Stochastic RAG: End-to-End Retrieval-Augmented Generation through Expected Utility Maximization
2405.02816
0
0
Abstract
This paper introduces Stochastic RAG--a novel approach for end-to-end optimization of retrieval-augmented generation (RAG) models that relaxes the simplifying assumptions of marginalization and document independence, made in most prior work. Stochastic RAG casts the retrieval process in RAG as a stochastic sampling without replacement process. Through this formulation, we employ straight-through Gumbel-top-k that provides a differentiable approximation for sampling without replacement and enables effective end-to-end optimization for RAG. We conduct extensive experiments on seven diverse datasets on a wide range of tasks, from open-domain question answering to fact verification to slot-filling for relation extraction and to dialogue systems. By applying this optimization method to a recent and effective RAG model, we advance state-of-the-art results on six out of seven datasets.
Create account to get full access
Overview
- The paper presents a new approach called Stochastic RAG (Retrieval-Augmented Generation) that aims to improve the quality of retrieval-enhanced machine learning models.
- Stochastic RAG utilizes an expected utility maximization framework to optimize the retrieval and generation process, leading to better performance on various tasks.
- The paper compares Stochastic RAG to existing retrieval-augmented models and demonstrates its advantages through extensive experiments.
Plain English Explanation
Retrieval-augmented generation is a technique used in machine learning where a model can search for and incorporate relevant information from a database or knowledge base to improve the quality of its outputs. This approach has been explored in prior research, but the authors of this paper believe there is room for improvement.
The key idea behind Stochastic RAG is to treat the retrieval and generation process as a joint optimization problem. Rather than simply retrieving the most relevant information and using it, Stochastic RAG considers the potential utility of each piece of retrieved information and selects the combination that is expected to maximize the overall quality of the output. This is done through a mathematical framework called expected utility maximization.
By optimizing the retrieval and generation jointly, Stochastic RAG is able to produce outputs that are more coherent, relevant, and informative than those generated by previous retrieval-augmented models. The paper compares Stochastic RAG to other approaches, such as Blended RAG, and demonstrates its superiority on a range of tasks.
The authors also discuss how Stochastic RAG can be seen as a step towards "search engine machines" - AI systems that can seamlessly integrate information retrieval and generation to provide more intelligent and helpful responses. This aligns with other research in this direction.
Technical Explanation
The Stochastic RAG model consists of three key components: a retriever, a generator, and an expected utility maximization module. The retriever is responsible for finding relevant information from a knowledge base or database, while the generator uses this retrieved information to produce the final output.
The expected utility maximization module is the core innovation of Stochastic RAG. It evaluates the potential utility of each possible combination of retrieved information and selects the one that is expected to result in the highest-quality output. This is done by learning a utility function that captures the desired properties of the output, such as coherence, relevance, and informativeness.
During the training process, Stochastic RAG learns to optimize this utility function jointly with the retriever and generator, ensuring that the entire system works in harmony to produce the best possible results. The authors show that this end-to-end optimization leads to significant improvements over previous retrieval-augmented models, which often relied on separate retrieval and generation components.
The paper presents extensive experiments on a variety of tasks, including question answering, open-ended generation, and knowledge-intensive language understanding. Stochastic RAG outperforms other state-of-the-art retrieval-augmented models across the board, demonstrating the power of its joint optimization approach.
Critical Analysis
The authors of the paper acknowledge that Stochastic RAG, like any model, has some limitations. For example, the utility function used to guide the optimization process may not capture all the nuances of high-quality outputs, and there may be challenges in scaling the approach to very large knowledge bases.
Additionally, while the paper demonstrates the advantages of Stochastic RAG, it does not provide a detailed analysis of the types of errors or failures that the model may still experience. Further research could explore the limitations and failure modes of retrieval-augmented generation models more extensively.
Another potential area for improvement is the integration of Stochastic RAG with question answering models. The paper focuses on open-ended generation tasks, but the expected utility maximization approach could potentially be leveraged to enhance the performance of retrieval-augmented question answering as well.
Overall, the Stochastic RAG approach represents a significant step forward in the field of retrieval-augmented generation, and the authors have made a valuable contribution to the ongoing research in this area.
Conclusion
The Stochastic RAG model presented in this paper offers a novel and effective approach to retrieval-augmented generation. By jointly optimizing the retrieval and generation processes through an expected utility maximization framework, Stochastic RAG is able to produce outputs that are more coherent, relevant, and informative than those generated by previous retrieval-augmented models.
The paper's findings suggest that the integration of information retrieval and generation is a promising direction for the development of more capable and intelligent AI systems. As research in this area continues to progress, we can expect to see further advancements in the capabilities of "search engine machines" that can seamlessly combine these two crucial components of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Evaluating Retrieval Quality in Retrieval-Augmented Generation
Alireza Salemi, Hamed Zamani
0
0
Evaluating retrieval-augmented generation (RAG) presents challenges, particularly for retrieval models within these systems. Traditional end-to-end evaluation methods are computationally expensive. Furthermore, evaluation of the retrieval model's performance based on query-document relevance labels shows a small correlation with the RAG system's downstream performance. We propose a novel evaluation approach, eRAG, where each document in the retrieval list is individually utilized by the large language model within the RAG system. The output generated for each document is then evaluated based on the downstream task ground truth labels. In this manner, the downstream performance for each document serves as its relevance label. We employ various downstream task metrics to obtain document-level annotations and aggregate them using set-based or ranking metrics. Extensive experiments on a wide range of datasets demonstrate that eRAG achieves a higher correlation with downstream RAG performance compared to baseline methods, with improvements in Kendall's $tau$ correlation ranging from 0.168 to 0.494. Additionally, eRAG offers significant computational advantages, improving runtime and consuming up to 50 times less GPU memory than end-to-end evaluation.
4/23/2024
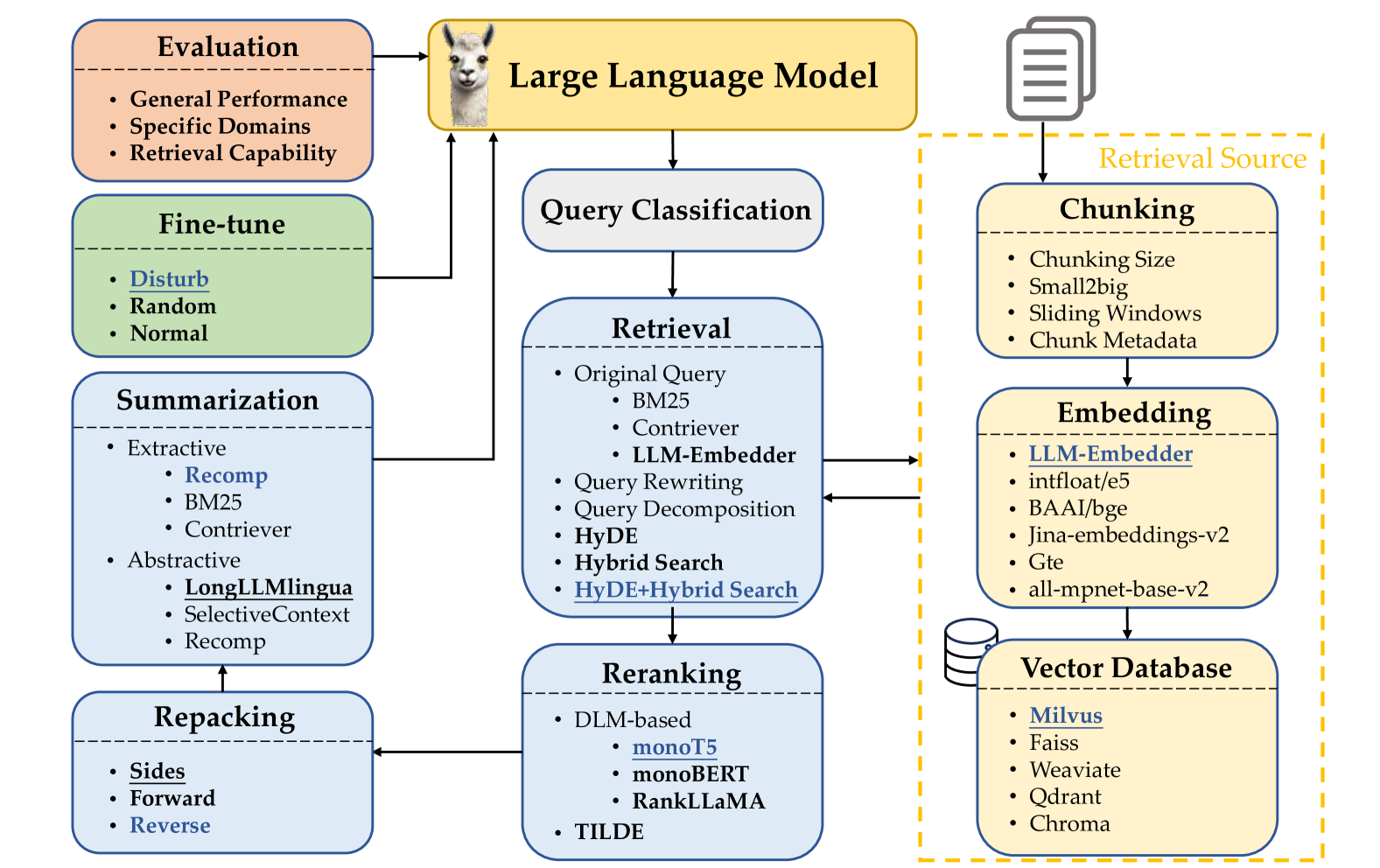
New!Searching for Best Practices in Retrieval-Augmented Generation
Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang, Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li, Qi Qian, Ruicheng Yin, Changze Lv, Xiaoqing Zheng, Xuanjing Huang
0
0
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a retrieval as generation strategy.
7/2/2024
⛏️
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
0
0
Retrieval-Augmented Generation (RAG) has emerged as a pivotal innovation in natural language processing, enhancing generative models by incorporating external information retrieval. Evaluating RAG systems, however, poses distinct challenges due to their hybrid structure and reliance on dynamic knowledge sources. We consequently enhanced an extensive survey and proposed an analysis framework for benchmarks of RAG systems, RAGR (Retrieval, Generation, Additional Requirement), designed to systematically analyze RAG benchmarks by focusing on measurable outputs and established truths. Specifically, we scrutinize and contrast multiple quantifiable metrics of the Retrieval and Generation component, such as relevance, accuracy, and faithfulness, of the internal links within the current RAG evaluation methods, covering the possible output and ground truth pairs. We also analyze the integration of additional requirements of different works, discuss the limitations of current benchmarks, and propose potential directions for further research to address these shortcomings and advance the field of RAG evaluation. In conclusion, this paper collates the challenges associated with RAG evaluation. It presents a thorough analysis and examination of existing methodologies for RAG benchmark design based on the proposed RGAR framework.
5/14/2024
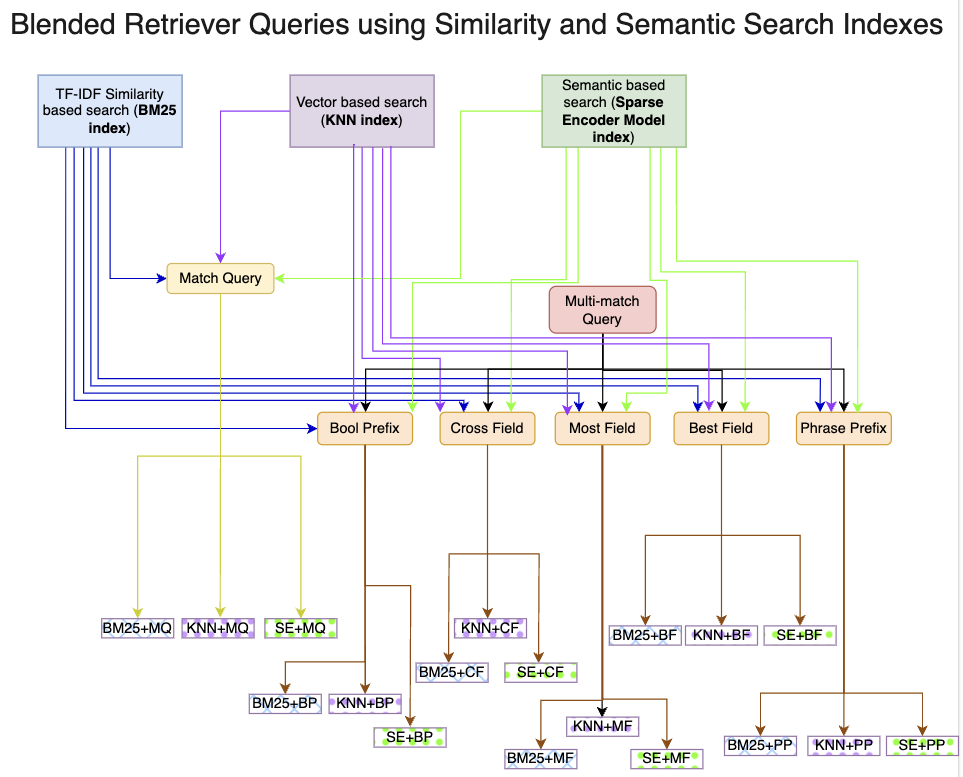
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
0
0
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
4/12/2024