Strategies to Improve Real-World Applicability of Laparoscopic Anatomy Segmentation Models
2403.17192
0
0
👨🏫
Abstract
Accurate identification and localization of anatomical structures of varying size and appearance in laparoscopic imaging are necessary to leverage the potential of computer vision techniques for surgical decision support. Segmentation performance of such models is traditionally reported using metrics of overlap such as IoU. However, imbalanced and unrealistic representation of classes in the training data and suboptimal selection of reported metrics have the potential to skew nominal segmentation performance and thereby ultimately limit clinical translation. In this work, we systematically analyze the impact of class characteristics (i.e., organ size differences), training and test data composition (i.e., representation of positive and negative examples), and modeling parameters (i.e., foreground-to-background class weight) on eight segmentation metrics: accuracy, precision, recall, IoU, F1 score (Dice Similarity Coefficient), specificity, Hausdorff Distance, and Average Symmetric Surface Distance. Our findings support two adjustments to account for data biases in surgical data science: First, training on datasets that are similar to the clinical real-world scenarios in terms of class distribution, and second, class weight adjustments to optimize segmentation model performance with regard to metrics of particular relevance in the respective clinical setting.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Accurate identification and localization of anatomical structures in laparoscopic imaging are crucial for computer vision-based surgical decision support
- Segmentation performance is traditionally measured using overlap metrics like Intersection over Union (IoU)
- However, biases in training data and suboptimal metric selection can skew the reported performance, limiting clinical translation
- This work systematically analyzes the impact of class characteristics, data composition, and modeling parameters on eight segmentation metrics
Plain English Explanation
The paper focuses on the challenge of accurately identifying and locating different anatomical structures in laparoscopic (minimally invasive) surgical images. This is an important task for developing computer vision techniques that can provide decision support to surgeons during operations.
Traditionally, the performance of these segmentation models has been measured using metrics that look at how much the model's predicted regions overlap with the ground truth regions. One common metric is Intersection over Union (IoU), which compares the size of the overlap to the total area covered by both the prediction and the ground truth.
However, the paper argues that biases in the training data and the choice of performance metrics can skew the reported segmentation performance. This can ultimately limit the ability to translate these computer vision models into real-world clinical use.
To address this, the researchers systematically investigated how factors like the size differences between anatomical structures, the balance of positive and negative examples in the training data, and the weighting of foreground and background classes during training affect eight different segmentation metrics. These metrics include not just overlap-based measures like IoU, but also accuracy, precision, recall, and distance-based metrics.
The key takeaways are that training on datasets that better reflect real-world clinical scenarios and adjusting the relative weights of different classes during model training can help optimize performance on the metrics most relevant for the intended clinical application.
Technical Explanation
The paper explores the impact of various factors on the performance of anatomical structure segmentation models in laparoscopic imaging. Traditionally, segmentation performance is reported using overlap-based metrics like Intersection over Union (IoU), which can be skewed by biases in the training data and suboptimal metric selection.
The researchers systematically analyzed the effects of:
- Class characteristics (e.g., differences in organ sizes)
- Training and test data composition (i.e., representation of positive and negative examples)
- Modeling parameters (i.e., foreground-to-background class weight)
on eight segmentation metrics: accuracy, precision, recall, IoU, F1 score (Dice Similarity Coefficient), specificity, Hausdorff Distance, and Average Symmetric Surface Distance.
Their findings suggest two key adjustments to account for data biases in surgical computer vision:
- Training on datasets that better reflect the real-world clinical scenario in terms of class distribution
- Adjusting class weights during model training to optimize performance on clinically relevant metrics
These insights build on previous work in medical image segmentation and medical image translation, and align with research on exploiting structural similarities and using one model for multiple tasks.
Critical Analysis
The paper provides a thorough and systematic analysis of the factors affecting segmentation performance in laparoscopic imaging. By considering a range of segmentation metrics beyond just overlap-based measures, the researchers offer a more nuanced understanding of model behavior.
However, the paper does not delve into the specific clinical implications of optimizing for different metrics. For example, it's not clear how the trade-offs between metrics like precision, recall, and distance-based measures would impact surgical decision-making and patient outcomes.
Additionally, the paper focuses on segmentation performance at the organ level, but does not explore the challenges of accurately localizing smaller anatomical structures (e.g., blood vessels, nerves) that may be equally important for surgical guidance. Further research could investigate the performance of these models on a wider range of clinically relevant anatomical targets.
Finally, while the paper highlights the importance of dataset composition, it does not provide detailed recommendations for how to curate training data that best reflects real-world clinical scenarios. Guidance on effective data collection and annotation strategies would be a valuable addition to this work.
Conclusion
This paper provides important insights into the factors that can skew the reported performance of anatomical structure segmentation models in laparoscopic imaging. By systematically analyzing a range of segmentation metrics, the researchers demonstrate the need to account for biases in training data and carefully select performance measures that align with clinical priorities.
The key takeaways - training on representative datasets and adjusting class weights during model optimization - offer a path forward for developing more clinically translatable computer vision-based surgical decision support systems. Further research is needed to fully bridge the gap between model performance and real-world clinical impact, but this work represents an important step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Segmentation Quality and Volumetric Accuracy in Medical Imaging
Zheyuan Zhang, Ulas Bagci
0
0
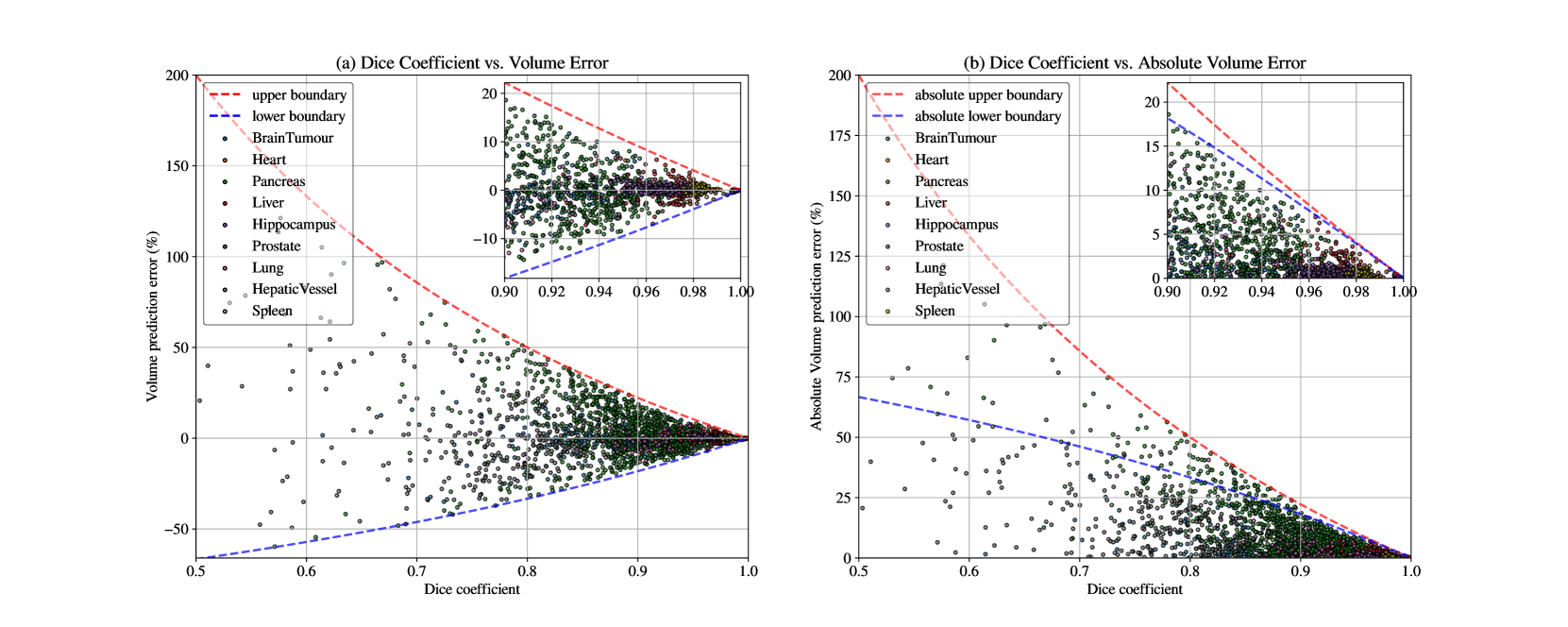
Current medical image segmentation relies on the region-based (Dice, F1-score) and boundary-based (Hausdorff distance, surface distance) metrics as the de-facto standard. While these metrics are widely used, they lack a unified interpretation, particularly regarding volume agreement. Clinicians often lack clear benchmarks to gauge the goodness of segmentation results based on these metrics. Recognizing the clinical relevance of volumetry, we utilize relative volume prediction error (vpe) to directly assess the accuracy of volume predictions derived from segmentation tasks. Our work integrates theoretical analysis and empirical validation across diverse datasets. We delve into the often-ambiguous relationship between segmentation quality (measured by Dice) and volumetric accuracy in clinical practice. Our findings highlight the critical role of incorporating volumetric prediction accuracy into segmentation evaluation. This approach empowers clinicians with a more nuanced understanding of segmentation performance, ultimately improving the interpretation and utility of these metrics in real-world healthcare settings.
5/15/2024
One model to use them all: Training a segmentation model with complementary datasets
Alexander C. Jenke, Sebastian Bodenstedt, Fiona R. Kolbinger, Marius Distler, Jurgen Weitz, Stefanie Speidel
0
0
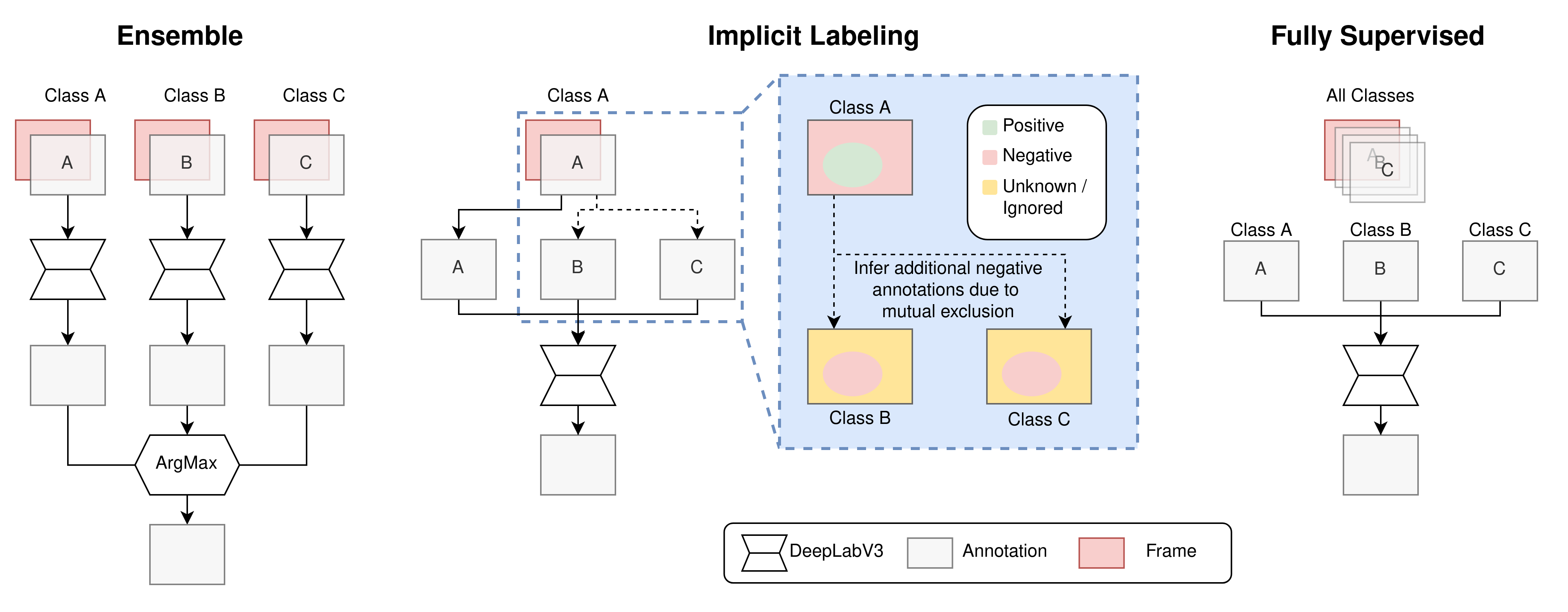
Understanding a surgical scene is crucial for computer-assisted surgery systems to provide any intelligent assistance functionality. One way of achieving this scene understanding is via scene segmentation, where every pixel of a frame is classified and therefore identifies the visible structures and tissues. Progress on fully segmenting surgical scenes has been made using machine learning. However, such models require large amounts of annotated training data, containing examples of all relevant object classes. Such fully annotated datasets are hard to create, as every pixel in a frame needs to be annotated by medical experts and, therefore, are rarely available. In this work, we propose a method to combine multiple partially annotated datasets, which provide complementary annotations, into one model, enabling better scene segmentation and the use of multiple readily available datasets. Our method aims to combine available data with complementary labels by leveraging mutual exclusive properties to maximize information. Specifically, we propose to use positive annotations of other classes as negative samples and to exclude background pixels of binary annotations, as we cannot tell if they contain a class not annotated but predicted by the model. We evaluate our method by training a DeepLabV3 on the publicly available Dresden Surgical Anatomy Dataset, which provides multiple subsets of binary segmented anatomical structures. Our approach successfully combines 6 classes into one model, increasing the overall Dice Score by 4.4% compared to an ensemble of models trained on the classes individually. By including information on multiple classes, we were able to reduce confusion between stomach and colon by 24%. Our results demonstrate the feasibility of training a model on multiple datasets. This paves the way for future work further alleviating the need for one large, fully segmented datasets.
4/8/2024

Real Time Multi Organ Classification on Computed Tomography Images
Halid Ziya Yerebakan, Yoshihisa Shinagawa, Gerardo Hermosillo Valadez
0
0
Organ segmentation is a fundamental task in medical imaging, and it is useful for many clinical automation pipelines. Typically, the process involves segmenting the entire volume, which can be unnecessary when the points of interest are limited. In those cases, a classifier could be used instead of segmentation. However, there is an inherent trade-off between the context size and the speed of classifiers. To address this issue, we propose a new method that employs a data selection strategy with sparse sampling across a wide field of view without image resampling. This sparse sampling strategy makes it possible to classify voxels into multiple organs in real time without using accelerators. Although our method is an independent classifier, it can generate full segmentation by querying grid locations at any resolution. We have compared our method with existing segmentation techniques, demonstrating its potential for superior runtime in practical applications in medical imaging.
4/30/2024

Hierarchical Insights: Exploiting Structural Similarities for Reliable 3D Semantic Segmentation
Mariella Dreissig, Florian Piewak, Joschka Boedecker
0
0
Safety-critical applications like autonomous driving call for robust 3D environment perception algorithms which can withstand highly diverse and ambiguous surroundings. The predictive performance of any classification model strongly depends on the underlying dataset and the prior knowledge conveyed by the annotated labels. While the labels provide a basis for the learning process, they usually fail to represent inherent relations between the classes - representations, which are a natural element of the human perception system. We propose a training strategy which enables a 3D LiDAR semantic segmentation model to learn structural relationships between the different classes through abstraction. We achieve this by implicitly modeling those relationships through a learning rule for hierarchical multi-label classification (HMC). With a detailed analysis we show, how this training strategy not only improves the model's confidence calibration, but also preserves additional information for downstream tasks like fusion, prediction and planning.
4/10/2024