Superpixel Semantics Representation and Pre-training for Vision-Language Task

0
🖼️
Sign in to get full access
Overview
- The paper proposes a new approach for integrating visual language tasks by using superpixels as the foundation.
- It introduces a Multiscale Difference Graph Convolutional Network (MDGCN) to capture semantic features at the superpixel level and reason about actual semantic relations.
- The method aims to improve learning for downstream tasks by mining complementary spatial information at different levels in a bottom-up manner.
Plain English Explanation
The key to making progress on visual understanding tasks is to find the right way to represent visual information. Recently, dividing images into grids or patches has led to fine-grained visual understanding. However, this approach can miss important contextual information at the boundaries of the scene.
This paper suggests using superpixels as a more comprehensive and robust way to represent the visual information. Superpixels group together nearby pixels that look similar, capturing the coarse-grained semantic interactions in the image.
To make use of these superpixel representations, the authors propose a neural network called the Multiscale Difference Graph Convolutional Network (MDGCN). This network can analyze the entire image as a hierarchical structure, going from fine details to coarse overall patterns. By looking at the differences between neighboring superpixels, the network can better understand the actual semantic relationships in the scene, avoiding potential noise.
Finally, the method fuses information from different levels of the hierarchy in a bottom-up way. This helps ensure that the high-level understanding is grounded in the low-level visual details, avoiding any deviations in the interpretation.
Experiments show that this approach outperforms previous methods on various visual understanding tasks. The key innovation is using superpixels as the fundamental building blocks instead of rigid grids or patches.
Technical Explanation
The paper addresses the challenge of integrating visual and language tasks by proposing a new alignment strategy based on superpixels. Recent work has achieved impressive fine-grained visual understanding by dividing images into grids or patches. However, this coarse-grained representation can miss important contextual semantic interactions at the scene boundaries.
To address this, the authors propose using superpixels as the fundamental visual primitives. Superpixels group together perceptually similar pixels, capturing the coarse-grained semantic relationships in the image. This provides a more comprehensive and robust representation than rigid grids.
To leverage these superpixel representations, the authors introduce the Multiscale Difference Graph Convolutional Network (MDGCN). This network can analyze the image as a fine-to-coarse visual hierarchy, parsing the entire scene. Crucially, it reasons about the actual semantic relations by aggregating the difference information between adjacent superpixels, reducing potential noise interference.
Finally, the method employs a multi-level fusion approach in a bottom-up manner. This allows it to mine complementary spatial information at different levels of the hierarchy, avoiding any deviations in the final semantic understanding.
Experiments demonstrate that this superpixel-based approach outperforms previous methods on a range of visual language tasks, highlighting the benefits of the proposed alignment strategy and neural architecture.
Critical Analysis
The paper presents a compelling approach to visual understanding by leveraging superpixels as the fundamental visual primitives. This is a promising alternative to the more common grid-based or patch-based representations, as it can better capture the coarse-grained semantic relationships in the image.
One potential limitation is the computational complexity of the MDGCN architecture, which needs to reason about the differences between all neighboring superpixels. This could become challenging for high-resolution images with a large number of superpixels. The authors may need to explore ways to make the graph reasoning more efficient, perhaps through techniques like sparse graph convolutions.
Additionally, the paper does not provide much insight into the failure modes of the proposed method or areas for future improvement. It would be helpful to see a more detailed analysis of the types of visual scenes or tasks where the superpixel-based approach struggles compared to other methods.
Overall, this work represents an interesting and promising direction for visual understanding research. The use of superpixels as a more holistic visual representation is a creative solution to the limitations of grid-based approaches. Further research into the scalability and robustness of this method could lead to significant advancements in integrated visual-language understanding.
Conclusion
This paper introduces a novel approach to visual language integration by using superpixels as the fundamental visual primitives. The proposed Multiscale Difference Graph Convolutional Network (MDGCN) can effectively capture semantic features at the superpixel level and reason about actual semantic relations, avoiding potential noise interference.
By fusing information from different levels of the visual hierarchy in a bottom-up manner, the method is able to outperform previous approaches on a range of visual understanding tasks. This work highlights the benefits of using more comprehensive and robust visual representations, rather than relying solely on rigid grids or patches.
As the field of visual-language integration continues to advance, techniques like the one presented in this paper will be crucial for developing practical systems that can truly understand the complex semantics of the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Superpixel Semantics Representation and Pre-training for Vision-Language Task
Siyu Zhang, Yeming Chen, Yaoru Sun, Fang Wang, Jun Yang, Lizhi Bai, Shangce Gao
The key to integrating visual language tasks is to establish a good alignment strategy. Recently, visual semantic representation has achieved fine-grained visual understanding by dividing grids or image patches. However, the coarse-grained semantic interactions in image space should not be ignored, which hinders the extraction of complex contextual semantic relations at the scene boundaries. This paper proposes superpixels as comprehensive and robust visual primitives, which mine coarse-grained semantic interactions by clustering perceptually similar pixels, speeding up the subsequent processing of primitives. To capture superpixel-level semantic features, we propose a Multiscale Difference Graph Convolutional Network (MDGCN). It allows parsing the entire image as a fine-to-coarse visual hierarchy. To reason actual semantic relations, we reduce potential noise interference by aggregating difference information between adjacent graph nodes. Finally, we propose a multi-level fusion rule in a bottom-up manner to avoid understanding deviation by mining complementary spatial information at different levels. Experiments show that the proposed method can effectively promote the learning of multiple downstream tasks. Encouragingly, our method outperforms previous methods on all metrics. Our code will be released upon publication.
Read more7/23/2024
📉
0
Framework-agnostic Semantically-aware Global Reasoning for Segmentation
Mir Rayat Imtiaz Hossain, Leonid Sigal, James J. Little
Recent advances in pixel-level tasks (e.g. segmentation) illustrate the benefit of of long-range interactions between aggregated region-based representations that can enhance local features. However, such aggregated representations, often in the form of attention, fail to model the underlying semantics of the scene (e.g. individual objects and, by extension, their interactions). In this work, we address the issue by proposing a component that learns to project image features into latent representations and reason between them using a transformer encoder to generate contextualized and scene-consistent representations which are fused with original image features. Our design encourages the latent regions to represent semantic concepts by ensuring that the activated regions are spatially disjoint and the union of such regions corresponds to a connected object segment. The proposed semantic global reasoning (SGR) component is end-to-end trainable and can be easily added to a wide variety of backbones (CNN or transformer-based) and segmentation heads (per-pixel or mask classification) to consistently improve the segmentation results on different datasets. In addition, our latent tokens are semantically interpretable and diverse and provide a rich set of features that can be transferred to downstream tasks like object detection and segmentation, with improved performance. Furthermore, we also proposed metrics to quantify the semantics of latent tokens at both class & instance level.
Read more4/19/2024
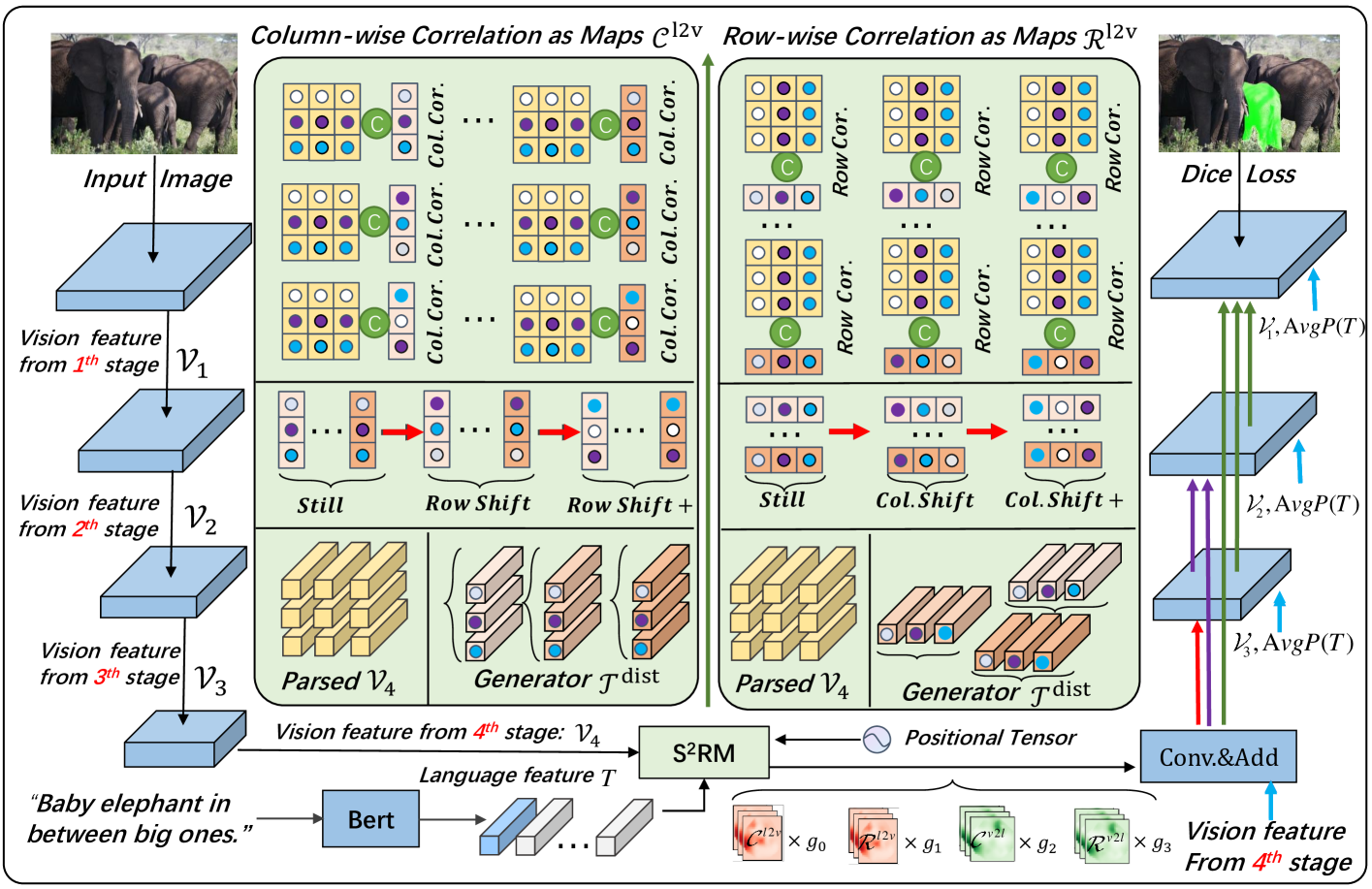
0
Spatial Semantic Recurrent Mining for Referring Image Segmentation
Jiaxing Yang, Lihe Zhang, Jiayu Sun, Huchuan Lu
Referring Image Segmentation (RIS) consistently requires language and appearance semantics to more understand each other. The need becomes acute especially under hard situations. To achieve, existing works tend to resort to various trans-representing mechanisms to directly feed forward language semantic along main RGB branch, which however will result in referent distribution weakly-mined in space and non-referent semantic contaminated along channel. In this paper, we propose Spatial Semantic Recurrent Mining (Stextsuperscript{2}RM) to achieve high-quality cross-modality fusion. It follows a working strategy of trilogy: distributing language feature, spatial semantic recurrent coparsing, and parsed-semantic balancing. During fusion, Stextsuperscript{2}RM will first generate a constraint-weak yet distribution-aware language feature, then bundle features of each row and column from rotated features of one modality context to recurrently correlate relevant semantic contained in feature from other modality context, and finally resort to self-distilled weights to weigh on the contributions of different parsed semantics. Via coparsing, Stextsuperscript{2}RM transports information from the near and remote slice layers of generator context to the current slice layer of parsed context, capable of better modeling global relationship bidirectional and structured. Besides, we also propose a Cross-scale Abstract Semantic Guided Decoder (CASG) to emphasize the foreground of the referent, finally integrating different grained features at a comparatively low cost. Extensive experimental results on four current challenging datasets show that our proposed method performs favorably against other state-of-the-art algorithms.
Read more5/16/2024
🛸
0
Learning Invariant Inter-pixel Correlations for Superpixel Generation
Sen Xu, Shikui Wei, Tao Ruan, Lixin Liao
Deep superpixel algorithms have made remarkable strides by substituting hand-crafted features with learnable ones. Nevertheless, we observe that existing deep superpixel methods, serving as mid-level representation operations, remain sensitive to the statistical properties (e.g., color distribution, high-level semantics) embedded within the training dataset. Consequently, learnable features exhibit constrained discriminative capability, resulting in unsatisfactory pixel grouping performance, particularly in untrainable application scenarios. To address this issue, we propose the Content Disentangle Superpixel (CDS) algorithm to selectively separate the invariant inter-pixel correlations and statistical properties, i.e., style noise. Specifically, We first construct auxiliary modalities that are homologous to the original RGB image but have substantial stylistic variations. Then, driven by mutual information, we propose the local-grid correlation alignment across modalities to reduce the distribution discrepancy of adaptively selected features and learn invariant inter-pixel correlations. Afterwards, we perform global-style mutual information minimization to enforce the separation of invariant content and train data styles. The experimental results on four benchmark datasets demonstrate the superiority of our approach to existing state-of-the-art methods, regarding boundary adherence, generalization, and efficiency. Code and pre-trained model are available at https://github.com/rookiie/CDSpixel.
Read more4/10/2024