StyleTTS-ZS: Efficient High-Quality Zero-Shot Text-to-Speech Synthesis with Distilled Time-Varying Style Diffusion

0

Sign in to get full access
Overview
- Efficient high-quality zero-shot text-to-speech (TTS) synthesis with distilled time-varying style diffusion
- Addresses challenges of existing zero-shot TTS models, such as quality, efficiency, and flexibility
- Proposes a novel TTS framework called StyleTTS-ZS that achieves state-of-the-art performance
Plain English Explanation
[object Object] is a text-to-speech (TTS) system that can generate high-quality speech in a wide range of styles, even for voices it hasn't been trained on before. This is known as "zero-shot" TTS.
The key innovation in StyleTTS-ZS is the use of "time-varying style diffusion." This allows the model to learn how a speaker's voice changes over time, capturing nuances like pitch, tone, and rhythm. By distilling this learned knowledge, StyleTTS-ZS can efficiently apply these styles to generate natural-sounding speech for new voices.
Compared to other zero-shot TTS models, StyleTTS-ZS produces higher-quality audio that sounds more natural and expressive. It's also more efficient, requiring less computational power and memory. This makes it suitable for practical applications like virtual assistants, audiobook narration, and language learning tools.
Technical Explanation
[object Object] introduces a novel TTS framework that addresses the limitations of existing zero-shot TTS models. The key innovations include:
-
Time-Varying Style Diffusion: The model learns to capture the time-varying characteristics of a speaker's voice, such as pitch, tone, and rhythm, using a diffusion-based approach. This allows for more natural and expressive speech synthesis.
-
Distillation-based Zero-Shot Adaptation: The time-varying style knowledge learned by the model is distilled into a compact representation, enabling efficient zero-shot adaptation to new voices without retraining the entire model.
-
Hierarchical Latent Representation: The architecture includes a hierarchical latent representation, which helps to disentangle the content and style information, further improving the quality and flexibility of the zero-shot TTS.
Extensive experiments demonstrate that StyleTTS-ZS outperforms state-of-the-art zero-shot TTS models in terms of speech quality, as measured by objective metrics and human evaluations. The model also exhibits improved efficiency, requiring less computational resources and memory compared to previous approaches.
Critical Analysis
The paper makes a compelling case for the advantages of StyleTTS-ZS over existing zero-shot TTS models. However, some potential limitations and areas for further research are worth considering:
-
Evaluation Scope: The paper focuses on evaluating speech quality, but it does not explore other crucial aspects, such as the model's ability to preserve the speaker's identity or handle different languages and accents.
-
Scalability: While the distillation-based approach improves efficiency, the paper does not address the scalability of the model as the number of target voices increases. Strategies for managing a large number of voice styles may need to be explored.
-
Interpretability: The hierarchical latent representation and diffusion-based modeling approach may introduce complexity that makes the inner workings of the model less interpretable. Investigating ways to improve the model's interpretability could enhance trust and explainability.
-
Real-World Deployment: The paper evaluates the model on standard TTS benchmarks, but the performance in real-world, noisy environments with diverse speaker characteristics may require further investigation.
Conclusion
[object Object] presents a significant advancement in zero-shot TTS synthesis, addressing key limitations of existing approaches. By leveraging time-varying style diffusion and distillation-based adaptation, the model achieves state-of-the-art performance in terms of speech quality and efficiency.
The implications of this work are far-reaching, as it paves the way for more accessible and versatile text-to-speech applications, enabling seamless integration of synthetic voices in various domains, from virtual assistants to audiobook narration. As the research in this area continues to evolve, further exploration of scalability, interpretability, and real-world deployment will be crucial to unlocking the full potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!StyleTTS-ZS: Efficient High-Quality Zero-Shot Text-to-Speech Synthesis with Distilled Time-Varying Style Diffusion
Yinghao Aaron Li, Xilin Jiang, Cong Han, Nima Mesgarani
The rapid development of large-scale text-to-speech (TTS) models has led to significant advancements in modeling diverse speaker prosody and voices. However, these models often face issues such as slow inference speeds, reliance on complex pre-trained neural codec representations, and difficulties in achieving naturalness and high similarity to reference speakers. To address these challenges, this work introduces StyleTTS-ZS, an efficient zero-shot TTS model that leverages distilled time-varying style diffusion to capture diverse speaker identities and prosodies. We propose a novel approach that represents human speech using input text and fixed-length time-varying discrete style codes to capture diverse prosodic variations, trained adversarially with multi-modal discriminators. A diffusion model is then built to sample this time-varying style code for efficient latent diffusion. Using classifier-free guidance, StyleTTS-ZS achieves high similarity to the reference speaker in the style diffusion process. Furthermore, to expedite sampling, the style diffusion model is distilled with perceptual loss using only 10k samples, maintaining speech quality and similarity while reducing inference speed by 90%. Our model surpasses previous state-of-the-art large-scale zero-shot TTS models in both naturalness and similarity, offering a 10-20 faster sampling speed, making it an attractive alternative for efficient large-scale zero-shot TTS systems. The audio demo, code and models are available at https://styletts-zs.github.io/.
Read more9/17/2024
0
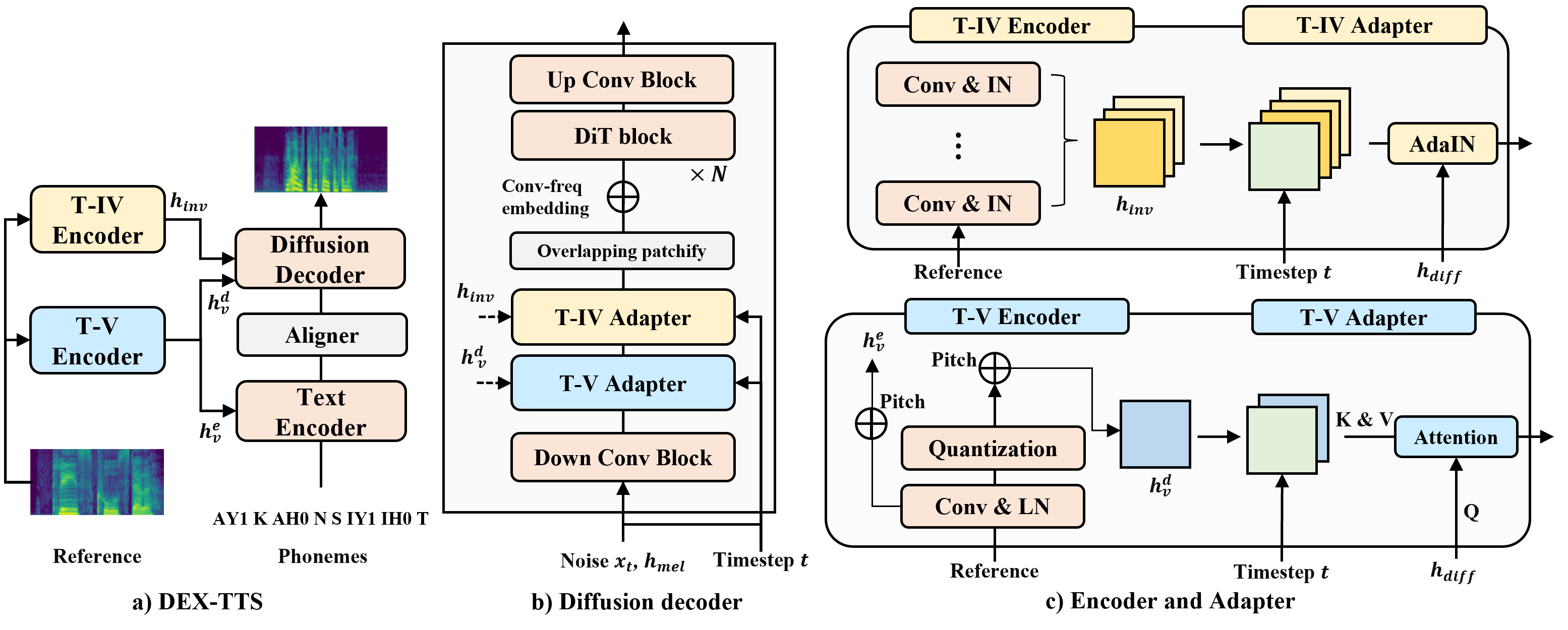
DEX-TTS: Diffusion-based EXpressive Text-to-Speech with Style Modeling on Time Variability
Hyun Joon Park, Jin Sob Kim, Wooseok Shin, Sung Won Han
Expressive Text-to-Speech (TTS) using reference speech has been studied extensively to synthesize natural speech, but there are limitations to obtaining well-represented styles and improving model generalization ability. In this study, we present Diffusion-based EXpressive TTS (DEX-TTS), an acoustic model designed for reference-based speech synthesis with enhanced style representations. Based on a general diffusion TTS framework, DEX-TTS includes encoders and adapters to handle styles extracted from reference speech. Key innovations contain the differentiation of styles into time-invariant and time-variant categories for effective style extraction, as well as the design of encoders and adapters with high generalization ability. In addition, we introduce overlapping patchify and convolution-frequency patch embedding strategies to improve DiT-based diffusion networks for TTS. DEX-TTS yields outstanding performance in terms of objective and subjective evaluation in English multi-speaker and emotional multi-speaker datasets, without relying on pre-training strategies. Lastly, the comparison results for the general TTS on a single-speaker dataset verify the effectiveness of our enhanced diffusion backbone. Demos are available here.
Read more6/28/2024

19
DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
Read more6/18/2024
2
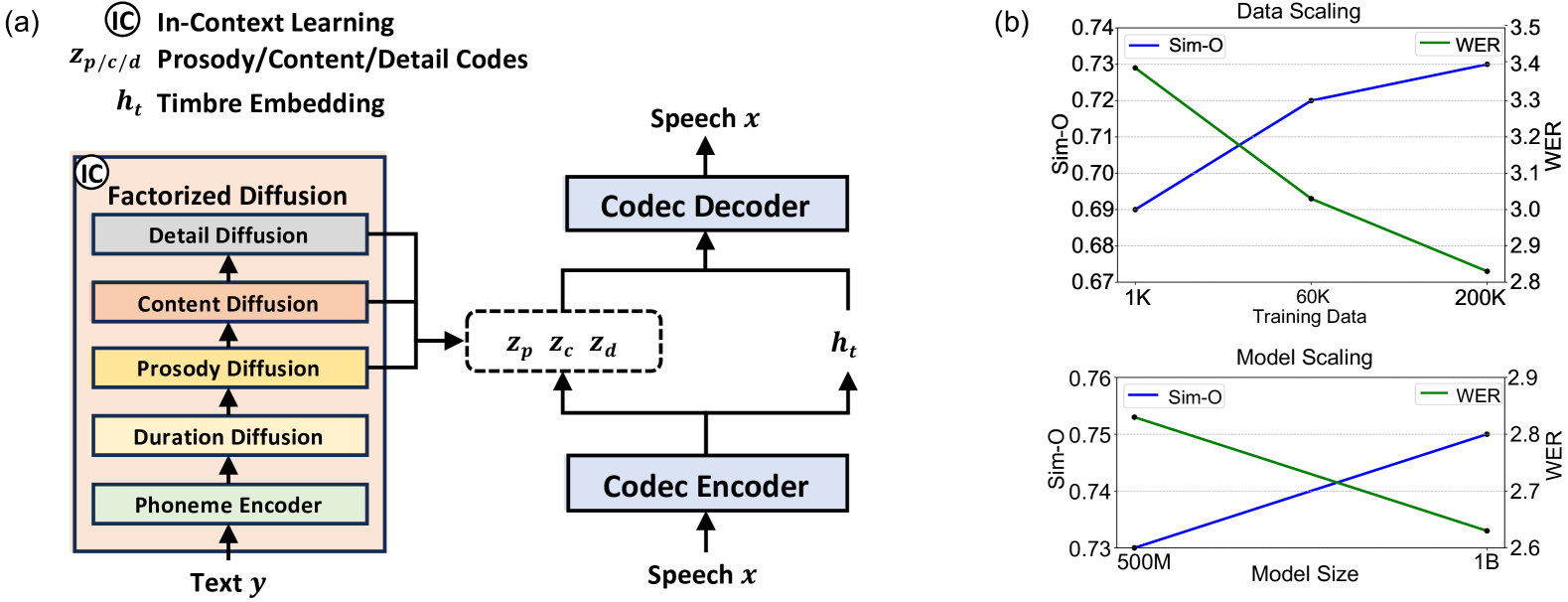
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiang-Yang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, Sheng Zhao
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility, and achieves on-par quality with human recordings. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
Read more4/24/2024