SUMO: Search-Based Uncertainty Estimation for Model-Based Offline Reinforcement Learning

0
Sign in to get full access
Overview
- The paper introduces SUMO, a search-based method for uncertainty estimation in model-based offline reinforcement learning (MBRL).
- SUMO aims to improve the reliability and safety of MBRL systems by providing accurate uncertainty estimates.
- The method involves searching for the most uncertain actions and updating the model accordingly, leading to better overall performance.
Plain English Explanation
In model-based reinforcement learning (MBRL), robots or agents learn to perform tasks by building a model of their environment and then using that model to plan their actions. This can be more efficient than traditional "model-free" reinforcement learning, but it requires accurately estimating the uncertainty in the model.
SUMO, or Search-Based Uncertainty Estimation for Model-Based Offline Reinforcement Learning, is a new technique that aims to improve the uncertainty estimates in MBRL systems. The key idea is to actively search for the most uncertain actions the agent could take, and then update the model based on those actions. This helps the agent better understand the limits of its knowledge and make more reliable decisions.
For example, imagine a robot learning to navigate a room. The robot might build a model of the room, but there might be some areas it's not sure about, like behind a couch or under a table. SUMO would help the robot identify those uncertain areas and gather more information about them, leading to a better overall model of the room and improved navigation.
By providing more accurate uncertainty estimates, SUMO can make MBRL systems more reliable and safer, which is important for applications like self-driving cars, robotic surgery, and other high-stakes domains.
Technical Explanation
The core of SUMO is a search-based algorithm that identifies the most uncertain actions the agent could take in a given state. The algorithm works by generating a set of candidate actions, evaluating their uncertainty, and then selecting the most uncertain one to update the model.
To measure uncertainty, SUMO uses a Bayesian neural network to represent the transition dynamics model. This allows the model to output not just a prediction, but also an estimate of the uncertainty in that prediction.
The search process involves iteratively generating candidate actions, evaluating their uncertainty, and selecting the most uncertain one. This continues until a termination condition is met, such as a limit on the number of iterations or a target level of uncertainty reduction.
Once the most uncertain action is identified, SUMO updates the transition dynamics model by collecting new data for that action and incorporating it into the model. This helps reduce the overall uncertainty in the model and improve its reliability.
The authors evaluate SUMO on a suite of benchmark tasks, including classic control problems and more complex robotic manipulation tasks. They show that SUMO outperforms other state-of-the-art MBRL methods in terms of both task performance and uncertainty estimation accuracy.
Critical Analysis
The SUMO paper makes a valuable contribution by addressing the critical issue of uncertainty estimation in MBRL systems. Accurately quantifying uncertainty is essential for the safe and reliable deployment of these systems, particularly in high-stakes applications.
One potential limitation of SUMO is that the search process can be computationally intensive, especially as the complexity of the task and the size of the action space grow. The authors acknowledge this and suggest that future work could explore ways to make the search more efficient, such as by incorporating learned heuristics or leveraging parallelization.
Another area for further research could be exploring how SUMO's uncertainty estimates could be used not just for model improvement, but also for safer exploration and robust decision-making. By incorporating the uncertainty information into the agent's decision-making process, the system could become even more reliable and trustworthy.
Overall, the SUMO paper represents an important step forward in the field of MBRL, and the authors' approach to uncertainty estimation is a valuable contribution that could have significant implications for the deployment of these systems in real-world applications.
Conclusion
The SUMO paper introduces a novel search-based method for uncertainty estimation in model-based offline reinforcement learning (MBRL) systems. By actively identifying the most uncertain actions and updating the model accordingly, SUMO can provide more reliable and accurate uncertainty estimates, leading to improved overall performance and safety.
The technical details of SUMO's search-based approach and Bayesian neural network-based uncertainty estimation are well-explained and evaluated on a range of benchmark tasks. While the computational cost of the search process is a potential limitation, the authors discuss ways to address this in future work.
Overall, SUMO represents an important step forward in the quest to make MBRL systems more reliable and trustworthy, with significant implications for a wide range of real-world applications where safety and robustness are paramount.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SUMO: Search-Based Uncertainty Estimation for Model-Based Offline Reinforcement Learning
Zhongjian Qiao, Jiafei Lyu, Kechen Jiao, Qi Liu, Xiu Li
The performance of offline reinforcement learning (RL) suffers from the limited size and quality of static datasets. Model-based offline RL addresses this issue by generating synthetic samples through a dynamics model to enhance overall performance. To evaluate the reliability of the generated samples, uncertainty estimation methods are often employed. However, model ensemble, the most commonly used uncertainty estimation method, is not always the best choice. In this paper, we propose a textbf{S}earch-based textbf{U}ncertainty estimation method for textbf{M}odel-based textbf{O}ffline RL (SUMO) as an alternative. SUMO characterizes the uncertainty of synthetic samples by measuring their cross entropy against the in-distribution dataset samples, and uses an efficient search-based method for implementation. In this way, SUMO can achieve trustworthy uncertainty estimation. We integrate SUMO into several model-based offline RL algorithms including MOPO and Adapted MOReL (AMOReL), and provide theoretical analysis for them. Extensive experimental results on D4RL datasets demonstrate that SUMO can provide more accurate uncertainty estimation and boost the performance of base algorithms. These indicate that SUMO could be a better uncertainty estimator for model-based offline RL when used in either reward penalty or trajectory truncation. Our code is available and will be open-source for further research and development.
Read more8/26/2024

0
Deterministic Uncertainty Propagation for Improved Model-Based Offline Reinforcement Learning
Abdullah Akgul, Manuel Hau{ss}mann, Melih Kandemir
Current approaches to model-based offline Reinforcement Learning (RL) often incorporate uncertainty-based reward penalization to address the distributional shift problem. While these approaches have achieved some success, we argue that this penalization introduces excessive conservatism, potentially resulting in suboptimal policies through underestimation. We identify as an important cause of over-penalization the lack of a reliable uncertainty estimator capable of propagating uncertainties in the Bellman operator. The common approach to calculating the penalty term relies on sampling-based uncertainty estimation, resulting in high variance. To address this challenge, we propose a novel method termed Moment Matching Offline Model-Based Policy Optimization (MOMBO). MOMBO learns a Q-function using moment matching, which allows us to deterministically propagate uncertainties through the Q-function. We evaluate MOMBO's performance across various environments and demonstrate empirically that MOMBO is a more stable and sample-efficient approach.
Read more6/7/2024

0
SeMOPO: Learning High-quality Model and Policy from Low-quality Offline Visual Datasets
Shenghua Wan, Ziyuan Chen, Le Gan, Shuai Feng, De-Chuan Zhan
Model-based offline reinforcement Learning (RL) is a promising approach that leverages existing data effectively in many real-world applications, especially those involving high-dimensional inputs like images and videos. To alleviate the distribution shift issue in offline RL, existing model-based methods heavily rely on the uncertainty of learned dynamics. However, the model uncertainty estimation becomes significantly biased when observations contain complex distractors with non-trivial dynamics. To address this challenge, we propose a new approach - emph{Separated Model-based Offline Policy Optimization} (SeMOPO) - decomposing latent states into endogenous and exogenous parts via conservative sampling and estimating model uncertainty on the endogenous states only. We provide a theoretical guarantee of model uncertainty and performance bound of SeMOPO. To assess the efficacy, we construct the Low-Quality Vision Deep Data-Driven Datasets for RL (LQV-D4RL), where the data are collected by non-expert policy and the observations include moving distractors. Experimental results show that our method substantially outperforms all baseline methods, and further analytical experiments validate the critical designs in our method. The project website is href{https://sites.google.com/view/semopo}{https://sites.google.com/view/semopo}.
Read more6/17/2024
0
COSBO: Conservative Offline Simulation-Based Policy Optimization
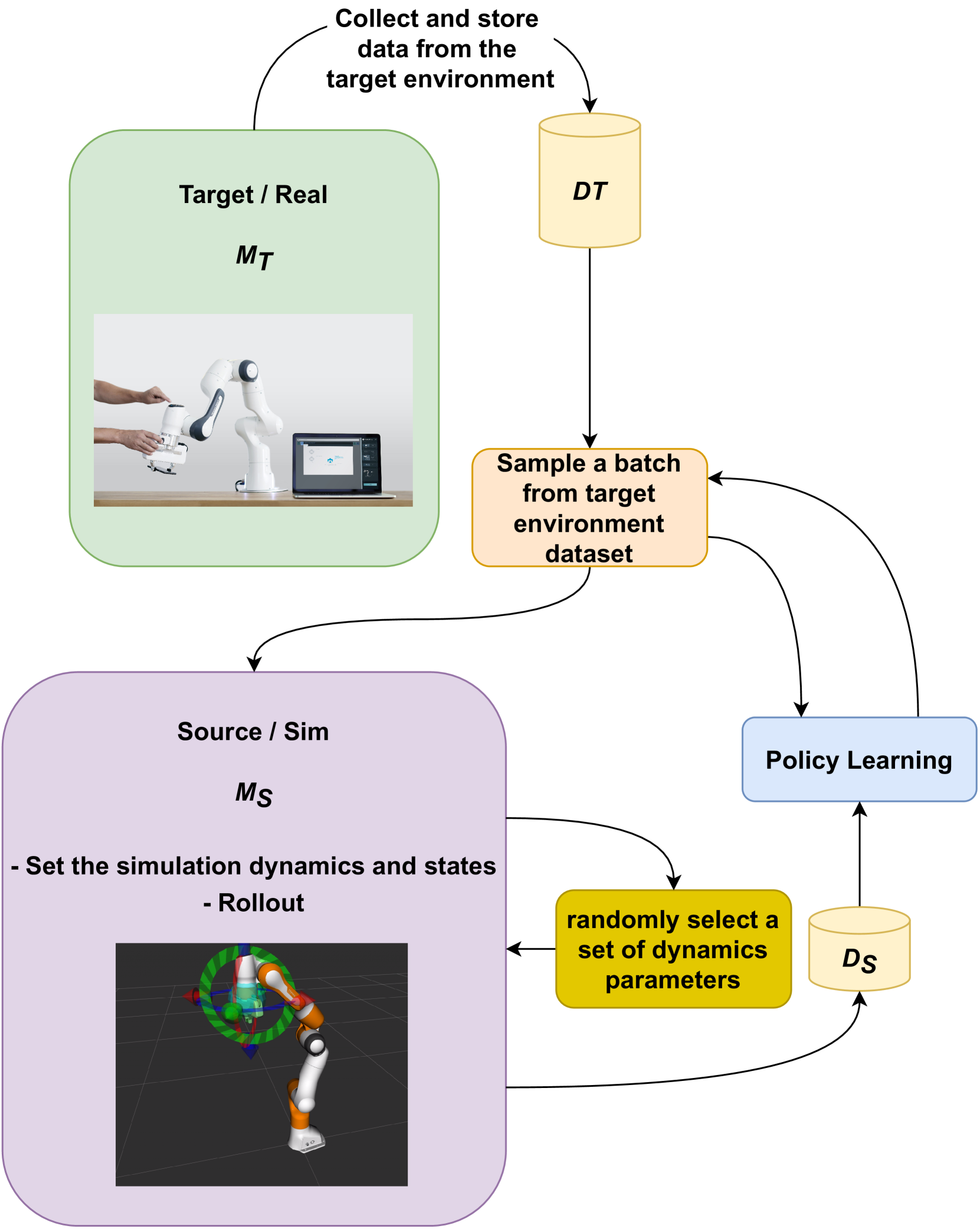
Eshagh Kargar, Ville Kyrki
Offline reinforcement learning allows training reinforcement learning models on data from live deployments. However, it is limited to choosing the best combination of behaviors present in the training data. In contrast, simulation environments attempting to replicate the live environment can be used instead of the live data, yet this approach is limited by the simulation-to-reality gap, resulting in a bias. In an attempt to get the best of both worlds, we propose a method that combines an imperfect simulation environment with data from the target environment, to train an offline reinforcement learning policy. Our experiments demonstrate that the proposed method outperforms state-of-the-art approaches CQL, MOPO, and COMBO, especially in scenarios with diverse and challenging dynamics, and demonstrates robust behavior across a variety of experimental conditions. The results highlight that using simulator-generated data can effectively enhance offline policy learning despite the sim-to-real gap, when direct interaction with the real-world is not possible.
Read more9/24/2024