Systematic Assessment of Tabular Data Synthesis Algorithms
2402.06806
0
0
Abstract
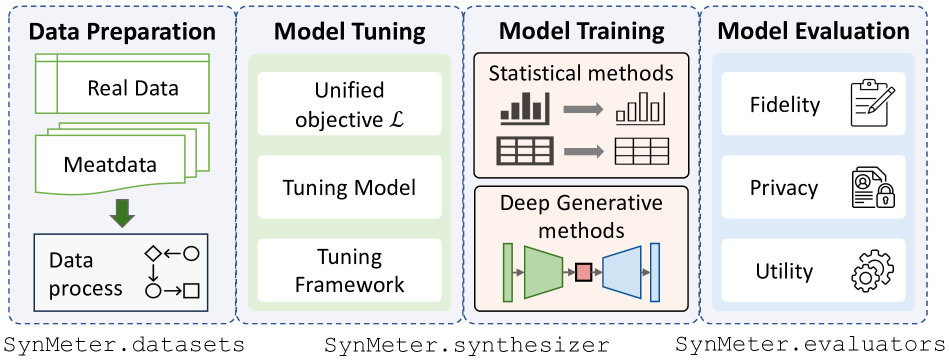
Data synthesis has been advocated as an important approach for utilizing data while protecting data privacy. A large number of tabular data synthesis algorithms (which we call synthesizers) have been proposed. Some synthesizers satisfy Differential Privacy, while others aim to provide privacy in a heuristic fashion. A comprehensive understanding of the strengths and weaknesses of these synthesizers remains elusive due to drawbacks in evaluation metrics and missing head-to-head comparisons of newly developed synthesizers that take advantage of diffusion models and large language models with state-of-the-art marginal-based synthesizers. In this paper, we present a systematic evaluation framework for assessing tabular data synthesis algorithms. Specifically, we examine and critique existing evaluation metrics, and introduce a set of new metrics in terms of fidelity, privacy, and utility to address their limitations. Based on the proposed metrics, we also devise a unified objective for tuning, which can consistently improve the quality of synthetic data for all methods. We conducted extensive evaluations of 8 different types of synthesizers on 12 real-world datasets and identified some interesting findings, which offer new directions for privacy-preserving data synthesis.
Create account to get full access
Overview
- This paper proposes a framework for evaluating the performance of tabular data synthesis algorithms.
- The authors argue that existing evaluation methods are limited and lack a principled approach.
- The framework aims to provide a more comprehensive and standardized way to assess the quality and utility of synthetic data generated by these algorithms.
Plain English Explanation
The paper discusses the challenge of evaluating the performance of algorithms that generate synthetic tabular data. Tabular data is a common format for data, where information is arranged in rows and columns, like a spreadsheet. These algorithms are designed to create new datasets that mimic the statistical properties of the original data, while protecting the privacy of the individuals represented in the data.
The authors explain that current methods for evaluating these algorithms are often limited and lack a clear, standardized approach. This makes it difficult to compare different algorithms and understand their strengths and weaknesses. To address this, the paper proposes a new framework that provides a more comprehensive and rigorous way to assess the quality and utility of the synthetic data produced by these algorithms.
The framework considers various aspects of the synthetic data, such as its statistical similarity to the original data, its ability to preserve key relationships and patterns, and its usefulness for downstream tasks like machine learning. By using this framework, researchers and developers can better evaluate the performance of their tabular data synthesis algorithms and identify areas for improvement.
Technical Explanation
The paper presents a framework for evaluating tabular data synthesis algorithms, which are used to create new datasets that mimic the statistical properties of the original data while protecting individual privacy. The authors argue that existing evaluation methods are often limited and lack a principled approach, making it difficult to compare different algorithms and understand their strengths and weaknesses.
The proposed framework considers multiple dimensions of synthetic data quality, including:
- Statistical similarity: How well the synthetic data matches the statistical properties of the original data, such as means, variances, and correlations.
- Pattern preservation: The ability of the synthetic data to preserve key relationships and patterns present in the original data.
- Utility for downstream tasks: The usefulness of the synthetic data for tasks like machine learning, where the data is used as input.
The framework also includes measures for assessing the privacy-preserving properties of the synthetic data, such as the differential privacy of the generation process.
To demonstrate the framework, the authors apply it to several state-of-the-art tabular data synthesis algorithms, including Balanced Mixed-Type Tabular Data Synthesis and SiloFuse. The results show that the framework can provide a more comprehensive and standardized way to evaluate the performance of these algorithms, helping researchers and developers to improve the quality and utility of their synthetic data.
Critical Analysis
The proposed framework is a valuable contribution to the field of tabular data synthesis, as it addresses the limitations of existing evaluation methods. By considering multiple dimensions of data quality and utility, the framework provides a more holistic assessment of the performance of these algorithms.
However, the authors acknowledge that the framework has some limitations. For example, it may not fully capture all the nuances of certain types of data or downstream tasks, and the choice of specific metrics and weightings can be subjective. Additionally, the framework does not address the potential for bias or skew in the original data, which could be propagated to the synthetic data.
Further research could explore ways to make the framework more adaptive and customizable, allowing users to prioritize different aspects of data quality based on their specific needs and applications. It would also be useful to see the framework applied to a wider range of data synthesis algorithms and real-world use cases to further validate its effectiveness.
Conclusion
This paper presents a comprehensive framework for evaluating the performance of tabular data synthesis algorithms. By considering multiple dimensions of data quality and utility, the framework provides a more standardized and principled approach to assessing the strengths and weaknesses of these algorithms.
The proposed framework has the potential to significantly improve the development and deployment of tabular data synthesis algorithms, as it enables researchers and developers to better understand the trade-offs and optimize the performance of their algorithms. This, in turn, could lead to more accurate and useful synthetic data that preserves the statistical properties of the original data while protecting individual privacy.
Overall, this research represents an important step towards more rigorous and effective evaluation of tabular data synthesis algorithms, with implications for a wide range of data-driven applications and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Navigating Tabular Data Synthesis Research: Understanding User Needs and Tool Capabilities
Maria F. Davila R., Sven Groen, Fabian Panse, Wolfram Wingerath
0
0
In an era of rapidly advancing data-driven applications, there is a growing demand for data in both research and practice. Synthetic data have emerged as an alternative when no real data is available (e.g., due to privacy regulations). Synthesizing tabular data presents unique and complex challenges, especially handling (i) missing values, (ii) dataset imbalance, (iii) diverse column types, and (iv) complex data distributions, as well as preserving (i) column correlations, (ii) temporal dependencies, and (iii) integrity constraints (e.g., functional dependencies) present in the original dataset. While substantial progress has been made recently in the context of generational models, there is no one-size-fits-all solution for tabular data today, and choosing the right tool for a given task is therefore no trivial task. In this paper, we survey the state of the art in Tabular Data Synthesis (TDS), examine the needs of users by defining a set of functional and non-functional requirements, and compile the challenges associated with meeting those needs. In addition, we evaluate the reported performance of 36 popular research TDS tools about these requirements and develop a decision guide to help users find suitable TDS tools for their applications. The resulting decision guide also identifies significant research gaps.
6/3/2024
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
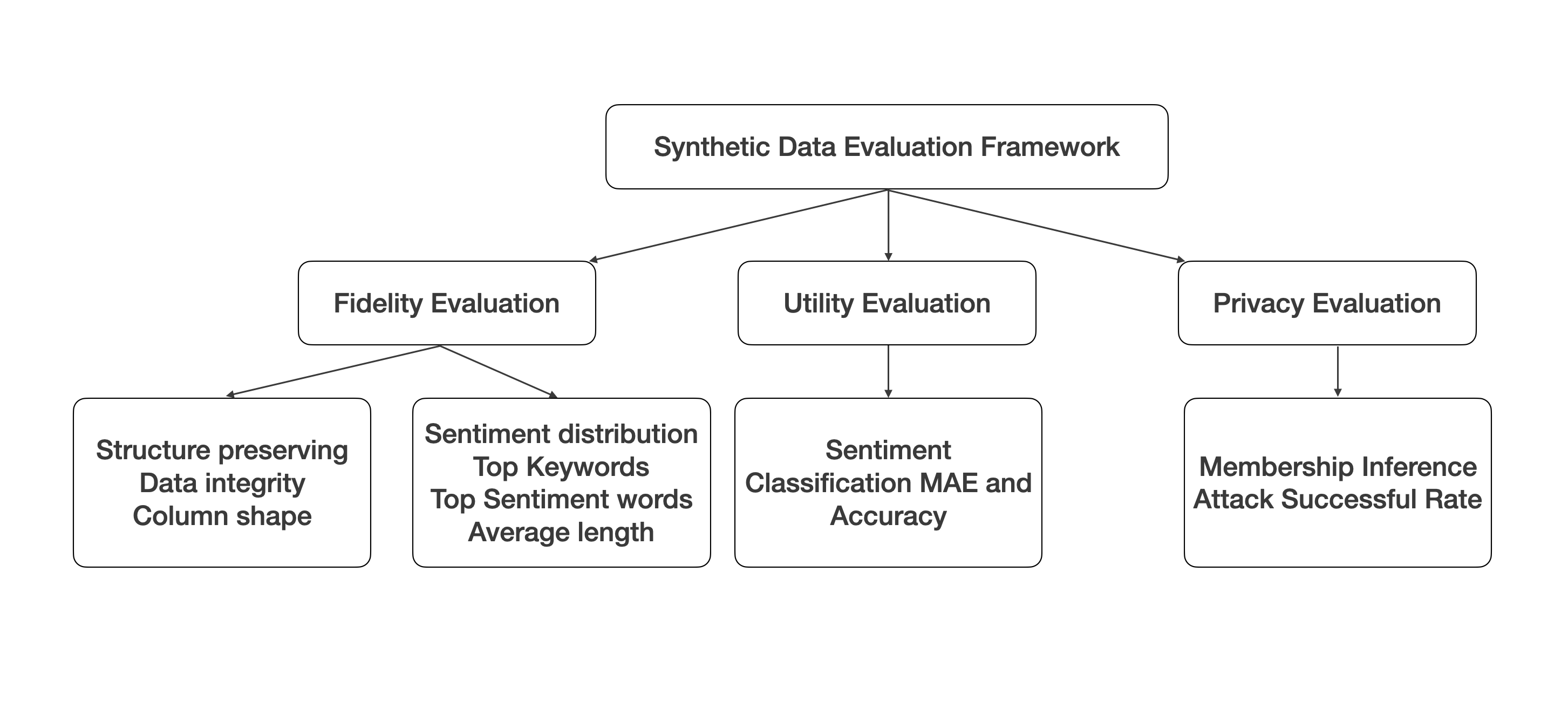
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024
Structured Evaluation of Synthetic Tabular Data
Scott Cheng-Hsin Yang, Baxter Eaves, Michael Schmidt, Ken Swanson, Patrick Shafto
0
0
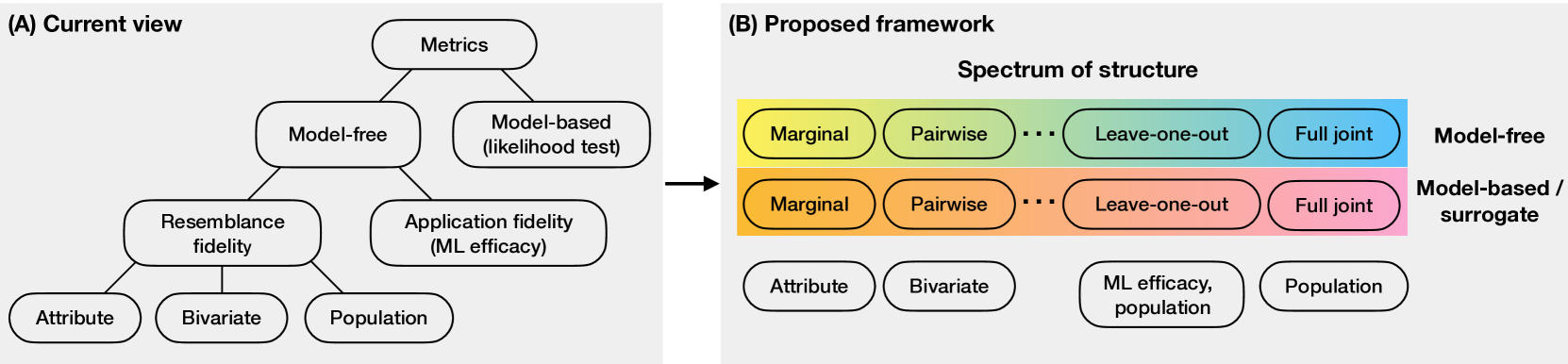
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
4/1/2024
👨🏫
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
0
0
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
5/13/2024