Sublinear Regret for An Actor-Critic Algorithm in Continuous-Time Linear-Quadratic Reinforcement Learning

0
Sign in to get full access
Overview
- This research paper proposes a sublinear regret actor-critic algorithm for continuous-time linear-quadratic reinforcement learning.
- The algorithm is proven to achieve sublinear regret, meaning its performance approaches the optimal policy as the learning time increases.
- The paper provides theoretical analysis and numerical experiments to demonstrate the algorithm's effectiveness.
Plain English Explanation
The paper introduces an actor-critic algorithm for a type of reinforcement learning problem called continuous-time linear-quadratic control. In this problem, an agent tries to learn the best way to control a system over time, where the dynamics of the system are linear and the goal is to minimize a quadratic cost function.
The key idea is to design an algorithm that can learn the optimal control policy while ensuring its performance gets closer and closer to the true optimal policy as more time passes. This is captured by the concept of "sublinear regret," which means the difference between the algorithm's cumulative cost and the optimal cumulative cost grows at a sublinear rate over time.
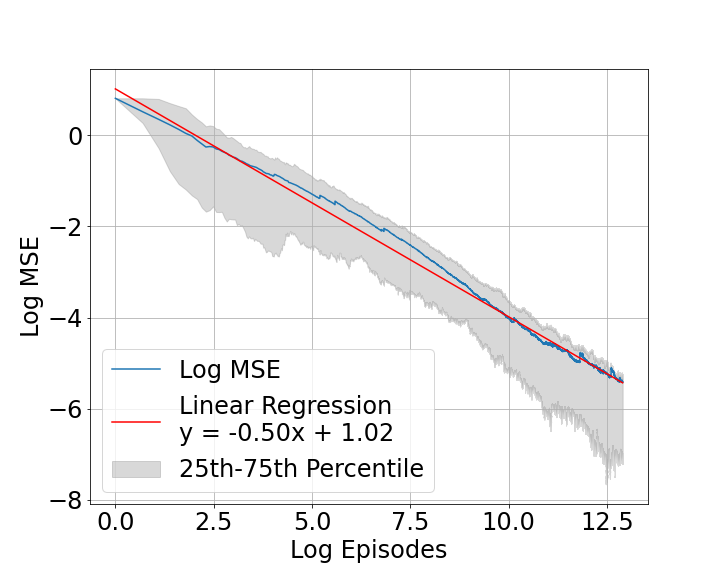
The paper provides a detailed theoretical analysis to prove that the proposed actor-critic algorithm achieves sublinear regret. It also includes numerical experiments that demonstrate the algorithm's effectiveness in practice. The results show that the algorithm can learn near-optimal control policies efficiently, even in complex continuous-time settings.
Technical Explanation
The paper presents an actor-critic algorithm for continuous-time linear-quadratic reinforcement learning. The algorithm consists of two main components:
- The actor component learns the optimal control policy by updating the policy parameters based on the current state and value function estimate.
- The critic component learns the value function by updating its parameters to approximate the true value function.
The key technical contribution is the design of the update rules for the actor and critic, which are proven to achieve sublinear regret. This means that as the learning time increases, the algorithm's performance approaches the optimal policy at a rate faster than linear.
The paper provides a detailed Lyapunov-based analysis to establish the sublinear regret bound. It also includes numerical experiments on various continuous-time linear-quadratic control tasks, demonstrating the algorithm's effectiveness in learning near-optimal control policies.
Critical Analysis
The paper provides a strong theoretical foundation for the proposed actor-critic algorithm, with a rigorous regret analysis. However, the analysis relies on several assumptions, such as the linearity of the system dynamics and the quadratic nature of the cost function. It would be interesting to see if the algorithm can be extended to more general nonlinear settings or other cost function formulations.
Additionally, the numerical experiments in the paper are limited to relatively simple continuous-time control tasks. It would be valuable to evaluate the algorithm's performance on more complex, high-dimensional real-world problems to assess its practical applicability.
Another potential area for further research is the exploration of alternative update rules for the actor and critic components, which could potentially lead to even tighter regret bounds or faster convergence rates.
Conclusion
This research paper presents a sublinear regret actor-critic algorithm for continuous-time linear-quadratic reinforcement learning. The theoretical analysis and numerical experiments demonstrate the algorithm's ability to learn near-optimal control policies efficiently, even in complex continuous-time settings.
The work contributes to the growing body of research on reinforcement learning in continuous-time domains, which is essential for applications such as robotics, aerospace, and energy systems. The insights from this paper could inspire further advancements in the field of continuous-time reinforcement learning and optimal control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!