Mixture to Mixture: Leveraging Close-talk Mixtures as Weak-supervision for Speech Separation

0
🗣️
Sign in to get full access
Overview
- The paper proposes a novel approach called "Mixture to Mixture (M2M) training" for neural speech separation in far-field settings
- The key idea is to leverage close-talk audio mixtures as a weak supervision signal to train models that can separate speakers in far-field recordings
- Evaluation on a 2-speaker separation task in simulated reverberant conditions shows M2M can effectively utilize close-talk mixtures to separate far-field mixtures
Plain English Explanation
The researchers developed a new way to train neural networks to separate different speakers in audio recordings taken from a distance (far-field). The main challenge is that it's difficult to get high-quality training data for this task, as recordings of multiple speakers in a room will have lower signal quality and more background noise compared to recordings made up close (close-talk) to each individual speaker.
The key insight of this work is that even though the far-field recordings are noisy, the close-talk recordings of the same speakers have a much higher signal-to-noise ratio for each individual speaker. So the researchers use these close-talk recordings as a "weak supervision" signal to train the neural network models.
At each training step, the model takes a far-field mixture as input and produces estimates for each individual speaker. It then tries to adjust these estimates so that, when linearly filtered, they can reproduce the audio recorded by both the close-talk and far-field microphones. In this way, the close-talk recordings help guide the model to learn to separate the speakers even in the noisier far-field settings.
The experiments show this weakly-supervised approach is effective at separating speakers in reverberant, far-field conditions without needing high-quality, manually labeled training data. This could be very useful for real-world applications like speech recognition in noisy environments or multi-talker speech separation.
Technical Explanation
The core of the proposed "Mixture to Mixture (M2M) training" approach is to leverage close-talk audio mixtures as a weak supervision signal to train a deep neural network (DNN) model for separating speakers in far-field recordings.
At each training step, the model is fed a far-field audio mixture as input. The model then produces initial estimates for each individual speaker in the mixture. These estimates are then linearly filtered to produce estimates that can be compared to the audio recorded by both the close-talk and far-field microphones. The model is trained by optimizing a loss function that encourages the filtered estimates to match the actual microphone recordings.
The key insight is that the close-talk mixtures have a much higher signal-to-noise ratio (SNR) for each speaker compared to the far-field mixtures. So even though the close-talk recordings don't provide exact ground truth for the far-field separation task, they can act as a useful weak supervision signal to guide the model towards learning effective separation.
Experiments on a 2-speaker separation task in simulated reverberant conditions show that M2M training can leverage the close-talk mixtures to outperform fully-supervised baseline models that don't have access to the close-talk data.
Critical Analysis
The paper provides a thorough evaluation of the proposed M2M training approach, demonstrating its effectiveness on a simulated 2-speaker separation task. However, there are a few potential limitations and areas for further research that could be explored:
-
The experiments are limited to simulated reverberant conditions, so it's unclear how well the approach would generalize to more diverse real-world acoustic environments.
-
The paper only considers 2-speaker mixtures, but many real-world scenarios involve more than 2 speakers. Extending the approach to handle a larger number of speakers may require additional innovations.
-
The paper does not provide much insight into the failure modes or limitations of the M2M approach. Understanding when and why it might fail could help guide future improvements.
-
The reliance on close-talk mixtures as a weak supervision signal could be challenging to obtain in practice, especially for large-scale training datasets. Exploring alternative weak supervision sources, such as text-aware speech separation, may be a fruitful direction for further research.
Overall, the M2M training approach represents a promising step forward in weakly-supervised audio separation, and the paper provides a solid technical foundation for future work in this area.
Conclusion
The proposed Mixture to Mixture (M2M) training approach leverages close-talk audio mixtures as a weak supervision signal to train neural networks for separating speakers in far-field recordings. By optimizing the model to reproduce the close-talk and far-field microphone signals, M2M can effectively utilize the high-SNR close-talk data to learn effective separation strategies even in noisy, reverberant conditions.
The evaluation results demonstrate the effectiveness of this weakly-supervised approach, which could have important implications for real-world applications like speech recognition, multi-talker speech separation, and blind source separation in challenging acoustic environments. Further research is needed to explore the limitations of M2M and investigate alternative weak supervision sources to make the approach more widely applicable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Mixture to Mixture: Leveraging Close-talk Mixtures as Weak-supervision for Speech Separation
Zhong-Qiu Wang
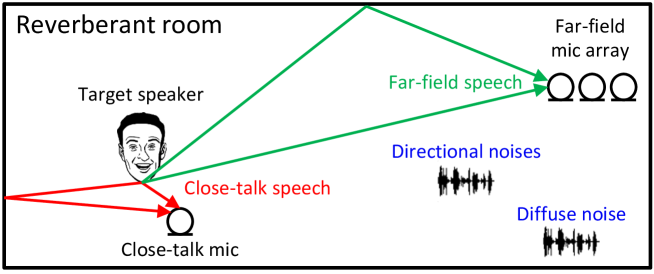
We propose mixture to mixture (M2M) training, a weakly-supervised neural speech separation algorithm that leverages close-talk mixtures as a weak supervision for training discriminative models to separate far-field mixtures. Our idea is that, for a target speaker, its close-talk mixture has a much higher signal-to-noise ratio (SNR) of the target speaker than any far-field mixtures, and hence could be utilized to design a weak supervision for separation. To realize this, at each training step we feed a far-field mixture to a deep neural network (DNN) to produce an intermediate estimate for each speaker, and, for each of considered close-talk and far-field microphones, we linearly filter the DNN estimates and optimize a loss so that the filtered estimates of all the speakers can sum up to the mixture captured by each of the considered microphones. Evaluation results on a 2-speaker separation task in simulated reverberant conditions show that M2M can effectively leverage close-talk mixtures as a weak supervision for separating far-field mixtures.
Read more6/18/2024
0
SuperM2M: Supervised and Mixture-to-Mixture Co-Learning for Speech Enhancement and Robust ASR
Zhong-Qiu Wang
The current dominant approach for neural speech enhancement is based on supervised learning by using simulated training data. The trained models, however, often exhibit limited generalizability to real-recorded data. To address this, this paper investigates training enhancement models directly on real target-domain data. We propose to adapt mixture-to-mixture (M2M) training, originally designed for speaker separation, for speech enhancement, by modeling multi-source noise signals as a single, combined source. In addition, we propose a co-learning algorithm that improves M2M with the help of supervised algorithms. When paired close-talk and far-field mixtures are available for training, M2M realizes speech enhancement by training a deep neural network (DNN) to produce speech and noise estimates in a way such that they can be linearly filtered to reconstruct the close-talk and far-field mixtures. This way, the DNN can be trained directly on real mixtures, and can leverage close-talk and far-field mixtures as a weak supervision to enhance far-field mixtures. To improve M2M, we combine it with supervised approaches to co-train the DNN, where mini-batches of real close-talk and far-field mixture pairs and mini-batches of simulated mixture and clean speech pairs are alternately fed to the DNN, and the loss functions are respectively (a) the mixture reconstruction loss on the real close-talk and far-field mixtures and (b) the regular enhancement loss on the simulated clean speech and noise. We find that, this way, the DNN can learn from real and simulated data to achieve better generalization to real data. We name this algorithm SuperM2M (supervised and mixture-to-mixture co-learning). Evaluation results on the CHiME-4 dataset show its effectiveness and potential.
Read more6/21/2024

0
Cross-Talk Reduction
Zhong-Qiu Wang, Anurag Kumar, Shinji Watanabe
While far-field multi-talker mixtures are recorded, each speaker can wear a close-talk microphone so that close-talk mixtures can be recorded at the same time. Although each close-talk mixture has a high signal-to-noise ratio (SNR) of the wearer, it has a very limited range of applications, as it also contains significant cross-talk speech by other speakers and is not clean enough. In this context, we propose a novel task named cross-talk reduction (CTR) which aims at reducing cross-talk speech, and a novel solution named CTRnet which is based on unsupervised or weakly-supervised neural speech separation. In unsupervised CTRnet, close-talk and far-field mixtures are stacked as input for a DNN to estimate the close-talk speech of each speaker. It is trained in an unsupervised, discriminative way such that the DNN estimate for each speaker can be linearly filtered to cancel out the speaker's cross-talk speech captured at other microphones. In weakly-supervised CTRnet, we assume the availability of each speaker's activity timestamps during training, and leverage them to improve the training of unsupervised CTRnet. Evaluation results on a simulated two-speaker CTR task and on a real-recorded conversational speech separation and recognition task show the effectiveness and potential of CTRnet.
Read more6/3/2024

0
ctPuLSE: Close-Talk, and Pseudo-Label Based Far-Field, Speech Enhancement
Zhong-Qiu Wang
The current dominant approach for neural speech enhancement is via purely-supervised deep learning on simulated pairs of far-field noisy-reverberant speech (i.e., mixtures) and clean speech. The trained models, however, often exhibit limited generalizability to real-recorded mixtures. To deal with this, this paper investigates training enhancement models directly on real mixtures. However, a major difficulty challenging this approach is that, since the clean speech of real mixtures is unavailable, there lacks a good supervision for real mixtures. In this context, assuming that a training set consisting of real-recorded pairs of close-talk and far-field mixtures is available, we propose to address this difficulty via close-talk speech enhancement, where an enhancement model is first trained on simulated mixtures to enhance real-recorded close-talk mixtures and the estimated close-talk speech can then be utilized as a supervision (i.e., pseudo-label) for training far-field speech enhancement models directly on the paired real-recorded far-field mixtures. We name the proposed system $textit{ctPuLSE}$. Evaluation results on the CHiME-4 dataset show that ctPuLSE can derive high-quality pseudo-labels and yield far-field speech enhancement models with strong generalizability to real data.
Read more7/30/2024