SumRecom: A Personalized Summarization Approach by Learning from Users' Feedback

0

Sign in to get full access
Overview
- Novel personalized summarization approach that learns from user feedback
- Aims to generate summaries tailored to individual user preferences
- Leverages large language models and reinforcement learning
Plain English Explanation
[object Object]: The key idea is to create summaries that are customized to each individual user's preferences, rather than a one-size-fits-all approach. This is accomplished by learning from the user's feedback on previous summaries.
[object Object]: The system collects feedback from users on the summaries it generates, such as whether the summary was helpful or if important information was missing. It then uses this feedback to fine-tune and improve the summarization model for that particular user.
[object Object]: The system employs reinforcement learning, a machine learning technique where the model is rewarded for generating summaries that align with the user's preferences. Over time, the model learns to produce summaries that are tailored to the user's needs.
[object Object]: The summarization system leverages the capabilities of large, pre-trained language models, which have shown impressive performance on a variety of natural language processing tasks, including summarization. These models serve as the foundation for the personalized summarization approach.
Technical Explanation
[object Object]: The SumRecom system aims to generate personalized summaries by learning from user feedback. It uses a reinforcement learning-based approach to fine-tune a base summarization model for each individual user, rather than relying on a one-size-fits-all model.
[object Object]: The system collects feedback from users on the summaries it generates, including ratings and comments. This feedback is then used to update the summarization model, with the goal of producing summaries that better match the user's preferences over time.
[object Object]: SumRecom employs a reinforcement learning framework, where the summarization model is rewarded for generating summaries that are well-received by the user. The model learns to produce summaries that align with the user's needs through this iterative feedback and reward process.
[object Object]: The system utilizes a large, pre-trained language model as the foundation for the summarization task. This allows the model to leverage the rich semantic understanding and generation capabilities of these powerful language models, which have demonstrated strong performance on a variety of natural language processing tasks.
Critical Analysis
The paper presents a novel and promising approach to personalized summarization, but there are a few potential limitations and areas for further research:
[object Object]: The authors only evaluate the system's performance on a small, synthetic dataset. It would be helpful to see how the system performs on real-world, diverse text corpora and with a larger number of users.
[object Object]: The paper does not address the challenges of maintaining long-term user engagement and feedback, which is crucial for the continued improvement of the personalized summaries.
[object Object]: The use of large language models and reinforcement learning can make the summarization process more opaque. Providing users with explanations for the generated summaries could improve trust and transparency.
[object Object]: As with any personalized system, there are potential concerns around data privacy and the risk of reinforcing biases. These issues should be carefully considered and addressed.
Conclusion
The SumRecom system presents an innovative approach to personalized text summarization by leveraging user feedback and reinforcement learning. By tailoring the summaries to individual preferences, the system has the potential to significantly improve the usefulness and relevance of summarized information for users. However, further research is needed to address the system's limitations and ensure its ethical deployment. Overall, this work represents an exciting step towards more personalized and user-centric natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SumRecom: A Personalized Summarization Approach by Learning from Users' Feedback
Samira Ghodratnama, Mehrdad Zakershahrak
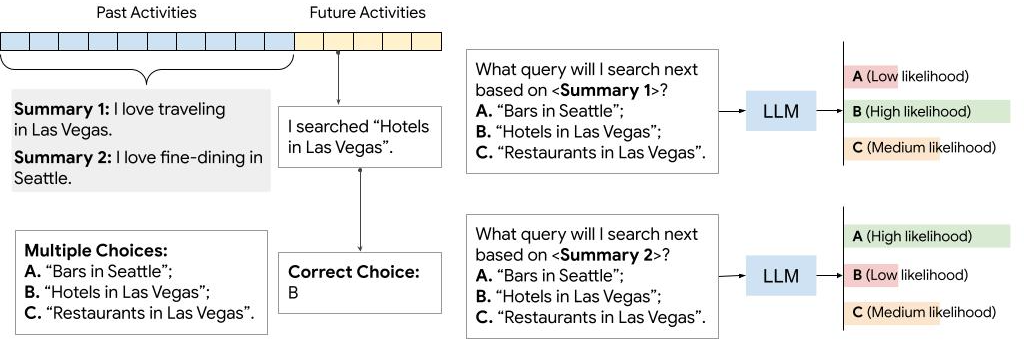
Existing multi-document summarization approaches produce a uniform summary for all users without considering individuals' interests, which is highly impractical. Making a user-specific summary is a challenging task as it requires: i) acquiring relevant information about a user; ii) aggregating and integrating the information into a user-model; and iii) utilizing the provided information in making the personalized summary. Therefore, in this paper, we propose a solution to a substantial and challenging problem in summarization, i.e., recommending a summary for a specific user. The proposed approach, called SumRecom, brings the human into the loop and focuses on three aspects: personalization, interaction, and learning user's interest without the need for reference summaries. SumRecom has two steps: i) The user preference extractor to capture users' inclination in choosing essential concepts, and ii) The summarizer to discover the user's best-fitted summary based on the given feedback. Various automatic and human evaluations on the benchmark dataset demonstrate the supremacy SumRecom in generating user-specific summaries. Document summarization and Interactive summarization and Personalized summarization and Reinforcement learning.
Read more8/15/2024
0
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Chao Wang, Neo Wu, Lin Ning, Jiaxing Wu, Luyang Liu, Jun Xie, Shawn O'Banion, Bradley Green
Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Read more9/9/2024
💬
0
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
Chiyu Zhang, Yifei Sun, Minghao Wu, Jun Chen, Jie Lei, Muhammad Abdul-Mageed, Rong Jin, Angli Liu, Ji Zhu, Sem Park, Ning Yao, Bo Long
Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
Read more8/20/2024
⛏️
0
Thesis: Document Summarization with applications to Keyword extraction and Image Retrieval
Jayaprakash Sundararaj
Automatic summarization is the process of reducing a text document in order to generate a summary that retains the most important points of the original document. In this work, we study two problems - i) summarizing a text document as set of keywords/caption, for image recommedation, ii) generating opinion summary which good mix of relevancy and sentiment with the text document. Intially, we present our work on an recommending images for enhancing a substantial amount of existing plain text news articles. We use probabilistic models and word similarity heuristics to generate captions and extract Key-phrases which are re-ranked using a rank aggregation framework with relevance feedback mechanism. We show that such rank aggregation and relevant feedback which are typically used in Tagging Documents, Text Information Retrieval also helps in improving image retrieval. These queries are fed to the Yahoo Search Engine to obtain relevant images 1. Our proposed method is observed to perform better than all existing baselines. Additonally, We propose a set of submodular functions for opinion summarization. Opinion summarization has built in it the tasks of summarization and sentiment detection. However, it is not easy to detect sentiment and simultaneously extract summary. The two tasks conflict in the sense that the demand of compression may drop sentiment bearing sentences, and the demand of sentiment detection may bring in redundant sentences. However, using submodularity we show how to strike a balance between the two requirements. Our functions generate summaries such that there is good correlation between document sentiment and summary sentiment along with good ROUGE score. We also compare the performances of the proposed submodular functions.
Read more6/4/2024