Streaming Anchor Loss: Augmenting Supervision with Temporal Significance

0
Sign in to get full access
Overview
- The research paper discusses a new loss function called "Streaming Anchor Loss" that can be used to improve the performance of machine learning models for temporal tasks.
- The key idea is to incorporate temporal significance into the supervision signal, which can help the model better capture the dynamics of the input data over time.
- The paper presents experiments on various temporal tasks, including video classification and speech recognition, demonstrating the benefits of the proposed approach.
Plain English Explanation
The paper introduces a new technique called "Streaming Anchor Loss" that can be used to train machine learning models for tasks that involve understanding data over time, such as video classification or speech recognition.
The main insight is that traditional training approaches may not be capturing the full temporal significance of the data. For example, in a video classification task, the model may focus too much on individual frames and miss important temporal patterns that span multiple frames.
The Streaming Anchor Loss aims to address this by explicitly incorporating the relative importance of different time points in the input data. The idea is to identify "anchor" points in the data that are particularly informative or significant, and then use this information to guide the training process.
By doing so, the model can learn to better understand the temporal dynamics of the input, which can lead to improved performance on a wide range of tasks that involve processing sequential data, such as predicting highlights in live streams or uncovering temporal information for saliency prediction.
Technical Explanation
The paper first introduces the notation and setup for the problem, defining the input data as a sequence of observations over time, and the goal as learning a model that can accurately predict some output for each time step.
The core of the proposed approach is the Streaming Anchor Loss, which works as follows:
-
Anchor Selection: The method first identifies a set of "anchor" time points in the input sequence that are deemed to be particularly significant or informative. This could be done in various ways, such as by leveraging domain-specific knowledge or using an unsupervised algorithm to detect important time points.
-
Temporal Weighting: The loss function then assigns higher weights to the anchor points, effectively increasing their importance during training. This encourages the model to pay closer attention to these temporally significant parts of the input.
-
Streaming Formulation: To handle streaming data, the method uses a sliding window approach, where the anchor points and temporal weights are dynamically updated as new data arrives.
The paper evaluates the Streaming Anchor Loss on a variety of temporal tasks, including video classification, speech recognition, and speech-enhanced audio-visual learning. The results demonstrate consistent improvements over baseline approaches that do not explicitly model temporal significance.
Critical Analysis
The paper presents a well-designed and thoughtful approach to incorporating temporal significance into the training process for machine learning models. The key strengths of the Streaming Anchor Loss are its conceptual simplicity, its flexibility to be applied to a wide range of temporal tasks, and its empirical demonstrated benefits.
That said, the paper does not address some potential limitations or areas for further research:
-
Anchor Selection: The method relies on identifying informative anchor points in the input data, but the paper does not provide a detailed discussion of how this can be done in practice, especially for domains where the temporal significance may not be obvious.
-
Computational Overhead: The streaming formulation and dynamic updating of the anchor points and weights may introduce additional computational complexity, which could be a concern for real-time or resource-constrained applications.
-
Interpretability: While the Streaming Anchor Loss can improve model performance, it is not clear how the identified anchor points and their relative importance can be interpreted or used to gain further insights about the underlying temporal dynamics of the data.
-
Generalization: The paper focuses on evaluating the approach on a relatively limited set of tasks and datasets. It would be valuable to see how the Streaming Anchor Loss performs on a wider range of temporal problems, especially in more complex or real-world scenarios.
Overall, the Streaming Anchor Loss is a promising approach that could have significant impact on a wide range of temporal machine learning applications. Further research addressing the potential limitations and exploring additional use cases would be valuable for solidifying the contributions of this work.
Conclusion
The Streaming Anchor Loss presented in this paper offers a novel way to incorporate temporal significance into the training of machine learning models for tasks involving sequential data. By explicitly identifying and weighting important time points in the input, the approach can help the model better capture the dynamic patterns and relationships in the data.
The experiments demonstrate the benefits of this approach across various temporal tasks, suggesting that the Streaming Anchor Loss could be a valuable tool for researchers and practitioners working on a wide range of applications, from video analysis to speech recognition. While there are some areas for further exploration, this work represents an important step forward in advancing the state-of-the-art in temporal machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Streaming Anchor Loss: Augmenting Supervision with Temporal Significance
Utkarsh Oggy Sarawgi, John Berkowitz, Vineet Garg, Arnav Kundu, Minsik Cho, Sai Srujana Buddi, Saurabh Adya, Ahmed Tewfik
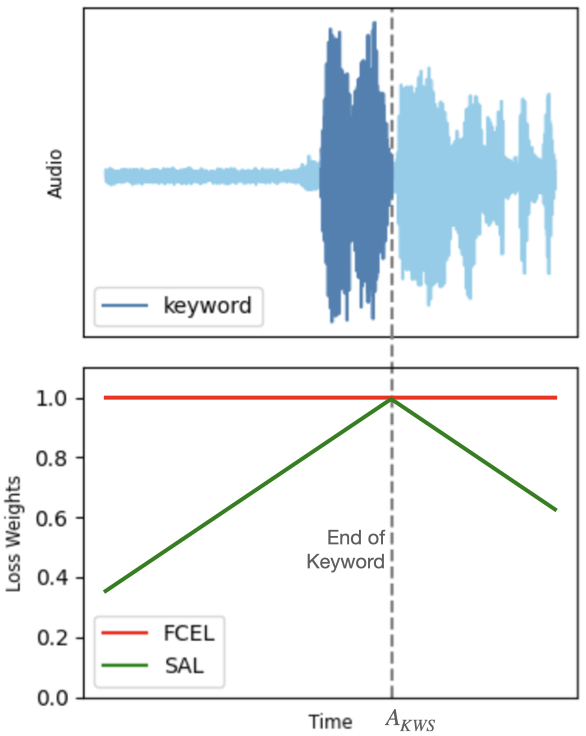
Streaming neural network models for fast frame-wise responses to various speech and sensory signals are widely adopted on resource-constrained platforms. Hence, increasing the learning capacity of such streaming models (i.e., by adding more parameters) to improve the predictive power may not be viable for real-world tasks. In this work, we propose a new loss, Streaming Anchor Loss (SAL), to better utilize the given learning capacity by encouraging the model to learn more from essential frames. More specifically, our SAL and its focal variations dynamically modulate the frame-wise cross entropy loss based on the importance of the corresponding frames so that a higher loss penalty is assigned for frames within the temporal proximity of semantically critical events. Therefore, our loss ensures that the model training focuses on predicting the relatively rare but task-relevant frames. Experimental results with standard lightweight convolutional and recurrent streaming networks on three different speech based detection tasks demonstrate that SAL enables the model to learn the overall task more effectively with improved accuracy and latency, without any additional data, model parameters, or architectural changes.
Read more4/19/2024
0
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, Chao Zhang
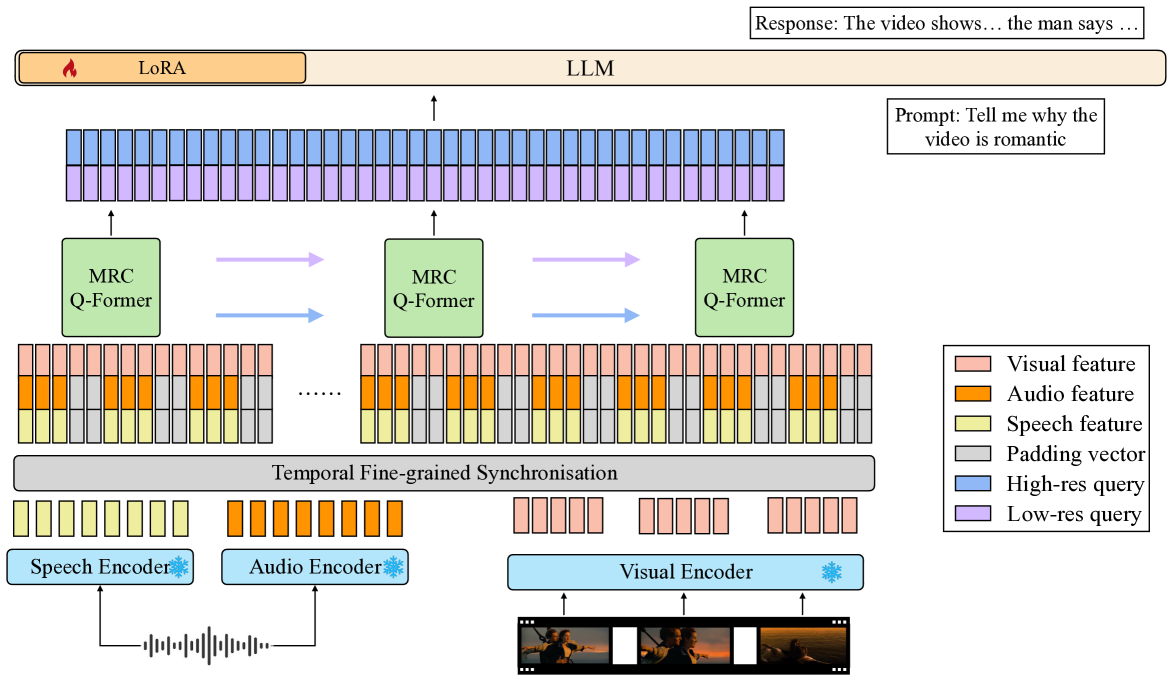
Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25% absolute accuracy improvements on the video-QA task and over 30% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at texttt{url{https://github.com/bytedance/SALMONN/}}.
Read more6/26/2024
🤿
0
TempSAL -- Uncovering Temporal Information for Deep Saliency Prediction
Bahar Aydemir, Ludo Hoffstetter, Tong Zhang, Mathieu Salzmann, Sabine Susstrunk
Deep saliency prediction algorithms complement the object recognition features, they typically rely on additional information, such as scene context, semantic relationships, gaze direction, and object dissimilarity. However, none of these models consider the temporal nature of gaze shifts during image observation. We introduce a novel saliency prediction model that learns to output saliency maps in sequential time intervals by exploiting human temporal attention patterns. Our approach locally modulates the saliency predictions by combining the learned temporal maps. Our experiments show that our method outperforms the state-of-the-art models, including a multi-duration saliency model, on the SALICON benchmark. Our code will be publicly available on GitHub.
Read more9/11/2024
0
STaR: Distilling Speech Temporal Relation for Lightweight Speech Self-Supervised Learning Models
Kangwook Jang, Sungnyun Kim, Hoirin Kim
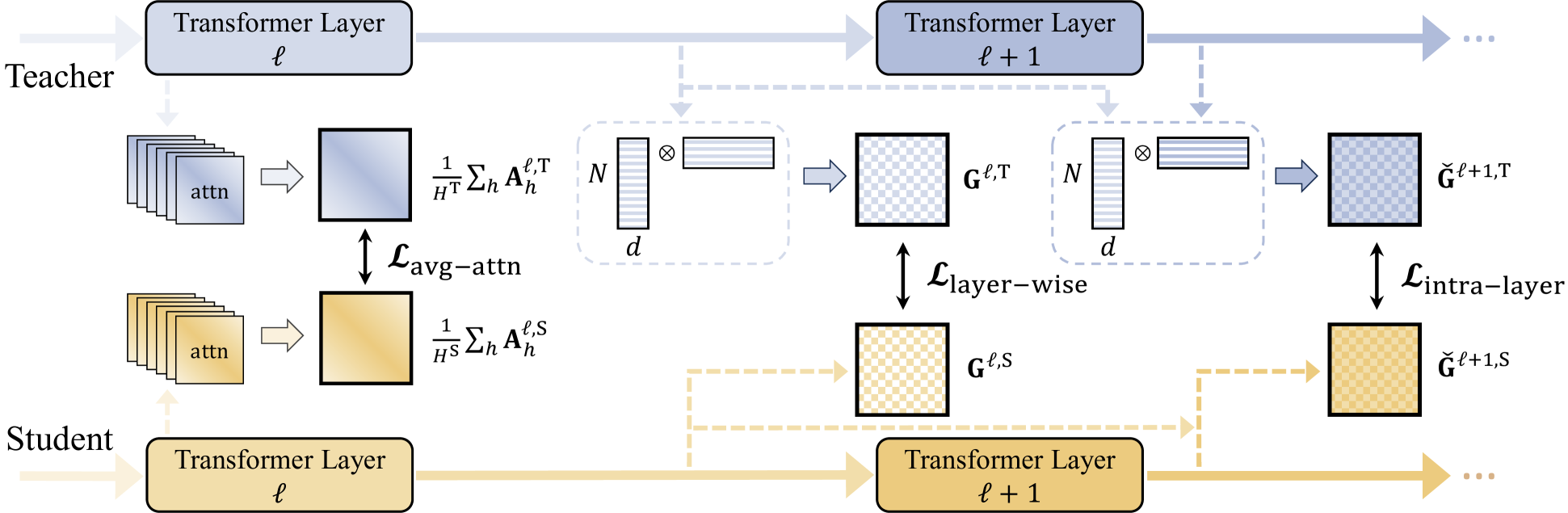
Albeit great performance of Transformer-based speech selfsupervised learning (SSL) models, their large parameter size and computational cost make them unfavorable to utilize. In this study, we propose to compress the speech SSL models by distilling speech temporal relation (STaR). Unlike previous works that directly match the representation for each speech frame, STaR distillation transfers temporal relation between speech frames, which is more suitable for lightweight student with limited capacity. We explore three STaR distillation objectives and select the best combination as the final STaR loss. Our model distilled from HuBERT BASE achieves an overall score of 79.8 on SUPERB benchmark, the best performance among models with up to 27 million parameters. We show that our method is applicable across different speech SSL models and maintains robust performance with further reduced parameters.
Read more4/26/2024