Learning Invariant Inter-pixel Correlations for Superpixel Generation

0
🛸
Sign in to get full access
Overview
- Proposes a new algorithm called Content Disentangle Superpixel (CDS) to improve on existing deep superpixel methods
- Aims to selectively separate invariant inter-pixel correlations and statistical properties (style noise) in the training data
- Claims to improve on state-of-the-art methods in boundary adherence, generalization, and efficiency
Plain English Explanation
Deep learning has significantly advanced superpixel algorithms, which group pixels into meaningful regions. However, these existing deep superpixel methods are still influenced by the statistical properties and semantics of the training data they were built on. This can limit their ability to group pixels well, especially in new scenarios not represented in the training data.
To address this, the proposed CDS algorithm tries to separate the invariant (unchanging) relationships between pixels from the statistical (data-dependent) properties of the training set. It does this by first creating auxiliary images that are similar to the original but have very different visual styles. Then, it aligns the feature representations of these auxiliary images to find the common, style-invariant features that can be used for better pixel grouping. Finally, it further separates the content (invariant features) from the style (statistical properties) to improve generalization.
The authors show that this approach outperforms existing methods on standard benchmarks, producing superpixels that better follow object boundaries, work better on new data, and are more efficient to compute.
Technical Explanation
The key innovation of the CDS algorithm is its approach to disentangling the content (invariant inter-pixel correlations) from the style (statistical properties) in the training data.
First, the method constructs auxiliary modalities that are homologous (similar) to the original RGB images but have substantial stylistic variations. This is done using techniques like [object Object] to generate diverse stylistic versions of the input images.
Next, the algorithm uses mutual information - a measure of how much two variables depend on each other - to align the local feature representations across these auxiliary modalities. This local-grid correlation alignment reduces the distribution discrepancy of the adaptively selected features, helping to capture the invariant inter-pixel correlations.
Finally, the method performs global-style mutual information minimization to further enforce the separation of the invariant content and the data-dependent styles. This ensures the learned features are more robust to variations in the training set.
The authors evaluate the CDS algorithm on four benchmark datasets and show it outperforms existing state-of-the-art deep superpixel methods in terms of boundary adherence, generalization to new data, and computational efficiency.
Critical Analysis
The CDS algorithm presents a compelling approach to addressing the limitations of existing deep superpixel methods. By explicitly disentangling content and style, it is able to learn more robust and generalizable feature representations for pixel grouping.
However, the paper does not discuss the potential computational overhead introduced by the auxiliary modality generation and alignment steps. While the authors claim improved efficiency, the additional processing required could be a practical concern, especially for real-time or resource-constrained applications.
Additionally, the evaluation is limited to standard benchmark datasets. It would be valuable to see how the method performs on a wider range of data, including more diverse and challenging scenarios that may better highlight its strengths and weaknesses.
Further research could also explore alternative techniques for disentangling content and style, potentially drawing inspiration from related areas like [object Object] or [object Object].
Conclusion
The CDS algorithm presents a novel approach to deep superpixel segmentation that aims to improve generalization by disentangling the invariant content from the data-dependent style in the training set. By constructing auxiliary modalities and aligning their feature representations, the method is able to learn more robust and transferable pixel grouping features.
While the paper demonstrates promising results on standard benchmarks, further research is needed to fully understand the practical implications and limitations of this approach, especially regarding computational efficiency and performance on diverse real-world scenarios. Nevertheless, the general idea of content-style disentanglement is an interesting direction that could have broader applications in computer vision and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Learning Invariant Inter-pixel Correlations for Superpixel Generation
Sen Xu, Shikui Wei, Tao Ruan, Lixin Liao
Deep superpixel algorithms have made remarkable strides by substituting hand-crafted features with learnable ones. Nevertheless, we observe that existing deep superpixel methods, serving as mid-level representation operations, remain sensitive to the statistical properties (e.g., color distribution, high-level semantics) embedded within the training dataset. Consequently, learnable features exhibit constrained discriminative capability, resulting in unsatisfactory pixel grouping performance, particularly in untrainable application scenarios. To address this issue, we propose the Content Disentangle Superpixel (CDS) algorithm to selectively separate the invariant inter-pixel correlations and statistical properties, i.e., style noise. Specifically, We first construct auxiliary modalities that are homologous to the original RGB image but have substantial stylistic variations. Then, driven by mutual information, we propose the local-grid correlation alignment across modalities to reduce the distribution discrepancy of adaptively selected features and learn invariant inter-pixel correlations. Afterwards, we perform global-style mutual information minimization to enforce the separation of invariant content and train data styles. The experimental results on four benchmark datasets demonstrate the superiority of our approach to existing state-of-the-art methods, regarding boundary adherence, generalization, and efficiency. Code and pre-trained model are available at https://github.com/rookiie/CDSpixel.
Read more4/10/2024
🖼️
0
Superpixel Semantics Representation and Pre-training for Vision-Language Task
Siyu Zhang, Yeming Chen, Yaoru Sun, Fang Wang, Jun Yang, Lizhi Bai, Shangce Gao
The key to integrating visual language tasks is to establish a good alignment strategy. Recently, visual semantic representation has achieved fine-grained visual understanding by dividing grids or image patches. However, the coarse-grained semantic interactions in image space should not be ignored, which hinders the extraction of complex contextual semantic relations at the scene boundaries. This paper proposes superpixels as comprehensive and robust visual primitives, which mine coarse-grained semantic interactions by clustering perceptually similar pixels, speeding up the subsequent processing of primitives. To capture superpixel-level semantic features, we propose a Multiscale Difference Graph Convolutional Network (MDGCN). It allows parsing the entire image as a fine-to-coarse visual hierarchy. To reason actual semantic relations, we reduce potential noise interference by aggregating difference information between adjacent graph nodes. Finally, we propose a multi-level fusion rule in a bottom-up manner to avoid understanding deviation by mining complementary spatial information at different levels. Experiments show that the proposed method can effectively promote the learning of multiple downstream tasks. Encouragingly, our method outperforms previous methods on all metrics. Our code will be released upon publication.
Read more7/23/2024
🖼️
0
Content-decoupled Contrastive Learning-based Implicit Degradation Modeling for Blind Image Super-Resolution
Jiang Yuan, Ji Ma, Bo Wang, Weiming Hu
Implicit degradation modeling-based blind super-resolution (SR) has attracted more increasing attention in the community due to its excellent generalization to complex degradation scenarios and wide application range. How to extract more discriminative degradation representations and fully adapt them to specific image features is the key to this task. In this paper, we propose a new Content-decoupled Contrastive Learning-based blind image super-resolution (CdCL) framework following the typical blind SR pipeline. This framework introduces negative-free contrastive learning technique for the first time to model the implicit degradation representation, in which a new cyclic shift sampling strategy is designed to ensure decoupling between content features and degradation features from the data perspective, thereby improving the purity and discriminability of the learned implicit degradation space. In addition, to improve the efficiency and effectiveness of implicit degradation-based blind super-resolving, we design a detail-aware implicit degradation adaption module with lower complexity, which adapts degradation information to the specific LR image from both channel and spatial perspectives. Extensive experiments on synthetic and real data prove that the proposed CdCL comprehensively improves the quantitative and qualitative results of contrastive learning-based implicit blind SR paradigm, and achieves SOTA PSNR in this field. Even if the number of parameters is halved, our method still achieves very competitive results.
Read more8/13/2024
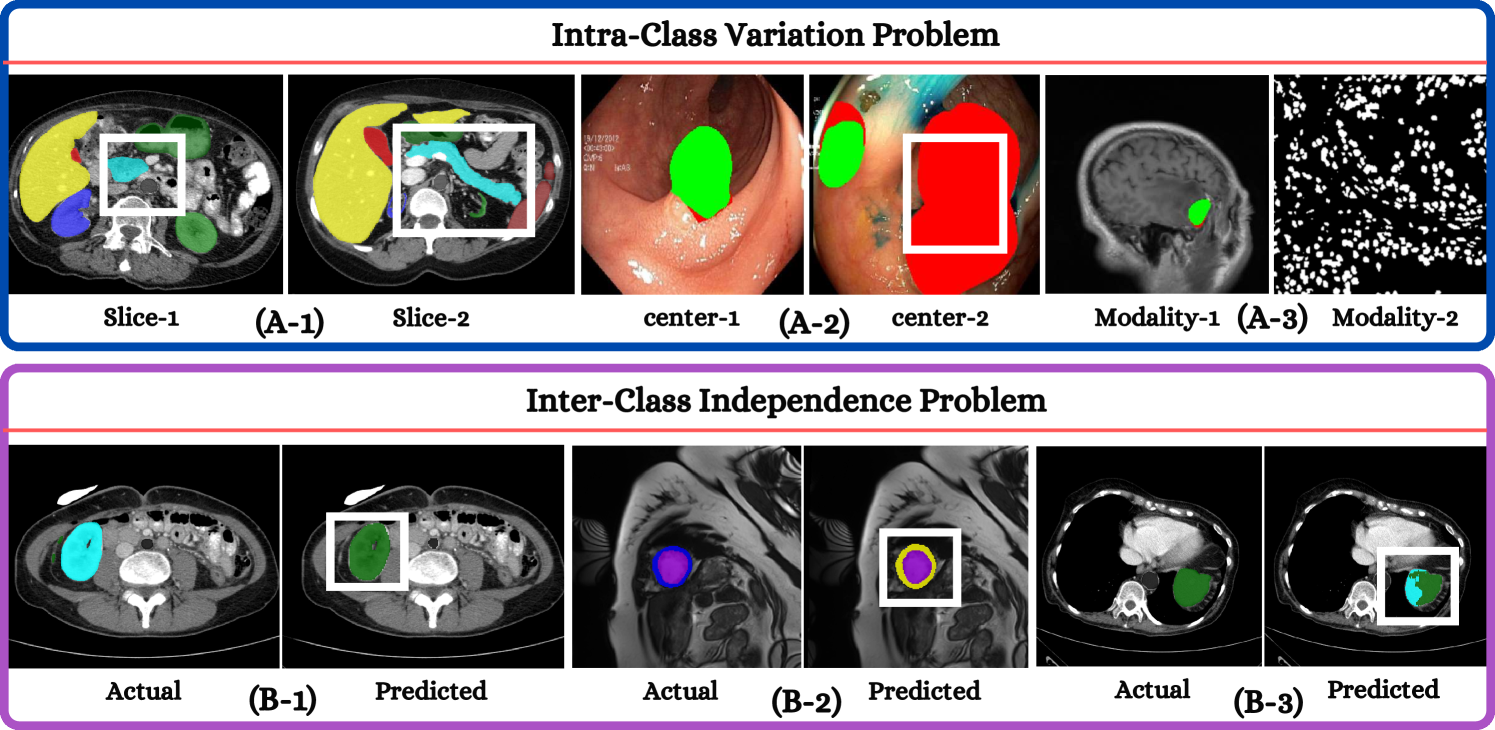
0
Harmonized Spatial and Spectral Learning for Robust and Generalized Medical Image Segmentation
Vandan Gorade, Sparsh Mittal, Debesh Jha, Rekha Singhal, Ulas Bagci
Deep learning has demonstrated remarkable achievements in medical image segmentation. However, prevailing deep learning models struggle with poor generalization due to (i) intra-class variations, where the same class appears differently in different samples, and (ii) inter-class independence, resulting in difficulties capturing intricate relationships between distinct objects, leading to higher false negative cases. This paper presents a novel approach that synergies spatial and spectral representations to enhance domain-generalized medical image segmentation. We introduce the innovative Spectral Correlation Coefficient objective to improve the model's capacity to capture middle-order features and contextual long-range dependencies. This objective complements traditional spatial objectives by incorporating valuable spectral information. Extensive experiments reveal that optimizing this objective with existing architectures like UNet and TransUNet significantly enhances generalization, interpretability, and noise robustness, producing more confident predictions. For instance, in cardiac segmentation, we observe a 0.81 pp and 1.63 pp (pp = percentage point) improvement in DSC over UNet and TransUNet, respectively. Our interpretability study demonstrates that, in most tasks, objectives optimized with UNet outperform even TransUNet by introducing global contextual information alongside local details. These findings underscore the versatility and effectiveness of our proposed method across diverse imaging modalities and medical domains.
Read more8/9/2024