video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models

0
Sign in to get full access
Overview
- This research paper introduces "video-SALMONN", a speech-enhanced audio-visual large language model that aims to enhance language understanding and generation by leveraging both visual and auditory information.
- The model builds upon previous work on video-LLAMA and SALMONN, combining audio and video inputs to create a more comprehensive language understanding system.
- The authors demonstrate the model's capabilities on various tasks, including video description generation, question answering, and audio-visual speech recognition.
Plain English Explanation
The researchers have developed a new artificial intelligence (AI) system called "video-SALMONN" that is designed to understand and generate language by using both visual and auditory information. This is an advancement over previous language models that only used text or a single type of input.
By combining video and audio data, the video-SALMONN model can gain a more holistic understanding of language and the world. For example, when processing a sentence about a person speaking, the model can use the video of the person's mouth movements and the audio of their voice to better comprehend what is being said.
The researchers tested video-SALMONN on several tasks, such as generating descriptions of videos, answering questions about video content, and recognizing speech in audio-visual recordings. The results show that this multimodal approach can improve the model's performance compared to using just text, audio, or video alone.
This research represents an important step towards building AI systems that can understand and interact with the world in more human-like ways, by integrating information from multiple senses just as humans do. As language models become more advanced, incorporating visual and auditory inputs could lead to significant improvements in their language understanding and generation capabilities.
Technical Explanation
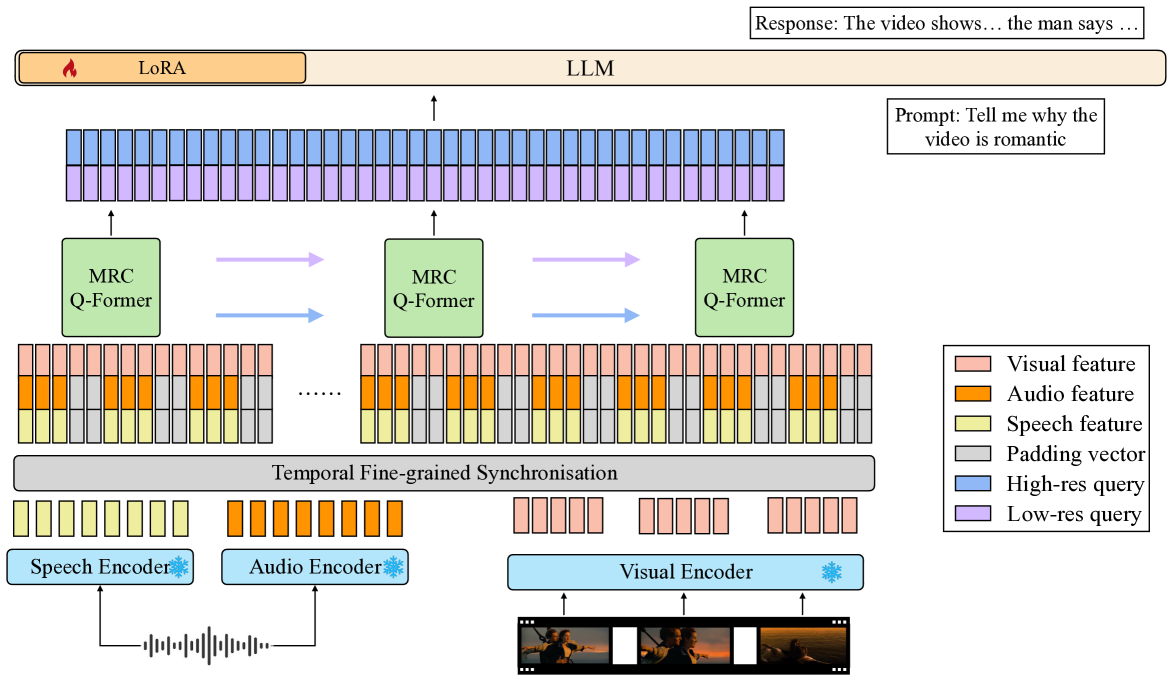
The core of the video-SALMONN architecture is built upon two previous models: video-LLAMA, which focuses on spatial-temporal modeling of audio-visual data, and SALMONN, which aims to endow large language models with generic hearing abilities.
The video-SALMONN model takes both video and audio inputs, which are processed through separate encoder networks to extract relevant features. These features are then combined and fed into a transformer-based language model to generate text outputs. The authors also incorporate a speaker diarization module to identify who is speaking in the input video.
The model is trained on a diverse dataset of audio-visual data, including videos from MSRVTT, HowTo100M, and LibriSpeech. The researchers fine-tune the pre-trained model on various downstream tasks, such as video captioning, audio-visual question answering, and multilingual audio-visual speech recognition.
The results demonstrate that the video-SALMONN model outperforms text-only and audio-only baselines on these tasks, highlighting the benefits of integrating visual and auditory information for language understanding. The authors also present experiments on semantically consistent video-to-audio generation, showcasing the model's ability to generate plausible audio outputs that match the visual content.
Critical Analysis
The video-SALMONN research represents a promising step towards building more comprehensive and multimodal language models. By leveraging both visual and auditory inputs, the model can gain a richer understanding of language and the world, which could lead to significant performance improvements on a variety of tasks.
However, the paper does not address several important limitations and potential concerns. For example, the model's reliance on high-quality audio-visual data may limit its applicability in real-world scenarios with noisy or incomplete inputs. Additionally, the authors do not discuss the model's performance on minority languages or the potential for biases and fairness issues that can arise in such large-scale language models.
Furthermore, the authors do not provide a detailed analysis of the model's internal workings or the specific mechanisms by which the audio and visual features are integrated and leveraged for language understanding. A more in-depth exploration of these technical details could help the research community better understand the model's strengths, weaknesses, and potential areas for improvement.
Despite these limitations, the video-SALMONN research represents an important step towards building more robust and versatile language models. As the field of multimodal AI continues to evolve, it will be crucial for researchers to address these challenges and explore the ethical implications of these technologies.
Conclusion
The video-SALMONN paper presents a novel approach to language modeling that integrates visual and auditory information to enhance language understanding and generation. By building on previous work on video-LLAMA and SALMONN, the researchers have developed a powerful model that outperforms text-only and audio-only baselines on various tasks.
This research represents a significant advancement in the field of multimodal AI, demonstrating the benefits of combining different modalities for more comprehensive and robust language processing. As language models become increasingly prevalent in our daily lives, incorporating visual and auditory inputs could lead to more natural and intuitive interactions, with potential applications in areas like virtual assistants, language learning, and accessibility.
While the paper highlights the potential of video-SALMONN, it also raises important questions and limitations that warrant further exploration. As the field of multimodal AI continues to evolve, it will be crucial for researchers to address these challenges and ensure that these technologies are developed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, Chao Zhang
Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25% absolute accuracy improvements on the video-QA task and over 30% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at texttt{url{https://github.com/bytedance/SALMONN/}}.
Read more6/26/2024
1
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang
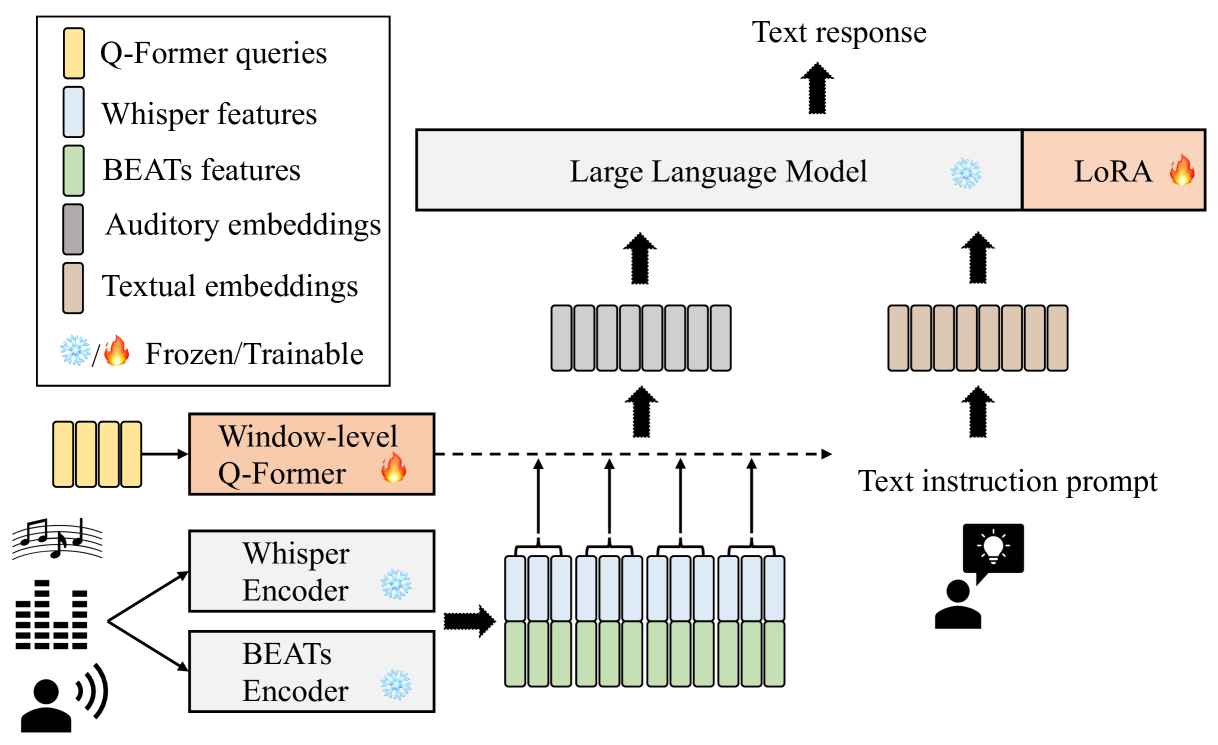
Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning etc. SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning etc. The presence of cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. The source code, model checkpoints and data are available at https://github.com/bytedance/SALMONN.
Read more4/9/2024

0
Large Language Models Are Strong Audio-Visual Speech Recognition Learners
Umberto Cappellazzo, Minsu Kim, Honglie Chen, Pingchuan Ma, Stavros Petridis, Daniele Falavigna, Alessio Brutti, Maja Pantic
Multimodal large language models (MLLMs) have recently become a focal point of research due to their formidable multimodal understanding capabilities. For example, in the audio and speech domains, an LLM can be equipped with (automatic) speech recognition (ASR) abilities by just concatenating the audio tokens, computed with an audio encoder, and the text tokens to achieve state-of-the-art results. On the contrary, tasks like visual and audio-visual speech recognition (VSR/AVSR), which also exploit noise-invariant lip movement information, have received little or no attention. To bridge this gap, we propose Llama-AVSR, a new MLLM with strong audio-visual speech recognition capabilities. It leverages pre-trained audio and video encoders to produce modality-specific tokens which, together with the text tokens, are processed by a pre-trained LLM (e.g., Llama3.1-8B) to yield the resulting response in an auto-regressive fashion. Llama-AVSR requires a small number of trainable parameters as only modality-specific projectors and LoRA modules are trained whereas the multi-modal encoders and LLM are kept frozen. We evaluate our proposed approach on LRS3, the largest public AVSR benchmark, and we achieve new state-of-the-art results for the tasks of ASR and AVSR with a WER of 0.81% and 0.77%, respectively. To bolster our results, we investigate the key factors that underpin the effectiveness of Llama-AVSR: the choice of the pre-trained encoders and LLM, the efficient integration of LoRA modules, and the optimal performance-efficiency trade-off obtained via modality-aware compression rates.
Read more9/20/2024
0
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Siyin Wang, Wenyi Yu, Yudong Yang, Changli Tang, Yixuan Li, Jimin Zhuang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Chao Zhang
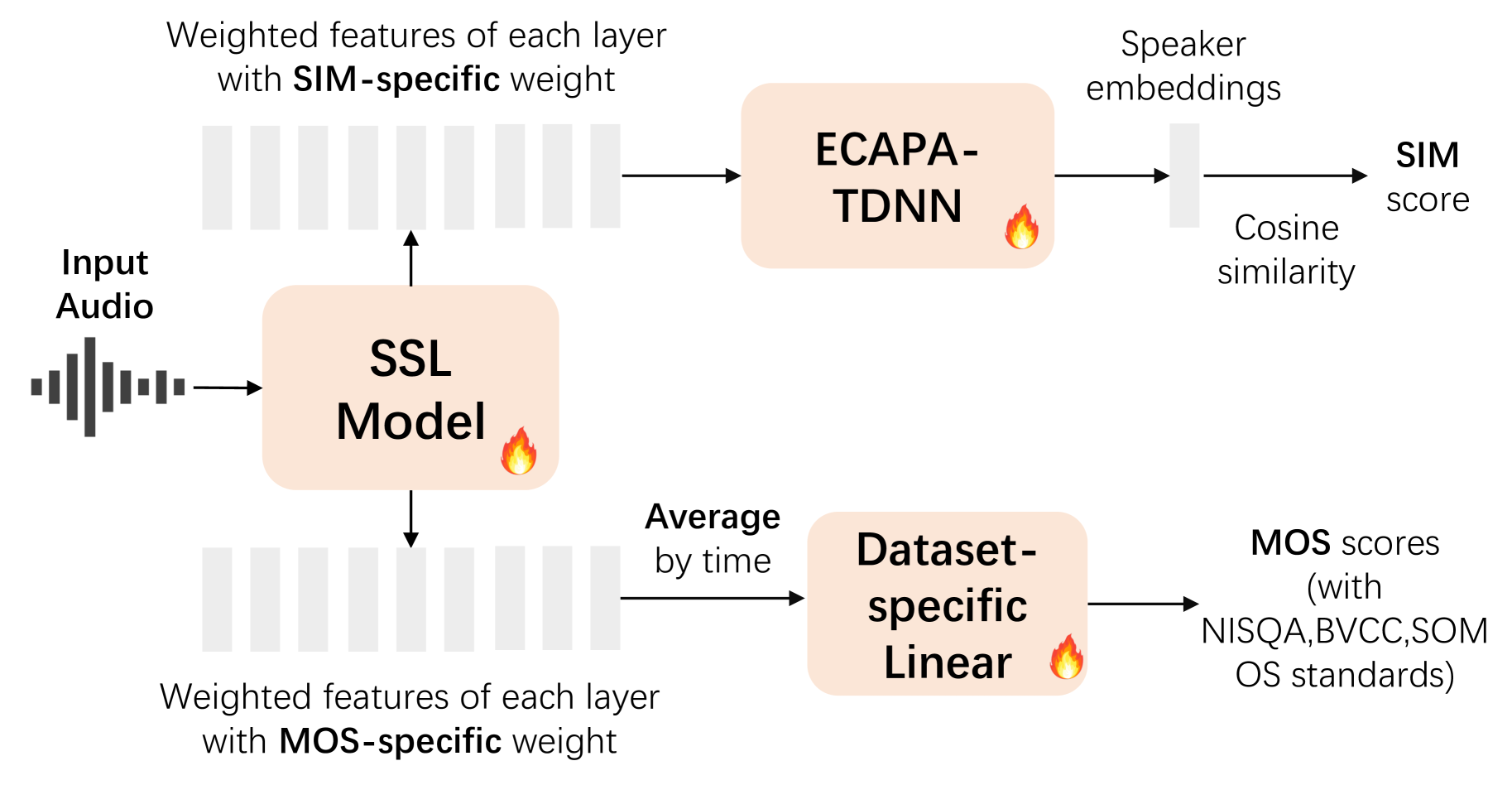
Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.
Read more9/26/2024