SuperPos-Prompt: Enhancing Soft Prompt Tuning of Language Models with Superposition of Multi Token Embeddings

0

Sign in to get full access
Overview
- This paper introduces a novel approach called "SuperPos-Prompt" that enhances soft prompt tuning of language models by leveraging the superposition of multi-token embeddings.
- Soft prompt tuning is a popular technique for adapting large language models to specific tasks, but it can be computationally expensive and have limited performance.
- The SuperPos-Prompt method aims to improve the efficiency and effectiveness of soft prompt tuning by incorporating information from multiple tokens within the prompt.
Plain English Explanation
The paper presents a new way to fine-tune or "train" large language models like GPT-3 to perform specific tasks, such as answering questions or generating text. The key idea is to use a "prompt" - a short sequence of words that guides the model to produce the desired output.
Traditional prompt tuning methods only consider the embedding (numerical representation) of the entire prompt as a single unit. In contrast, the SuperPos-Prompt approach looks at the embeddings of individual words within the prompt. It then combines or "superimposes" these individual word embeddings to create a more informative prompt representation.
The researchers hypothesize that this multi-token approach can lead to better performance and greater efficiency compared to standard prompt tuning. For example, it may allow the model to learn more generalizable patterns from the prompt, rather than relying solely on the specific word sequence.
By incorporating additional information from the prompt's internal structure, the SuperPos-Prompt method aims to enhance the versatility and power of soft prompt tuning, making it a more useful tool for adapting large language models to a wide range of tasks.
Technical Explanation
The SuperPos-Prompt approach builds on the concept of soft prompt tuning, where a small number of prompt tokens are learned and added to the input of a pre-trained language model to adapt it to a specific task.
Instead of treating the prompt as a single entity, the authors propose to represent it as a superposition of the embeddings of its constituent tokens. This is achieved by summing the individual token embeddings, which are then used as the prompt input to the language model.
The key advantages of this method are:
- Increased Expressivity: By considering the internal structure of the prompt, the model can learn more expressive representations that capture relationships between the prompt tokens.
- Improved Efficiency: The superposition approach requires fewer trainable parameters compared to standard soft prompt tuning, as it does not need to learn a separate embedding for the entire prompt.
- Better Generalization: The model can learn more generalizable patterns from the prompt, as it is not constrained to the specific word sequence.
The authors evaluate the SuperPos-Prompt approach on a range of language modeling tasks, including text generation, question answering, and retrieval-augmented generation. The results demonstrate consistent improvements in performance and efficiency compared to traditional soft prompt tuning methods, such as Efficient Prompt Tuning by Multi-Space Projection and APrompt4EM: Augmented Prompt Tuning for Generalized Entity Matching.
Critical Analysis
The SuperPos-Prompt approach presents a promising advancement in the field of prompt tuning, with several key strengths:
- Improved Efficiency: The reduced number of trainable parameters can make the method more practical for real-world applications, especially when computational resources are limited.
- Better Generalization: The ability to capture more expressive representations of the prompt can lead to improved model performance and adaptability to different tasks.
- Broader Applicability: The authors demonstrate the effectiveness of their approach across a range of language modeling tasks, suggesting its potential for widespread use.
However, the paper also acknowledges several limitations and areas for further research:
- Task and Domain Dependence: The performance gains may be influenced by the specific tasks and datasets used in the experiments, and the method's effectiveness may vary in different domains or applications.
- Theoretical Understanding: The precise mechanisms underlying the improved performance and efficiency are not fully explained, and a deeper theoretical analysis could provide valuable insights.
- Scalability and Robustness: The paper does not explore the behavior of the SuperPos-Prompt method as the prompt length or the size of the language model increases, which could be important considerations for real-world deployments.
Further research addressing these limitations, as well as exploring the potential synergies between SuperPos-Prompt and other prompt tuning techniques, such as Multi-Prompt Depth-Partitioned Cross-Modal Learning or Plug and Play Prompts, could further strengthen the applicability and impact of this innovative approach.
Conclusion
The SuperPos-Prompt method presented in this paper offers a novel and promising approach to enhancing soft prompt tuning of language models. By leveraging the superposition of multi-token embeddings, the technique demonstrates improved performance and efficiency compared to traditional prompt tuning methods.
The ability to capture more expressive representations of the prompt, while requiring fewer trainable parameters, makes the SuperPos-Prompt approach a valuable tool for adapting large language models to a wide range of tasks. As the field of prompt-based learning continues to evolve, this work highlights the potential benefits of considering the internal structure of prompts and could inspire further innovations in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SuperPos-Prompt: Enhancing Soft Prompt Tuning of Language Models with Superposition of Multi Token Embeddings
MohammadAli SadraeiJavaeri, Ehsaneddin Asgari, Alice Carolyn McHardy, Hamid Reza Rabiee
Soft prompt tuning techniques have recently gained traction as an effective strategy for the parameter-efficient tuning of pretrained language models, particularly minimizing the required adjustment of model parameters. Despite their growing use, achieving optimal tuning with soft prompts, especially for smaller datasets, remains a substantial challenge. This study makes two contributions in this domain: (i) we introduce SuperPos-Prompt, a new reparameterization technique employing the superposition of multiple pretrained vocabulary embeddings to improve the learning of soft prompts. Our experiments across several GLUE and SuperGLUE benchmarks consistently highlight SuperPos-Prompt's superiority over Residual Prompt tuning, exhibiting an average score increase of $+6.4$ in T5-Small and $+5.0$ in T5-Base along with a faster convergence. Remarkably, SuperPos-Prompt occasionally outperforms even full fine-tuning methods. (ii) Additionally, we demonstrate enhanced performance and rapid convergence by omitting dropouts from the frozen network, yielding consistent improvements across various scenarios and tuning methods.
Read more6/11/2024
0
Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
Thomas Merth, Qichen Fu, Mohammad Rastegari, Mahyar Najibi
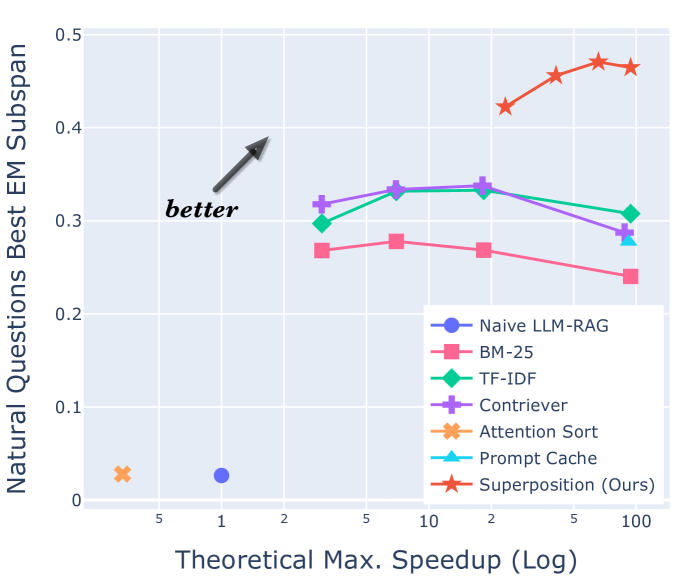
Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequence length, making it expensive for deployment in some real-world text processing applications, such as retrieval-augmented generation (RAG). Additionally, LLMs also exhibit the distraction phenomenon, where irrelevant context in the prompt degrades output quality. To address these drawbacks, we propose a novel RAG prompting methodology, *superposition prompting*, which can be directly applied to pre-trained transformer-based LLMs *without the need for fine-tuning*. At a high level, superposition prompting allows the LLM to process input documents in parallel *prompt paths*, discarding paths once they are deemed irrelevant. We demonstrate the capability of our method to simultaneously enhance time efficiency across a variety of question-answering benchmarks using multiple pre-trained LLMs. Furthermore, our technique significantly improves accuracy when the retrieved context is large relative the context the model was trained on. For example, our approach facilitates a 93x reduction in compute time while *improving* accuracy by 43% on the NaturalQuestions-Open dataset with the MPT-7B instruction-tuned model over naive RAG.
Read more7/22/2024
💬
0
Soft Prompt Tuning for Augmenting Dense Retrieval with Large Language Models
Zhiyuan Peng, Xuyang Wu, Qifan Wang, Yi Fang
Dense retrieval (DR) converts queries and documents into dense embeddings and measures the similarity between queries and documents in vector space. One of the challenges in DR is the lack of domain-specific training data. While DR models can learn from large-scale public datasets like MS MARCO through transfer learning, evidence shows that not all DR models and domains can benefit from transfer learning equally. Recently, some researchers have resorted to large language models (LLMs) to improve the zero-shot and few-shot DR models. However, the hard prompts or human-written prompts utilized in these works cannot guarantee the good quality of generated weak queries. To tackle this, we propose soft prompt tuning for augmenting DR (SPTAR): For each task, we leverage soft prompt-tuning to optimize a task-specific soft prompt on limited ground truth data and then prompt the LLMs to tag unlabeled documents with weak queries, yielding enough weak document-query pairs to train task-specific dense retrievers. We design a filter to select high-quality example document-query pairs in the prompt to further improve the quality of weak tagged queries. To the best of our knowledge, there is no prior work utilizing soft prompt tuning to augment DR models. The experiments demonstrate that SPTAR outperforms the unsupervised baselines BM25 and the recently proposed LLMs-based augmentation method for DR.
Read more6/18/2024

0
Efficient Prompt Tuning by Multi-Space Projection and Prompt Fusion
Pengxiang Lan, Enneng Yang, Yuting Liu, Guibing Guo, Linying Jiang, Jianzhe Zhao, Xingwei Wang
Prompt tuning is a promising method to fine-tune a pre-trained language model without retraining its large-scale parameters. Instead, it attaches a soft prompt to the input text, whereby downstream tasks can be well adapted by merely learning the embeddings of prompt tokens. Nevertheless, existing methods still suffer from two challenges: (i) they are hard to balance accuracy and efficiency. A longer (shorter) soft prompt generally leads to a better(worse) accuracy but at the cost of more (less) training time. (ii)The performance may not be consistent when adapting to different downstream tasks. We attribute it to the same embedding space but responsible for different requirements of downstream tasks. To address these issues, we propose an Efficient Prompt Tuning method (EPT) by multi-space projection and prompt fusion. Specifically, it decomposes a given soft prompt into a shorter prompt and two low-rank matrices, significantly reducing the training time. Accuracy is also enhanced by leveraging low-rank matrices and the short prompt as additional knowledge sources to enrich the semantics of the original short prompt. In addition, we project the soft prompt into multiple subspaces to improve the performance consistency, and then adaptively learn the combination weights of different spaces through a gating network. Experiments on 13 natural language processing downstream tasks show that our method significantly and consistently outperforms 11 comparison methods with the relative percentage of improvements up to 12.9%, and training time decreased by 14%.
Read more7/2/2024