analysis capabilities of LLMs. This could involve expanding the benchmark to include more diverse task types, as well as investigating the impact of architectural changes, training data, and other factors on the models' performance.
Overall, the STBench benchmark and the insights gained from its application to state-of-the-art LLMs represent an important step forward in understanding the strengths and limitations of these powerful AI systems in the domain of spatio-temporal reasoning.
Conclusion
The STBench benchmark developed in this paper provides a comprehensive evaluation of the spatio-temporal analysis capabilities of large language models (LLMs). By assessing the performance of several state-of-the-art LLMs on a range of tasks involving spatial understanding, temporal reasoning, and time series feature extraction, the researchers have gained valuable insights into the current state of these models' abilities to comprehend and reason about the spatial and temporal aspects of language.
The findings from this study highlight both the impressive capabilities of LLMs in certain areas of spatio-temporal analysis, as well as the limitations that still exist. These insights can inform the continued development of more capable LLMs that can better understand and reason about the spatial and temporal dimensions of language, which is crucial for a wide range of applications in natural language processing, decision-making, and beyond.
As the field of AI continues to advance, benchmarks like STBench will play an increasingly important role in driving progress and ensuring that the capabilities of large language models keep pace with the evolving needs of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How Can Large Language Models Understand Spatial-Temporal Data?
Lei Liu, Shuo Yu, Runze Wang, Zhenxun Ma, Yanming Shen
0
0
While Large Language Models (LLMs) dominate tasks like natural language processing and computer vision, harnessing their power for spatial-temporal forecasting remains challenging. The disparity between sequential text and complex spatial-temporal data hinders this application. To address this issue, this paper introduces STG-LLM, an innovative approach empowering LLMs for spatial-temporal forecasting. We tackle the data mismatch by proposing: 1) STG-Tokenizer: This spatial-temporal graph tokenizer transforms intricate graph data into concise tokens capturing both spatial and temporal relationships; 2) STG-Adapter: This minimalistic adapter, consisting of linear encoding and decoding layers, bridges the gap between tokenized data and LLM comprehension. By fine-tuning only a small set of parameters, it can effectively grasp the semantics of tokens generated by STG-Tokenizer, while preserving the original natural language understanding capabilities of LLMs. Extensive experiments on diverse spatial-temporal benchmark datasets show that STG-LLM successfully unlocks LLM potential for spatial-temporal forecasting. Remarkably, our approach achieves competitive performance on par with dedicated SOTA methods.
5/20/2024
⛏️
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Benyou Wang
0
0
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
5/15/2024
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, Bryan Perozzi
0
0
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
6/14/2024

New!TimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, Bing Qin
0
0
Grasping the concept of time is a fundamental facet of human cognition, indispensable for truly comprehending the intricacies of the world. Previous studies typically focus on specific aspects of time, lacking a comprehensive temporal reasoning benchmark. To address this, we propose TimeBench, a comprehensive hierarchical temporal reasoning benchmark that covers a broad spectrum of temporal reasoning phenomena. TimeBench provides a thorough evaluation for investigating the temporal reasoning capabilities of large language models. We conduct extensive experiments on GPT-4, LLaMA2, and other popular LLMs under various settings. Our experimental results indicate a significant performance gap between the state-of-the-art LLMs and humans, highlighting that there is still a considerable distance to cover in temporal reasoning. Besides, LLMs exhibit capability discrepancies across different reasoning categories. Furthermore, we thoroughly analyze the impact of multiple aspects on temporal reasoning and emphasize the associated challenges. We aspire for TimeBench to serve as a comprehensive benchmark, fostering research in temporal reasoning. Resources are available at: https://github.com/zchuz/TimeBench
7/1/2024