Evaluating Retrieval Quality in Retrieval-Augmented Generation
2404.13781
0
0
🛸
Abstract
Evaluating retrieval-augmented generation (RAG) presents challenges, particularly for retrieval models within these systems. Traditional end-to-end evaluation methods are computationally expensive. Furthermore, evaluation of the retrieval model's performance based on query-document relevance labels shows a small correlation with the RAG system's downstream performance. We propose a novel evaluation approach, eRAG, where each document in the retrieval list is individually utilized by the large language model within the RAG system. The output generated for each document is then evaluated based on the downstream task ground truth labels. In this manner, the downstream performance for each document serves as its relevance label. We employ various downstream task metrics to obtain document-level annotations and aggregate them using set-based or ranking metrics. Extensive experiments on a wide range of datasets demonstrate that eRAG achieves a higher correlation with downstream RAG performance compared to baseline methods, with improvements in Kendall's $tau$ correlation ranging from 0.168 to 0.494. Additionally, eRAG offers significant computational advantages, improving runtime and consuming up to 50 times less GPU memory than end-to-end evaluation.
Create account to get full access
Overview
- This paper evaluates the retrieval quality in retrieval-augmented generation (RAG) models, which use a retrieval module to supplement a generation model with relevant information from a knowledge base.
- The authors propose new evaluation metrics to assess the retrieval quality in RAG models and demonstrate their usefulness through experiments on popular RAG models.
Plain English Explanation
Retrieval-augmented generation (RAG) models are a type of AI system that combine a retrieval module, which finds relevant information from a knowledge base, with a generation module, which uses that information to produce new text. The Blended-RAG, Retrieval-Augmented Generation, and iRAG models are examples of RAG systems.
Evaluating the retrieval quality of these models is important, as the retrieved information can significantly impact the generated output. This paper proposes new metrics to assess the retrieval quality, such as measuring how well the retrieved passages match the information needed for the task. The authors then use these metrics to evaluate popular RAG models, providing insights into their strengths and weaknesses.
Technical Explanation
The paper introduces new evaluation metrics to assess the retrieval quality in RAG models:
- Retrieval Relevance: Measures how relevant the retrieved passages are to the task at hand, using techniques like text similarity.
- Retrieval Diversity: Quantifies the diversity of the retrieved passages to ensure the model is not overly reliant on a narrow set of information.
- Retrieval Faithfulness: Evaluates how faithfully the retrieved passages represent the underlying knowledge, to ensure the model is not simply memorizing or hallucinating information.
The authors apply these metrics to evaluate several RAG models, including Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks and Incremental Retrieval-Augmented Generation (iRAG). Their experiments provide insights into the strengths and weaknesses of these models, highlighting areas for improvement in retrieval quality.
Critical Analysis
The paper acknowledges that the proposed evaluation metrics are not comprehensive and may not capture all aspects of retrieval quality. For example, the metrics do not directly measure the impact of retrieval on the final generated output, which is the ultimate goal of RAG models. Additionally, the experiments are limited to a few specific RAG models and tasks, so the findings may not generalize to other applications or model architectures.
Further research could explore more holistic evaluation approaches that directly assess the downstream impact of retrieval on generation quality. Investigating the tradeoffs between retrieval relevance, diversity, and faithfulness could also yield valuable insights for designing more robust RAG systems.
Conclusion
This paper introduces new evaluation metrics to assess the retrieval quality in retrieval-augmented generation (RAG) models, which are a type of AI system that combines retrieval and generation. The authors demonstrate the usefulness of these metrics through experiments on popular RAG models, providing insights into their strengths and weaknesses.
The findings from this research can help researchers and practitioners develop more effective RAG models by guiding them in designing better retrieval modules and improving the overall integration of retrieval and generation. As AI-generated content becomes more prevalent, robust evaluation of these systems will be crucial to ensure they are producing high-quality, reliable, and trustworthy information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
0
0
Retrieval-Augmented Generation (RAG) has emerged as a pivotal innovation in natural language processing, enhancing generative models by incorporating external information retrieval. Evaluating RAG systems, however, poses distinct challenges due to their hybrid structure and reliance on dynamic knowledge sources. We consequently enhanced an extensive survey and proposed an analysis framework for benchmarks of RAG systems, RAGR (Retrieval, Generation, Additional Requirement), designed to systematically analyze RAG benchmarks by focusing on measurable outputs and established truths. Specifically, we scrutinize and contrast multiple quantifiable metrics of the Retrieval and Generation component, such as relevance, accuracy, and faithfulness, of the internal links within the current RAG evaluation methods, covering the possible output and ground truth pairs. We also analyze the integration of additional requirements of different works, discuss the limitations of current benchmarks, and propose potential directions for further research to address these shortcomings and advance the field of RAG evaluation. In conclusion, this paper collates the challenges associated with RAG evaluation. It presents a thorough analysis and examination of existing methodologies for RAG benchmark design based on the proposed RGAR framework.
5/14/2024
💬
Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation
Gauthier Guinet, Behrooz Omidvar-Tehrani, Anoop Deoras, Laurent Callot
0
0
We propose a new method to measure the task-specific accuracy of Retrieval-Augmented Large Language Models (RAG). Evaluation is performed by scoring the RAG on an automatically-generated synthetic exam composed of multiple choice questions based on the corpus of documents associated with the task. Our method is an automated, cost-efficient, interpretable, and robust strategy to select the optimal components for a RAG system. We leverage Item Response Theory (IRT) to estimate the quality of an exam and its informativeness on task-specific accuracy. IRT also provides a natural way to iteratively improve the exam by eliminating the exam questions that are not sufficiently informative about a model's ability. We demonstrate our approach on four new open-ended Question-Answering tasks based on Arxiv abstracts, StackExchange questions, AWS DevOps troubleshooting guides, and SEC filings. In addition, our experiments reveal more general insights into factors impacting RAG performance like size, retrieval mechanism, prompting and fine-tuning. Most notably, our findings show that choosing the right retrieval algorithms often leads to bigger performance gains than simply using a larger language model.
5/24/2024
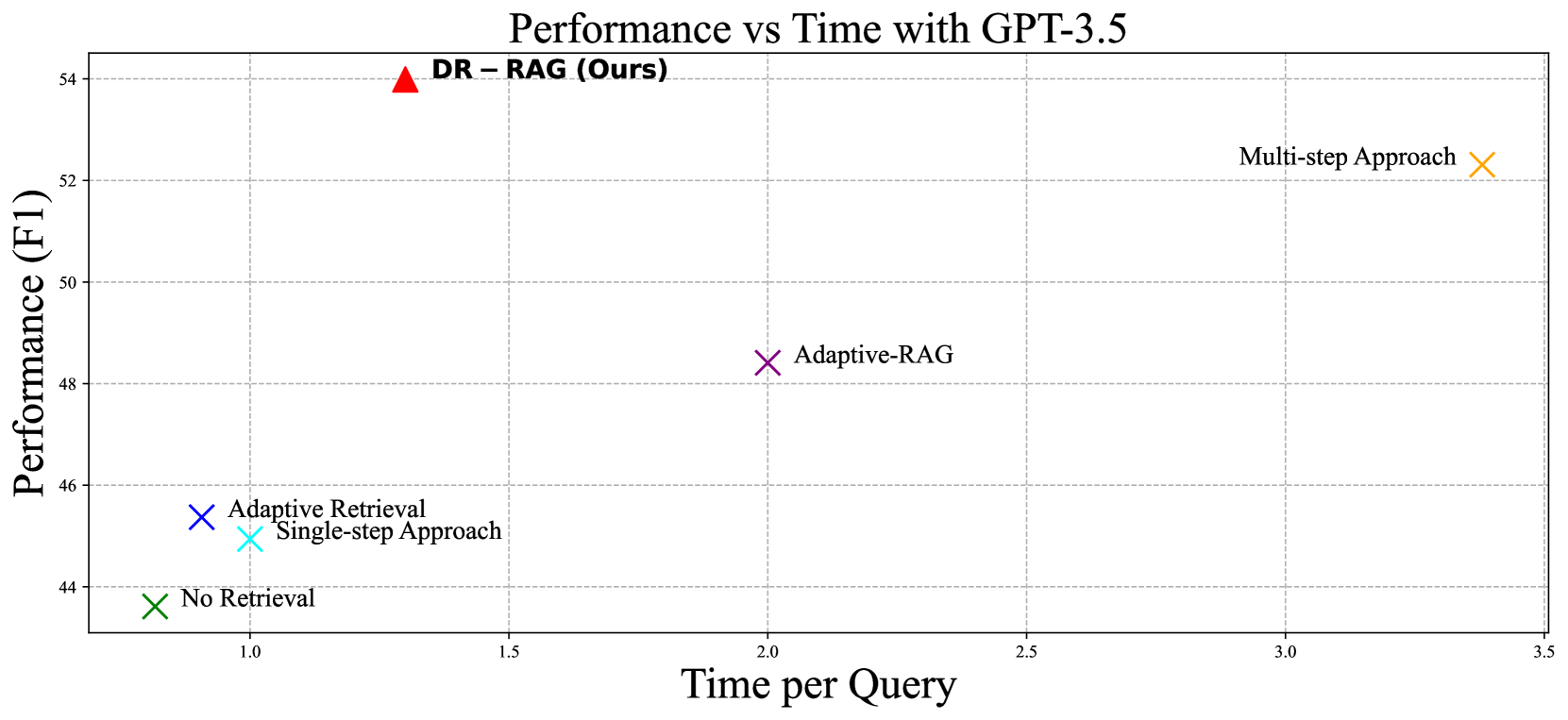
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
0
0
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
6/18/2024
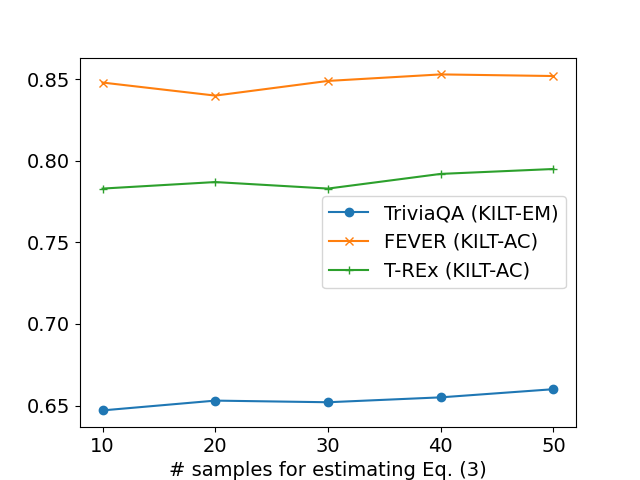
Stochastic RAG: End-to-End Retrieval-Augmented Generation through Expected Utility Maximization
Hamed Zamani, Michael Bendersky
0
0
This paper introduces Stochastic RAG--a novel approach for end-to-end optimization of retrieval-augmented generation (RAG) models that relaxes the simplifying assumptions of marginalization and document independence, made in most prior work. Stochastic RAG casts the retrieval process in RAG as a stochastic sampling without replacement process. Through this formulation, we employ straight-through Gumbel-top-k that provides a differentiable approximation for sampling without replacement and enables effective end-to-end optimization for RAG. We conduct extensive experiments on seven diverse datasets on a wide range of tasks, from open-domain question answering to fact verification to slot-filling for relation extraction and to dialogue systems. By applying this optimization method to a recent and effective RAG model, we advance state-of-the-art results on six out of seven datasets.
5/7/2024