Submodular Reinforcement Learning

0
🏅
Sign in to get full access
Overview
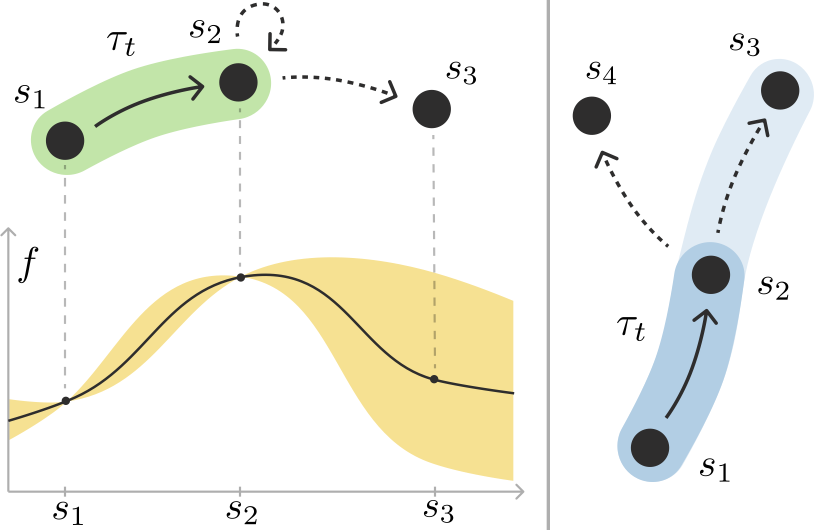
- Reinforcement learning (RL) typically assumes rewards are additive and independent of past states, but many real-world applications have rewards with diminishing returns.
- To address this, the paper proposes submodular RL (SubRL), which uses submodular set functions to model non-additive, history-dependent rewards that capture diminishing returns.
- The paper introduces SubPO, a policy gradient-based algorithm for SubRL that greedily maximizes marginal gains, and shows it can provide optimal approximations under certain assumptions.
- SubPO is applied to various applications like biodiversity monitoring, Bayesian experiment design, and coverage maximization, demonstrating sample efficiency and scalability.
Plain English Explanation
In typical reinforcement learning, the rewards you get for being in a certain state are usually added up, and they don't depend on what states you visited before. But in many real-world problems, like controlling coverage, designing experiments, or planning informative paths, the rewards actually have diminishing returns - their value goes down if you visit similar states.
To handle this, the researchers propose a new approach called submodular RL (SubRL). They use a special type of mathematical function called a submodular set function to model these non-additive, history-dependent rewards. This allows them to capture the diminishing returns property.
Unfortunately, optimizing these kinds of rewards is generally a difficult problem. But taking inspiration from successful algorithms in classical submodular optimization, the researchers develop a simple policy gradient-based algorithm called SubPO that greedily maximizes the marginal gains.
Under certain assumptions about the underlying decision process, SubPO can actually achieve optimal approximations, meaning it can find a good solution even though the overall problem is hard. The researchers also show how to use policy gradients to optimize SubRL in large, complex environments.
They demonstrate SubPO's versatility by applying it to several practical applications like monitoring biodiversity, designing experiments, planning informative paths, and maximizing coverage. The results show that SubPO is sample-efficient and can scale to high-dimensional state and action spaces.
Technical Explanation
The paper proposes a new paradigm called submodular RL (SubRL) to handle reward functions with diminishing returns, which are common in applications like coverage control, experiment design, and informative path planning.
In SubRL, the rewards are modeled using submodular set functions, which can capture non-additive and history-dependent behavior with diminishing returns. Unfortunately, even in tabular settings, the resulting optimization problem is generally hard to approximate.
To address this, the paper introduces SubPO, a simple policy gradient-based algorithm that greedily maximizes the marginal gains. Under certain assumptions on the underlying Markov Decision Process (MDP), SubPO is shown to provide optimal constant factor approximations for submodular bandits.
Moreover, the paper derives a natural policy gradient approach for locally optimizing SubRL instances in large state and action spaces. The versatility of SubPO is demonstrated through applications to biodiversity monitoring, Bayesian experiment design, informative path planning, and coverage maximization. The results showcase the sample efficiency and scalability of the proposed approach.
Critical Analysis
The paper makes a compelling case for the importance of handling diminishing returns in real-world reinforcement learning problems and proposes a principled framework, SubRL, to address this. The introduction of SubPO, a greedy policy gradient algorithm, is a clever approach that leverages the success of greedy algorithms in classical submodular optimization.
While the paper provides strong theoretical guarantees for SubPO under certain assumptions, it would be useful to understand the practical limitations of these assumptions and how they might be relaxed in future work. Additionally, the paper could have discussed potential challenges in scaling SubPO to very large state and action spaces, and how the algorithm might be further optimized for efficiency.
Furthermore, the paper could have provided a more in-depth discussion of the different applications presented and the specific domain-level insights gained from applying SubPO to these problems. Highlighting the unique characteristics and constraints of each application would help readers better appreciate the versatility and real-world relevance of the proposed approach.
Overall, the paper makes a valuable contribution to the field of reinforcement learning by introducing SubRL and the SubPO algorithm, which can enable more effective optimization of complex, non-additive reward functions. Further research building upon these ideas could lead to significant advancements in a wide range of important applications.
Conclusion
This paper presents a novel paradigm called submodular RL (SubRL) that addresses the common issue of diminishing returns in real-world reinforcement learning problems. By modeling rewards using submodular set functions, SubRL can capture non-additive and history-dependent behavior, which is crucial in applications such as coverage control, experiment design, and informative path planning.
To tackle the inherent complexity of optimizing these types of rewards, the paper introduces SubPO, a policy gradient-based algorithm that greedily maximizes marginal gains. Remarkably, under certain assumptions, SubPO is shown to provide optimal constant factor approximations for submodular bandits.
The versatility of the SubPO algorithm is demonstrated through its application to diverse domains, including biodiversity monitoring, Bayesian experiment design, and coverage maximization. The results highlight the sample efficiency and scalability of the proposed approach, making it a promising tool for addressing a wide range of challenging reinforcement learning problems.
Overall, this work represents a significant advancement in the field of reinforcement learning, offering a principled way to handle non-additive rewards with diminishing returns. The insights and techniques presented in this paper could inspire further research and have a lasting impact on the development of more effective and practical reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Submodular Reinforcement Learning
Manish Prajapat, Mojm'ir Mutn'y, Melanie N. Zeilinger, Andreas Krause
In reinforcement learning (RL), rewards of states are typically considered additive, and following the Markov assumption, they are $textit{independent}$ of states visited previously. In many important applications, such as coverage control, experiment design and informative path planning, rewards naturally have diminishing returns, i.e., their value decreases in light of similar states visited previously. To tackle this, we propose $textit{submodular RL}$ (SubRL), a paradigm which seeks to optimize more general, non-additive (and history-dependent) rewards modelled via submodular set functions which capture diminishing returns. Unfortunately, in general, even in tabular settings, we show that the resulting optimization problem is hard to approximate. On the other hand, motivated by the success of greedy algorithms in classical submodular optimization, we propose SubPO, a simple policy gradient-based algorithm for SubRL that handles non-additive rewards by greedily maximizing marginal gains. Indeed, under some assumptions on the underlying Markov Decision Process (MDP), SubPO recovers optimal constant factor approximations of submodular bandits. Moreover, we derive a natural policy gradient approach for locally optimizing SubRL instances even in large state- and action- spaces. We showcase the versatility of our approach by applying SubPO to several applications, such as biodiversity monitoring, Bayesian experiment design, informative path planning, and coverage maximization. Our results demonstrate sample efficiency, as well as scalability to high-dimensional state-action spaces.
Read more5/27/2024
0
Global Reinforcement Learning: Beyond Linear and Convex Rewards via Submodular Semi-gradient Methods
Riccardo De Santi, Manish Prajapat, Andreas Krause
In classic Reinforcement Learning (RL), the agent maximizes an additive objective of the visited states, e.g., a value function. Unfortunately, objectives of this type cannot model many real-world applications such as experiment design, exploration, imitation learning, and risk-averse RL to name a few. This is due to the fact that additive objectives disregard interactions between states that are crucial for certain tasks. To tackle this problem, we introduce Global RL (GRL), where rewards are globally defined over trajectories instead of locally over states. Global rewards can capture negative interactions among states, e.g., in exploration, via submodularity, positive interactions, e.g., synergetic effects, via supermodularity, while mixed interactions via combinations of them. By exploiting ideas from submodular optimization, we propose a novel algorithmic scheme that converts any GRL problem to a sequence of classic RL problems and solves it efficiently with curvature-dependent approximation guarantees. We also provide hardness of approximation results and empirically demonstrate the effectiveness of our method on several GRL instances.
Read more7/16/2024
0
A Pontryagin Perspective on Reinforcement Learning
Onno Eberhard, Claire Vernade, Michael Muehlebach
Reinforcement learning has traditionally focused on learning state-dependent policies to solve optimal control problems in a closed-loop fashion. In this work, we introduce the paradigm of open-loop reinforcement learning where a fixed action sequence is learned instead. We present three new algorithms: one robust model-based method and two sample-efficient model-free methods. Rather than basing our algorithms on Bellman's equation from dynamic programming, our work builds on Pontryagin's principle from the theory of open-loop optimal control. We provide convergence guarantees and evaluate all methods empirically on a pendulum swing-up task, as well as on two high-dimensional MuJoCo tasks, demonstrating remarkable performance compared to existing baselines.
Read more5/29/2024
🏅
0
REBEL: Reinforcement Learning via Regressing Relative Rewards
Zhaolin Gao, Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Gokul Swamy, Kiant'e Brantley, Thorsten Joachims, J. Andrew Bagnell, Jason D. Lee, Wen Sun
While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications, including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping), and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative reward between two completions to a prompt in terms of the policy, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and be extended to handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally efficient than PPO. When fine-tuning Llama-3-8B-Instruct, REBEL achieves strong performance in AlpacaEval 2.0, MT-Bench, and Open LLM Leaderboard.
Read more9/4/2024