Stepwise Alignment for Constrained Language Model Policy Optimization

0
Sign in to get full access
Overview
- This paper introduces a novel approach called "Stepwise Alignment" for optimizing the policy of a constrained language model.
- The key idea is to align the language model's policy with a reference policy in a stepwise manner, rather than directly optimizing the language model's objective.
- The authors demonstrate that this stepwise alignment technique can achieve better performance on language generation tasks compared to standard policy optimization methods.
Plain English Explanation
The paper presents a new way to train language models to generate better text. Language models are AI systems that can produce human-like text, but they can sometimes struggle to follow specific rules or guidelines.
The authors' approach, called "Stepwise Alignment," tries to solve this problem by training the language model in a step-by-step way. Instead of just optimizing the model to maximize some overall score, the Stepwise Alignment method aligns the model's behavior with a reference policy - a set of rules or guidelines for what the text should look like.
By training the model to match this reference policy in a gradual, step-by-step fashion, the authors show that the language model can learn to generate text that is more in line with the desired constraints or rules. This could be useful for applications where the generated text needs to follow certain guidelines, such as in content moderation or creative writing assistants.
Technical Explanation
The key idea behind the Stepwise Alignment approach is to optimize the language model's policy in a stepwise manner, rather than directly optimizing the model's objective. The authors first define a reference policy that encodes the desired constraints or preferences for the generated text.
They then train the language model to gradually align its policy with the reference policy, using a technique called Constrained Policy Optimization (CPO). CPO allows the model to optimize its policy while respecting the given constraints.
The stepwise nature of the alignment process is achieved by iteratively updating the reference policy based on the current state of the language model. This helps the model learn to generate text that satisfies the desired constraints in an incremental fashion.
The authors evaluate their Stepwise Alignment approach on several language generation tasks, including text summarization and story completion. They show that it outperforms standard policy optimization methods, such as Listwise Preference Optimization (LiPO), in terms of both quality and constraint satisfaction.
Critical Analysis
The authors acknowledge that the Stepwise Alignment approach relies on the availability of a suitable reference policy, which may not always be easy to define or obtain. They suggest that future work could explore methods for automatically learning the reference policy from data, which could make the approach more broadly applicable.
Additionally, the authors note that the stepwise nature of the alignment process can lead to slower convergence compared to direct policy optimization. This trade-off between constraint satisfaction and optimization speed may need to be carefully considered in practical applications.
Another potential limitation is that the paper does not provide a thorough analysis of the computational complexity and scalability of the Stepwise Alignment approach, which could be an important consideration for real-world deployments.
Overall, the Stepwise Alignment method represents a promising approach for optimizing language models under specific constraints, but further research may be needed to address some of the potential challenges and limitations identified in the paper.
Conclusion
The Stepwise Alignment technique introduced in this paper offers a novel way to train constrained language models, allowing them to generate text that better adheres to desired guidelines or preferences. By gradually aligning the model's policy with a reference policy, the approach can improve the quality and constraint satisfaction of the generated text compared to standard policy optimization methods.
While the approach has some potential limitations, the authors have demonstrated its effectiveness on several language generation tasks. This work could have important implications for the development of more controlled and reliable language models, with applications in areas like content moderation, creative writing assistance, and aligning language models with human preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stepwise Alignment for Constrained Language Model Policy Optimization
Akifumi Wachi, Thien Q. Tran, Rei Sato, Takumi Tanabe, Youhei Akimoto
Safety and trustworthiness are indispensable requirements for real-world applications of AI systems using large language models (LLMs). This paper formulates human value alignment as an optimization problem of the language model policy to maximize reward under a safety constraint, and then proposes an algorithm, Stepwise Alignment for Constrained Policy Optimization (SACPO). One key idea behind SACPO, supported by theory, is that the optimal policy incorporating reward and safety can be directly obtained from a reward-aligned policy. Building on this key idea, SACPO aligns LLMs step-wise with each metric while leveraging simple yet powerful alignment algorithms such as direct preference optimization (DPO). SACPO offers several advantages, including simplicity, stability, computational efficiency, and flexibility of algorithms and datasets. Under mild assumptions, our theoretical analysis provides the upper bounds on optimality and safety constraint violation. Our experimental results show that SACPO can fine-tune Alpaca-7B better than the state-of-the-art method in terms of both helpfulness and harmlessness.
Read more5/24/2024

0
State-wise Constrained Policy Optimization
Weiye Zhao, Rui Chen, Yifan Sun, Tianhao Wei, Changliu Liu
Reinforcement Learning (RL) algorithms have shown tremendous success in simulation environments, but their application to real-world problems faces significant challenges, with safety being a major concern. In particular, enforcing state-wise constraints is essential for many challenging tasks such as autonomous driving and robot manipulation. However, existing safe RL algorithms under the framework of Constrained Markov Decision Process (CMDP) do not consider state-wise constraints. To address this gap, we propose State-wise Constrained Policy Optimization (SCPO), the first general-purpose policy search algorithm for state-wise constrained reinforcement learning. SCPO provides guarantees for state-wise constraint satisfaction in expectation. In particular, we introduce the framework of Maximum Markov Decision Process, and prove that the worst-case safety violation is bounded under SCPO. We demonstrate the effectiveness of our approach on training neural network policies for extensive robot locomotion tasks, where the agent must satisfy a variety of state-wise safety constraints. Our results show that SCPO significantly outperforms existing methods and can handle state-wise constraints in high-dimensional robotics tasks.
Read more6/19/2024
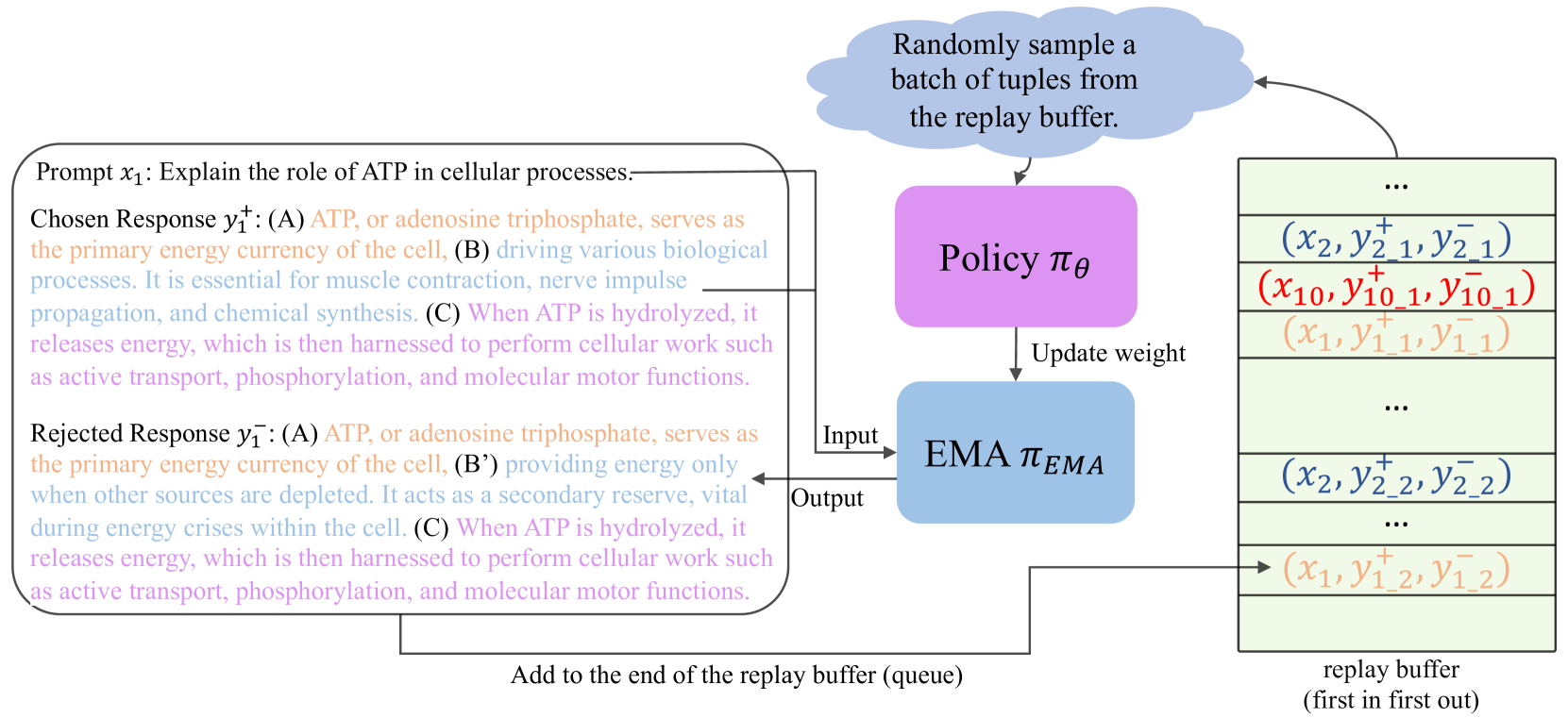
0
Self-Augmented Preference Optimization: Off-Policy Paradigms for Language Model Alignment
Yueqin Yin, Zhendong Wang, Yujia Xie, Weizhu Chen, Mingyuan Zhou
Traditional language model alignment methods, such as Direct Preference Optimization (DPO), are limited by their dependence on static, pre-collected paired preference data, which hampers their adaptability and practical applicability. To overcome this limitation, we introduce Self-Augmented Preference Optimization (SAPO), an effective and scalable training paradigm that does not require existing paired data. Building on the self-play concept, which autonomously generates negative responses, we further incorporate an off-policy learning pipeline to enhance data exploration and exploitation. Specifically, we employ an Exponential Moving Average (EMA) model in conjunction with a replay buffer to enable dynamic updates of response segments, effectively integrating real-time feedback with insights from historical data. Our comprehensive evaluations of the LLaMA3-8B and Mistral-7B models across benchmarks, including the Open LLM Leaderboard, IFEval, AlpacaEval 2.0, and MT-Bench, demonstrate that SAPO matches or surpasses established offline contrastive baselines, such as DPO and Odds Ratio Preference Optimization, and outperforms offline self-play methods like SPIN. Our code is available at https://github.com/yinyueqin/SAPO
Read more6/3/2024

0
ABC Align: Large Language Model Alignment for Safety & Accuracy
Gareth Seneque, Lap-Hang Ho, Ariel Kuperman, Nafise Erfanian Saeedi, Jeffrey Molendijk
Alignment of Large Language Models (LLMs) remains an unsolved problem. Human preferences are highly distributed and can be captured at multiple levels of abstraction, from the individual to diverse populations. Organisational preferences, represented by standards and principles, are defined to mitigate reputational risk or meet legislative obligations. In this paper, we present ABC Align, a novel alignment methodology for LLMs that enables integration of the standards and preferences of a large media organisation into the LLM itself. We combine a set of data and methods that build on recent breakthroughs in synthetic data generation, preference optimisation, and post-training model quantisation. Our unified approach mitigates bias and improves accuracy, while preserving reasoning capability, as measured against standard benchmarks.
Read more8/2/2024