Modeling Uncertainty and Using Post-fusion as Fallback Improves Retrieval Augmented Generation with LLMs
2308.12574
0
0
🛸
Abstract
The integration of retrieved passages and large language models (LLMs), such as ChatGPTs, has significantly contributed to improving open-domain question answering. However, there is still a lack of exploration regarding the optimal approach for incorporating retrieved passages into the answer generation process. This paper aims to fill this gap by investigating different methods of combining retrieved passages with LLMs to enhance answer generation. We begin by examining the limitations of a commonly-used concatenation approach. Surprisingly, this approach often results in generating unknown outputs, even when the correct document is among the top-k retrieved passages. To address this issue, we explore four alternative strategies for integrating the retrieved passages with the LLMs. These strategies include two single-round methods that utilize chain-of-thought reasoning and two multi-round strategies that incorporate feedback loops. Through comprehensive analyses and experiments, we provide insightful observations on how to effectively leverage retrieved passages to enhance the answer generation capability of LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores different methods of integrating retrieved passages with large language models (LLMs) like ChatGPT to enhance open-domain question answering.
- The authors examine the limitations of a commonly-used concatenation approach and propose four alternative strategies to effectively leverage retrieved passages for improved answer generation.
- The paper provides insightful observations on how to effectively combine retrieved passages with LLMs to enhance their answer generation capabilities.
Plain English Explanation
When trying to answer open-ended questions, researchers have found that combining the knowledge from large language models (LLMs) like ChatGPT with relevant information from retrieved passages can significantly improve the quality of the answers. However, the best way to incorporate this retrieved information into the answer generation process is still an open question.
This paper explores different strategies for integrating retrieved passages with LLMs to enhance their ability to provide accurate and informative answers. The authors start by looking at a common approach called "concatenation," where the retrieved passages are simply added to the input for the LLM. They find that this approach often leads to the model generating unknown or irrelevant outputs, even when the correct information is present in the retrieved passages.
To address this issue, the researchers propose four alternative methods for combining the retrieved passages with the LLMs. Two of these are "single-round" approaches that use chain-of-thought reasoning, while the other two are "multi-round" strategies that incorporate feedback loops. Through detailed analysis and experiments, the authors provide valuable insights on how to effectively leverage the retrieved passages to improve the answer generation capabilities of LLMs.
Technical Explanation
The paper begins by examining the limitations of a commonly-used concatenation approach for incorporating retrieved passages into LLM-based open-domain question answering. In this approach, the retrieved passages are simply appended to the original question, and the LLM is then tasked with generating an answer based on the combined input. The authors find that this method often results in the model generating unknown or irrelevant outputs, even when the correct information is present in the top-k retrieved passages.
To address this issue, the researchers explore four alternative strategies for integrating the retrieved passages with the LLMs:
-
Single-round Methods: a. Passage Ranking: The LLM is used to rank the relevance of the retrieved passages, and the top-ranked passage is then used to generate the final answer. b. Passage Reasoning: The LLM is instructed to engage in chain-of-thought reasoning by first summarizing the key information from the retrieved passages, and then using that summary to generate the final answer.
-
Multi-round Methods: a. Iterative Refinement: The LLM generates an initial answer, which is then used to retrieve more relevant passages. The model then refines the answer based on the additional information. b. Passage-guided Refinement: The LLM generates an initial answer, which is then used to retrieve more relevant passages. The model then engages in a feedback loop to refine the answer based on the additional information.
Through comprehensive analyses and experiments, the authors provide valuable insights into the strengths and weaknesses of these different approaches. They offer guidance on how to effectively leverage retrieved passages to enhance the answer generation capabilities of LLMs, with potential implications for improving the overall performance of open-domain question answering systems.
Critical Analysis
The paper presents a thorough investigation of various methods for integrating retrieved passages with LLMs to enhance open-domain question answering. The authors' recognition of the limitations of the commonly-used concatenation approach and their exploration of alternative strategies are commendable.
One potential limitation of the research is the scope of the experiments, which may not fully capture the nuances and complexities of real-world open-domain question answering tasks. While the proposed methods show promising results in the controlled experimental settings, it would be valuable to see how they perform in more diverse and challenging scenarios, such as those involving complex reasoning, multi-step problem-solving, or cross-domain knowledge.
Additionally, the paper does not delve into the potential biases or limitations of the LLMs themselves, which could impact the effectiveness of the integration strategies. It would be beneficial to further explore the interplay between the LLM's inherent capabilities, limitations, and the passage integration methods to gain a more comprehensive understanding of the system's overall performance.
Furthermore, the paper focuses on improving the answer generation process, but it does not address the important issue of answer grounding or the LLM's ability to distinguish between factual information and generated content. Exploring strategies to enhance the model's capacity to reliably distinguish between these two aspects could be a valuable direction for future research.
Despite these potential limitations, the paper provides a solid foundation for understanding the challenges and potential solutions in combining retrieved passages with LLMs for open-domain question answering. The insights and strategies presented in this work can serve as a valuable starting point for further research and development in this important area of AI.
Conclusion
This paper investigates different methods for integrating retrieved passages with large language models (LLMs) to improve open-domain question answering. The authors identify the limitations of a commonly-used concatenation approach and propose four alternative strategies, including single-round and multi-round techniques, to effectively leverage the information in retrieved passages.
Through comprehensive analyses and experiments, the researchers provide valuable insights on how to effectively combine retrieved passages with LLMs to enhance their answer generation capabilities. These findings have the potential to significantly improve the performance of open-domain question answering systems, which are crucial for a wide range of applications, from personal digital assistants to knowledge-intensive services.
The paper lays the groundwork for further exploration of the interplay between LLMs and retrieved information, with opportunities to address broader challenges, such as grounding and cross-domain reasoning. As the field of AI continues to evolve, this research contributes valuable insights that can help shape the development of more robust and reliable question answering systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
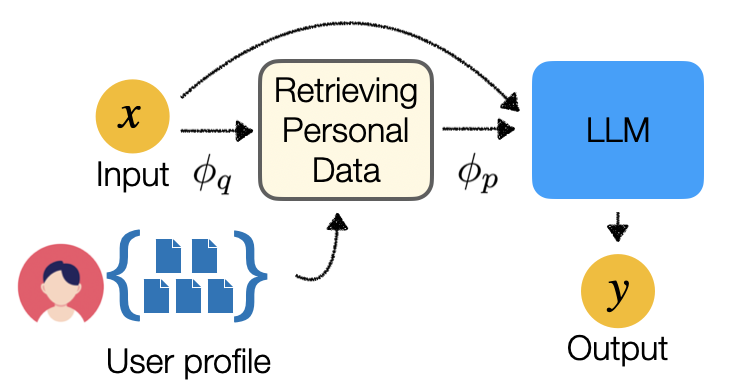
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
0
0
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
4/10/2024
💬
Redefining Information Retrieval of Structured Database via Large Language Models
Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Juanyi Yang, Hong Zhang
0
0
Retrieval augmentation is critical when Language Models (LMs) exploit non-parametric knowledge related to the query through external knowledge bases before reasoning. The retrieved information is incorporated into LMs as context alongside the query, enhancing the reliability of responses towards factual questions. Prior researches in retrieval augmentation typically follow a retriever-generator paradigm. In this context, traditional retrievers encounter challenges in precisely and seamlessly extracting query-relevant information from knowledge bases. To address this issue, this paper introduces a novel retrieval augmentation framework called ChatLR that primarily employs the powerful semantic understanding ability of Large Language Models (LLMs) as retrievers to achieve precise and concise information retrieval. Additionally, we construct an LLM-based search and question answering system tailored for the financial domain by fine-tuning LLM on two tasks including Text2API and API-ID recognition. Experimental results demonstrate the effectiveness of ChatLR in addressing user queries, achieving an overall information retrieval accuracy exceeding 98.8%.
5/10/2024
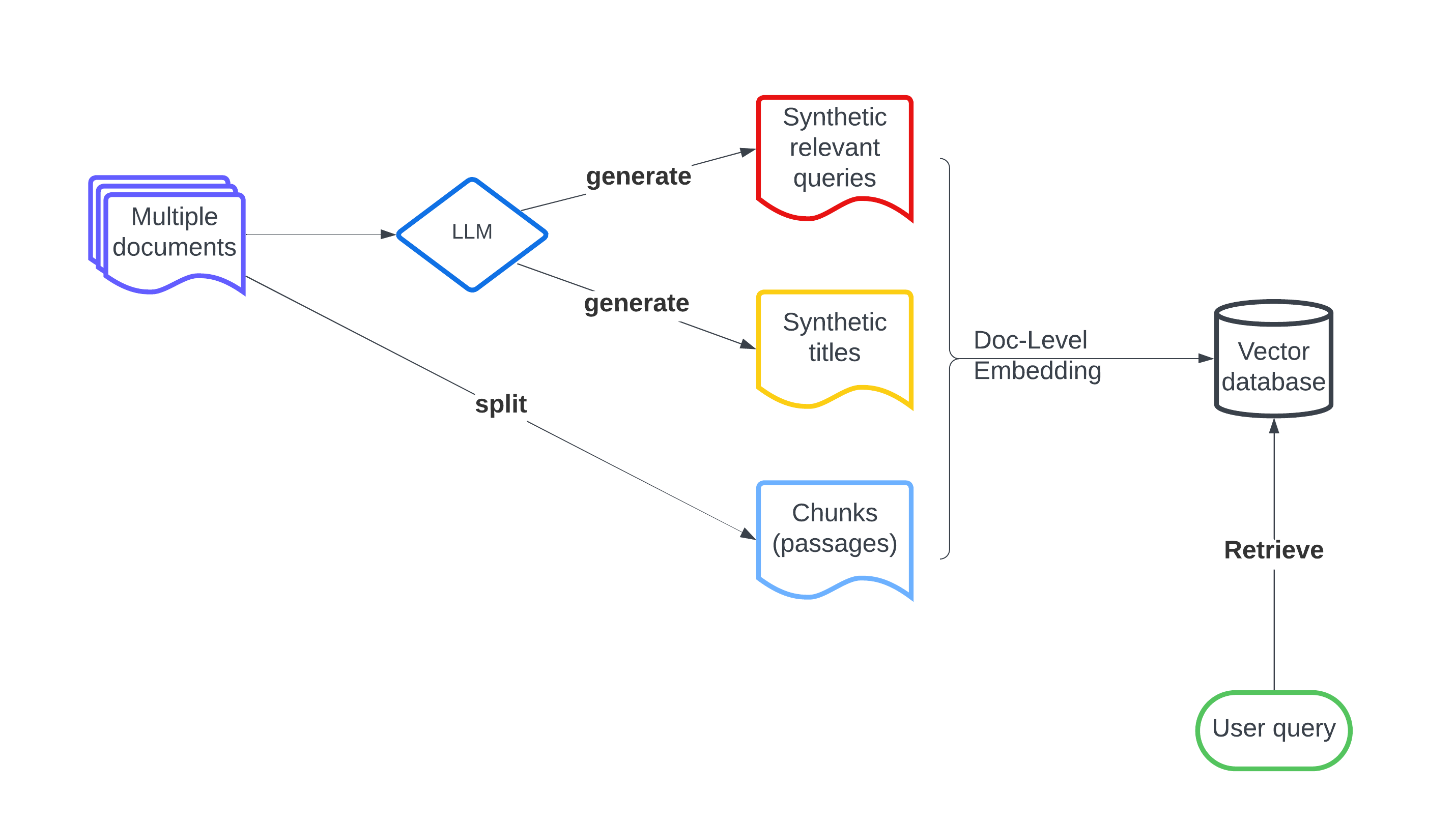
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024
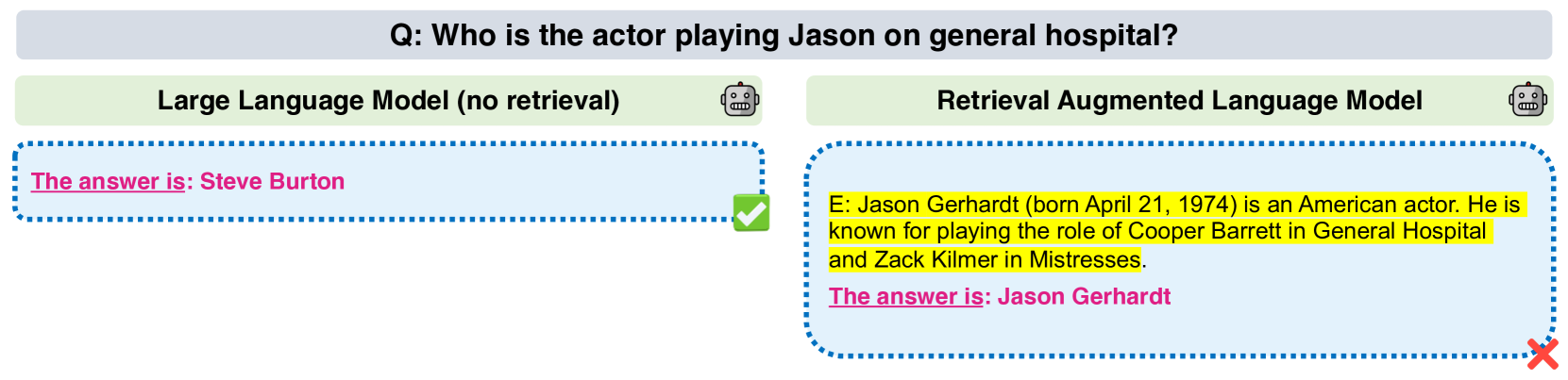
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
0
0
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
5/7/2024