UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches

0
Sign in to get full access
Overview
- UserSumBench is a benchmark framework for evaluating user summarization approaches.
- It aims to provide a standardized way to assess the performance of systems that generate summaries based on user preferences and behaviors.
- The framework includes a dataset, evaluation metrics, and baseline models to facilitate research in this area.
Plain English Explanation
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches presents a new tool for assessing systems that automatically create summaries of documents based on individual user needs and preferences. The key idea is that a one-size-fits-all summary may not be optimal for every reader - some users may want a concise overview, while others may prefer more detailed information.
The UserSumBench framework includes a dataset of articles and associated user feedback, as well as standardized metrics for evaluating the quality of personalized summaries. By providing a common set of resources, the researchers aim to facilitate more rigorous and comparable research in this area. This could lead to the development of better summarization systems that adapt to the unique needs and interests of each user.
Technical Explanation
The UserSumBench framework consists of three main components:
-
Dataset: A collection of articles, user profiles, and user feedback on summaries. This allows researchers to train and evaluate systems on real-world user preferences.
-
Evaluation Metrics: A set of metrics that measure the quality of a summary from the user's perspective, such as relevance, coherence, and informativeness.
-
Baseline Models: Several existing summarization approaches that can serve as benchmarks for comparison, including extractive, abstractive, and personalized methods.
The paper describes the process of constructing the dataset, defining the evaluation metrics, and implementing the baseline models. Experiments are conducted to demonstrate the usefulness of the UserSumBench framework and identify areas for improvement in user-tailored summarization.
Critical Analysis
The UserSumBench framework is a valuable contribution to the field of text summarization, as it addresses the important challenge of personalizing summaries to individual users' needs. By providing a standardized benchmark, the researchers enable more rigorous and comparable evaluations of summarization systems.
However, the paper acknowledges some limitations of the current framework. For example, the dataset may not capture the full diversity of user preferences, and the evaluation metrics may not fully capture all aspects of user satisfaction. Additionally, the baseline models included may not represent the state-of-the-art in personalized summarization, and further research is needed to develop more advanced techniques in this area.
Despite these caveats, UserSumBench represents an important step forward in the quest to create summarization systems that truly meet the needs of individual users. As the field of user-centric summarization continues to evolve, this framework can serve as a valuable tool for driving research and innovation.
Conclusion
The UserSumBench paper presents a comprehensive framework for evaluating user summarization approaches, including a dataset, evaluation metrics, and baseline models. This work addresses the important challenge of personalizing summaries to individual user preferences, which is crucial for the development of more effective and user-friendly summarization systems. By providing a standardized benchmark, the researchers aim to facilitate further advancements in this area of text summarization research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Chao Wang, Neo Wu, Lin Ning, Jiaxing Wu, Luyang Liu, Jun Xie, Shawn O'Banion, Bradley Green
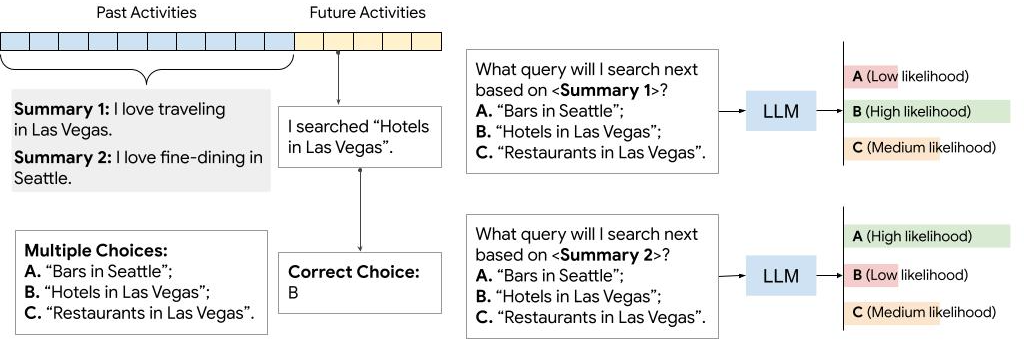
Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Read more9/9/2024

0
A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
Read more7/2/2024

0
SumRecom: A Personalized Summarization Approach by Learning from Users' Feedback
Samira Ghodratnama, Mehrdad Zakershahrak
Existing multi-document summarization approaches produce a uniform summary for all users without considering individuals' interests, which is highly impractical. Making a user-specific summary is a challenging task as it requires: i) acquiring relevant information about a user; ii) aggregating and integrating the information into a user-model; and iii) utilizing the provided information in making the personalized summary. Therefore, in this paper, we propose a solution to a substantial and challenging problem in summarization, i.e., recommending a summary for a specific user. The proposed approach, called SumRecom, brings the human into the loop and focuses on three aspects: personalization, interaction, and learning user's interest without the need for reference summaries. SumRecom has two steps: i) The user preference extractor to capture users' inclination in choosing essential concepts, and ii) The summarizer to discover the user's best-fitted summary based on the given feedback. Various automatic and human evaluations on the benchmark dataset demonstrate the supremacy SumRecom in generating user-specific summaries. Document summarization and Interactive summarization and Personalized summarization and Reinforcement learning.
Read more8/15/2024
0
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024