STT: Stateful Tracking with Transformers for Autonomous Driving

0

Sign in to get full access
Overview
- This paper introduces a novel object tracking method called "Stateful Tracking with Transformers" (STT) for autonomous driving applications.
- The proposed approach leverages the power of transformers to model complex object interactions and maintain a persistent state throughout the tracking process.
- The authors demonstrate the effectiveness of STT on several benchmark datasets, showing improvements over existing tracking methods.
Plain English Explanation
Object tracking is a crucial component of autonomous driving systems, as it allows vehicles to understand and predict the movements of surrounding objects, such as other cars, pedestrians, and bicycles. Traditional tracking methods often struggle to maintain accurate object identities over time, particularly in complex and dynamic environments.
The researchers behind this paper have developed a new approach called Stateful Tracking with Transformers (STT) that aims to address these challenges. The key idea is to use transformers, a type of neural network architecture that has shown great success in tasks like natural language processing, to model the complex interactions between objects and maintain a persistent state of their identities over time.
In essence, the STT method works by continuously updating a "state" representation for each tracked object, which encodes its current position, velocity, and other relevant features. As new sensor data comes in, the transformer model analyzes the relationships between all the tracked objects and updates their states accordingly. This allows the system to more accurately follow and distinguish between different objects, even as they move, occlude each other, or undergo other changes.
The researchers have evaluated STT on several benchmark datasets for object tracking in autonomous driving scenarios, and the results demonstrate significant improvements over existing tracking methods. This suggests that the transformer-based approach is a promising direction for improving the robustness and accuracy of object tracking in self-driving cars and other autonomous systems.
Technical Explanation
The STT approach (link to "Tracking Transforming Objects: A Benchmark") builds on the idea of using transformers to model complex object interactions and maintain a persistent state. Unlike traditional tracking methods that rely on heuristic rules or simple appearance models, STT uses a transformer-based architecture to dynamically update the state of each tracked object based on its interactions with other objects in the scene.
At the core of STT is a <b>Stateful Transformer</b> module, which takes in the current observations of all tracked objects and outputs updated state representations. The transformer leverages <b>self-attention</b> mechanisms to capture the pairwise relationships between objects, allowing it to reason about occlusions, object splits/merges, and other complex scenarios. The updated state vectors are then used to predict the future locations of each object, which are fed back into the transformer for the next iteration of tracking.
The authors also introduce several other innovations, such as a <b>Spatial-Temporal Selective State Space</b> (link to "ST-SSMS: Spatial-Temporal Selective State Space") module to efficiently represent the state of each object, and a <b>Transformation-Aware Multi-scale Video</b> (link to "TAM-VT: Transformation-Aware Multi-scale Video") encoder to capture multi-scale visual features.
The authors evaluate STT on several benchmark datasets for object tracking in autonomous driving, including KITTI, MOT17, and their own newly introduced TOT dataset. The results demonstrate that STT outperforms state-of-the-art tracking methods, particularly in challenging scenarios with occlusions, object interactions, and dynamic scenes.
Critical Analysis
The STT approach represents a promising advancement in object tracking for autonomous driving, leveraging the powerful modeling capabilities of transformers to handle complex object interactions and maintain persistent object identities. The authors have made several technical innovations, such as the Stateful Transformer module and the Spatial-Temporal Selective State Space representation, which contribute to the improved tracking performance.
However, the paper does not provide a comprehensive analysis of the computational and memory costs of the STT method, which could be a potential concern for real-time deployments in autonomous vehicles. Additionally, the authors primarily evaluate STT on datasets focused on autonomous driving scenarios, so it would be valuable to see how well the method generalizes to other tracking domains, such as surveillance or robotics applications.
Furthermore, the paper does not delve deeply into the limitations of the STT approach or potential failure cases. It would be helpful for the authors to discuss scenarios where the method may struggle, such as in highly crowded or occluded environments, or with objects that exhibit complex, unpredictable movements.
Overall, the STT method represents a significant advancement in object tracking for autonomous driving, and the authors have demonstrated its effectiveness on several benchmark datasets. However, further research is needed to fully understand the method's capabilities, limitations, and practical implications for real-world deployment.
Conclusion
The Stateful Tracking with Transformers (STT) method introduced in this paper presents a novel approach to object tracking for autonomous driving applications. By leveraging the power of transformers to model complex object interactions and maintain persistent object states, STT has shown improved performance over existing tracking methods on several benchmark datasets.
The key innovations of the STT method, such as the Stateful Transformer module and the Spatial-Temporal Selective State Space representation, contribute to its ability to accurately track objects even in challenging scenarios with occlusions, object interactions, and dynamic scenes. This work represents a promising step forward in enhancing the robustness and reliability of object tracking systems for self-driving cars and other autonomous systems.
While the paper demonstrates the effectiveness of the STT method, further research is needed to fully understand its practical implications, including its computational and memory requirements, as well as its generalization to a wider range of tracking domains beyond autonomous driving. Nevertheless, this research highlights the potential of transformer-based approaches to advance the state of the art in object tracking and contribute to the development of safer and more capable autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STT: Stateful Tracking with Transformers for Autonomous Driving
Longlong Jing, Ruichi Yu, Xu Chen, Zhengli Zhao, Shiwei Sheng, Colin Graber, Qi Chen, Qinru Li, Shangxuan Wu, Han Deng, Sangjin Lee, Chris Sweeney, Qiurui He, Wei-Chih Hung, Tong He, Xingyi Zhou, Farshid Moussavi, Zijian Guo, Yin Zhou, Mingxing Tan, Weilong Yang, Congcong Li
Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
Read more5/2/2024
0
Motion State: A New Benchmark Multiple Object Tracking
Yang Feng, Liao Pan, Wu Di, Liu Bo, Zhang Xingle
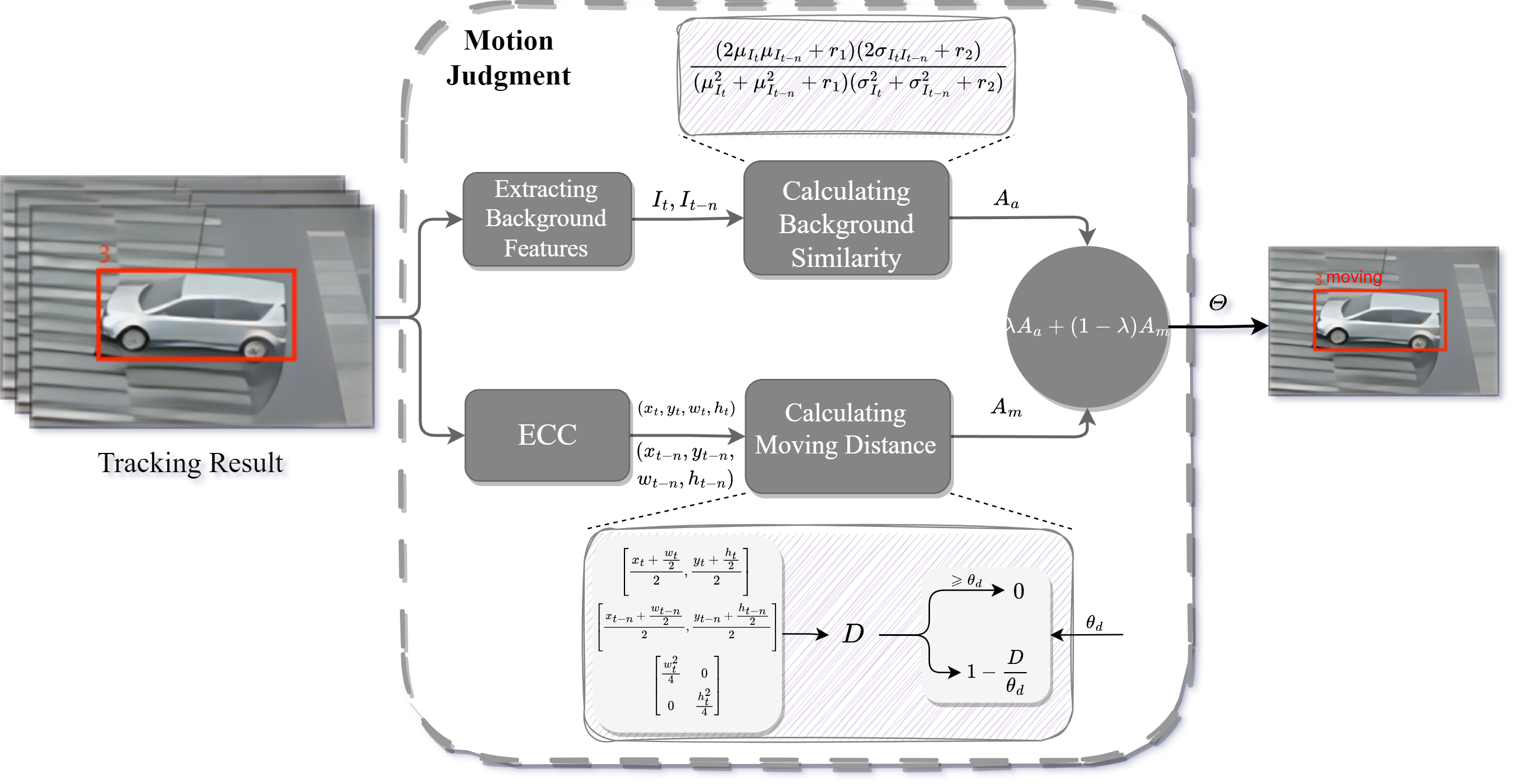
In the realm of video analysis, the field of multiple object tracking (MOT) assumes paramount importance, with the motion state of objects-whether static or dynamic relative to the ground-holding practical significance across diverse scenarios. However, the extant literature exhibits a notable dearth in the exploration of this aspect. Deep learning methodologies encounter challenges in accurately discerning object motion states, while conventional approaches reliant on comprehensive mathematical modeling may yield suboptimal tracking accuracy. To address these challenges, we introduce a Model-Data-Driven Motion State Judgment Object Tracking Method (MoD2T). This innovative architecture adeptly amalgamates traditional mathematical modeling with deep learning-based multi-object tracking frameworks. The integration of mathematical modeling and deep learning within MoD2T enhances the precision of object motion state determination, thereby elevating tracking accuracy. Our empirical investigations comprehensively validate the efficacy of MoD2T across varied scenarios, encompassing unmanned aerial vehicle surveillance and street-level tracking. Furthermore, to gauge the method's adeptness in discerning object motion states, we introduce the Motion State Validation F1 (MVF1) metric. This novel performance metric aims to quantitatively assess the accuracy of motion state classification, furnishing a comprehensive evaluation of MoD2T's performance. Elaborate experimental validations corroborate the rationality of MVF1. In order to holistically appraise MoD2T's performance, we meticulously annotate several renowned datasets and subject MoD2T to stringent testing. Remarkably, under conditions characterized by minimal or moderate camera motion, the achieved MVF1 values are particularly noteworthy, with exemplars including 0.774 for the KITTI dataset, 0.521 for MOT17, and 0.827 for UAVDT.
Read more5/8/2024

0
MambaTrack: A Simple Baseline for Multiple Object Tracking with State Space Model
Changcheng Xiao, Qiong Cao, Zhigang Luo, Long Lan
Tracking by detection has been the prevailing paradigm in the field of Multi-object Tracking (MOT). These methods typically rely on the Kalman Filter to estimate the future locations of objects, assuming linear object motion. However, they fall short when tracking objects exhibiting nonlinear and diverse motion in scenarios like dancing and sports. In addition, there has been limited focus on utilizing learning-based motion predictors in MOT. To address these challenges, we resort to exploring data-driven motion prediction methods. Inspired by the great expectation of state space models (SSMs), such as Mamba, in long-term sequence modeling with near-linear complexity, we introduce a Mamba-based motion model named Mamba moTion Predictor (MTP). MTP is designed to model the complex motion patterns of objects like dancers and athletes. Specifically, MTP takes the spatial-temporal location dynamics of objects as input, captures the motion pattern using a bi-Mamba encoding layer, and predicts the next motion. In real-world scenarios, objects may be missed due to occlusion or motion blur, leading to premature termination of their trajectories. To tackle this challenge, we further expand the application of MTP. We employ it in an autoregressive way to compensate for missing observations by utilizing its own predictions as inputs, thereby contributing to more consistent trajectories. Our proposed tracker, MambaTrack, demonstrates advanced performance on benchmarks such as Dancetrack and SportsMOT, which are characterized by complex motion and severe occlusion.
Read more8/20/2024

0
TrackSSM: A General Motion Predictor by State-Space Model
Bin Hu, Run Luo, Zelin Liu, Cheng Wang, Wenyu Liu
Temporal motion modeling has always been a key component in multiple object tracking (MOT) which can ensure smooth trajectory movement and provide accurate positional information to enhance association precision. However, current motion models struggle to be both efficient and effective across different application scenarios. To this end, we propose TrackSSM inspired by the recently popular state space models (SSM), a unified encoder-decoder motion framework that uses data-dependent state space model to perform temporal motion of trajectories. Specifically, we propose Flow-SSM, a module that utilizes the position and motion information from historical trajectories to guide the temporal state transition of object bounding boxes. Based on Flow-SSM, we design a flow decoder. It is composed of a cascaded motion decoding module employing Flow-SSM, which can use the encoded flow information to complete the temporal position prediction of trajectories. Additionally, we propose a Step-by-Step Linear (S$^2$L) training strategy. By performing linear interpolation between the positions of the object in the previous frame and the current frame, we construct the pseudo labels of step-by-step linear training, ensuring that the trajectory flow information can better guide the object bounding box in completing temporal transitions. TrackSSM utilizes a simple Mamba-Block to build a motion encoder for historical trajectories, forming a temporal motion model with an encoder-decoder structure in conjunction with the flow decoder. TrackSSM is applicable to various tracking scenarios and achieves excellent tracking performance across multiple benchmarks, further extending the potential of SSM-like temporal motion models in multi-object tracking tasks. Code and models are publicly available at url{https://github.com/Xavier-Lin/TrackSSM}.
Read more9/11/2024