Structured Evaluation of Synthetic Tabular Data
2403.10424
0
0
Abstract
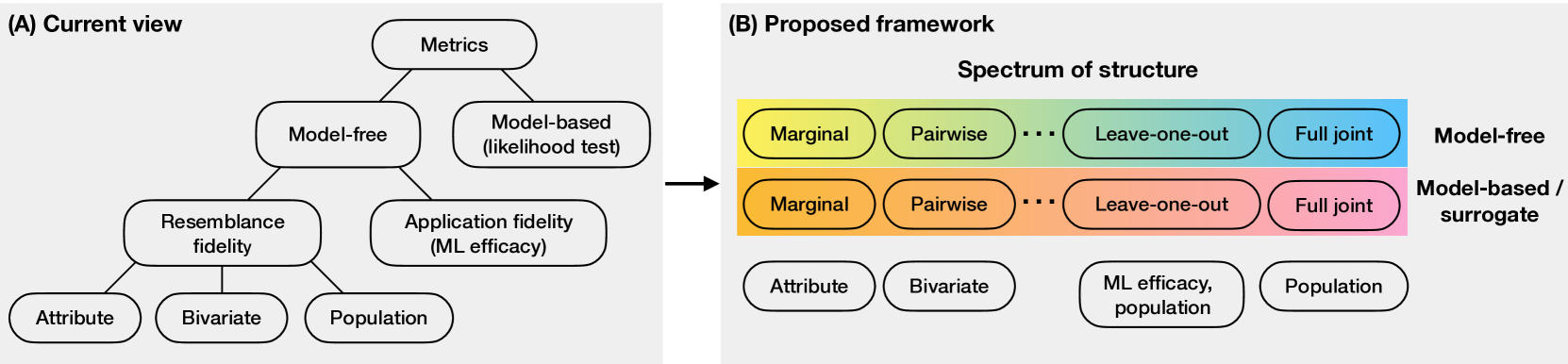
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
Create account to get full access
Overview
- This paper presents a structured framework for evaluating the quality of synthetic tabular data generated by machine learning models.
- The authors argue that existing evaluation methods are limited and propose a more comprehensive approach to assess the statistical and semantic properties of synthetic data.
- The framework includes a set of metrics to measure different aspects of the synthetic data, such as how well it captures the relationships between variables and how realistic it appears to human evaluators.
- The authors demonstrate the effectiveness of their framework by applying it to evaluate synthetic data generated by several popular data synthesis models.
Plain English Explanation
Imagine you want to create a model that can generate fake data that looks and behaves just like real data. This could be useful for things like training other AI systems or testing software without using sensitive real-world information.
The challenge is figuring out how to properly evaluate whether the fake data is any good. Existing methods tend to be limited - they might just check if the fake data has the same basic statistical properties as the real data, but that doesn't tell the whole story.
This paper proposes a more comprehensive framework for evaluating synthetic data. The key idea is to look at both the statistical properties and the semantic, or meaningful, relationships between the variables in the data. The framework includes a set of metrics that can measure things like:
- How well the fake data captures the connections between different variables, just like in the real data
- How realistic the fake data looks to human evaluators
By applying this framework, the researchers were able to get a much richer understanding of the strengths and weaknesses of several popular data synthesis models. This can help developers build better models that generate even more realistic and useful synthetic data.
Technical Explanation
The paper introduces a structured evaluation framework for assessing the quality of synthetic tabular data generated by machine learning models. The authors argue that existing evaluation methods, such as comparing basic statistical properties, are insufficient for fully capturing the fidelity of synthetic data.
The proposed framework includes a suite of metrics across three main categories:
- Statistical fidelity: Measures how well the statistical distributions and correlations in the synthetic data match the real data.
- Semantic fidelity: Evaluates whether the synthetic data preserves the meaningful relationships between variables, as perceived by human annotators.
- Visual fidelity: Assesses how realistic the synthetic data appears to human raters.
The authors demonstrate the application of this framework by evaluating the outputs of several state-of-the-art data synthesis models, including CTGAN, TVAE, and SGAN. They find that different models excel at different aspects of fidelity, highlighting the need for a multifaceted evaluation approach.
The results show that the proposed framework provides a more nuanced and informative assessment of synthetic data quality compared to traditional evaluation metrics. The authors argue this can guide the development of improved data synthesis techniques and help users better understand the strengths and limitations of various models.
Critical Analysis
The structured evaluation framework presented in this paper is a valuable contribution to the field of synthetic data generation. By expanding the assessment beyond just statistical properties, the authors provide a more comprehensive way to assess the quality and usefulness of synthetic data.
That said, the framework does have some limitations. The semantic fidelity evaluation relies on human raters, which can introduce subjectivity and potential biases. Additionally, the framework does not address potential privacy or security concerns that may arise from the use of synthetic data.
Further research could explore automating parts of the semantic fidelity evaluation, perhaps by leveraging large language models to assess the meaningfulness of variable relationships. Investigating the robustness of the framework to different types of tabular data and synthesis techniques would also be valuable.
Overall, this paper represents an important step forward in the rigorous evaluation of synthetic data. As the use of synthetic data continues to grow, frameworks like this will be crucial for ensuring the quality and responsible application of these powerful techniques.
Conclusion
This paper presents a structured evaluation framework for assessing the quality of synthetic tabular data generated by machine learning models. By considering not just statistical properties but also semantic and visual fidelity, the framework provides a more comprehensive way to evaluate the usefulness and realism of synthetic data.
The authors demonstrate the application of this framework on several state-of-the-art data synthesis models, revealing strengths and weaknesses that would be difficult to uncover using traditional evaluation methods. This insight can guide the development of improved data synthesis techniques and help users make more informed decisions about which models to use for their specific needs.
As the use of synthetic data continues to grow, rigorous evaluation frameworks like the one proposed in this paper will be essential for ensuring the quality and responsible application of these powerful techniques. The authors have laid an important foundation for further research and innovation in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
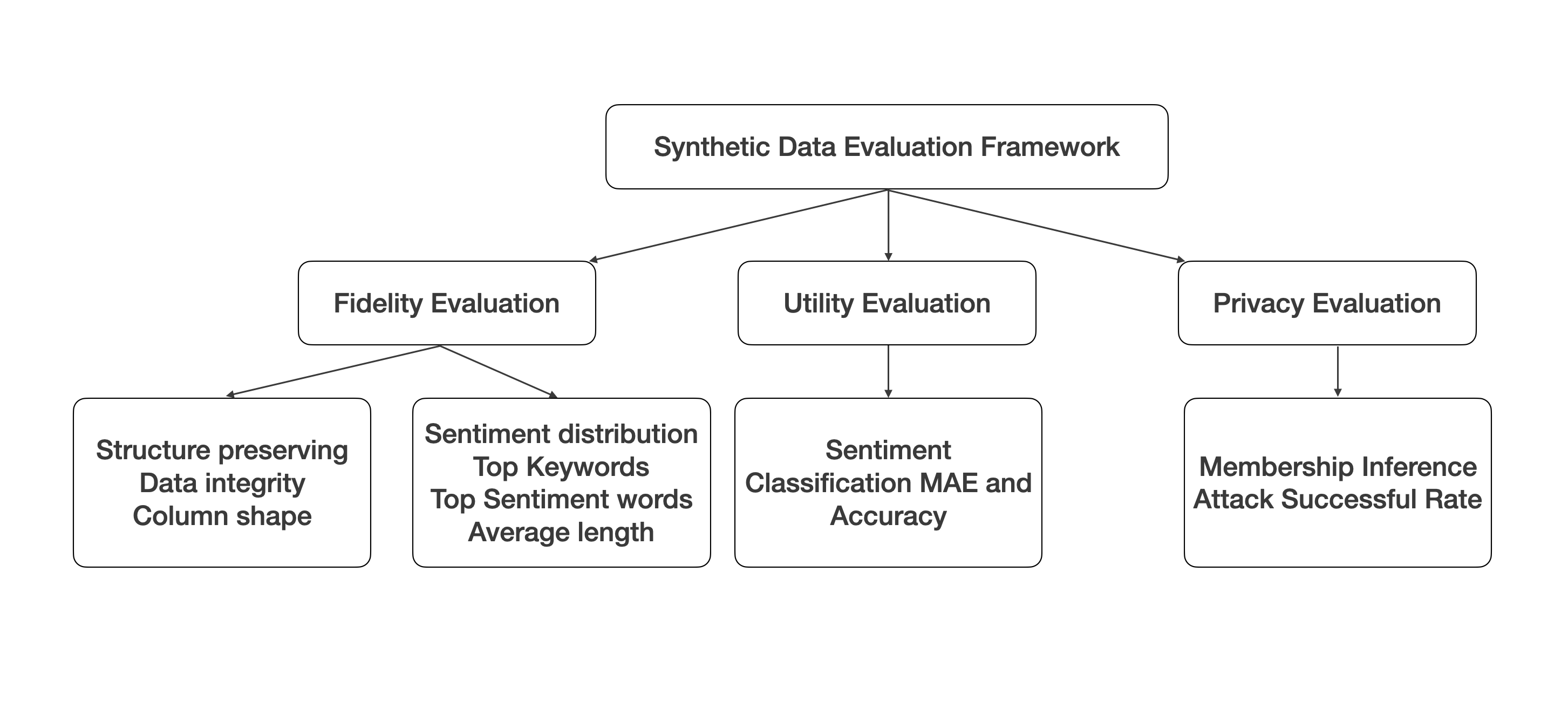
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024
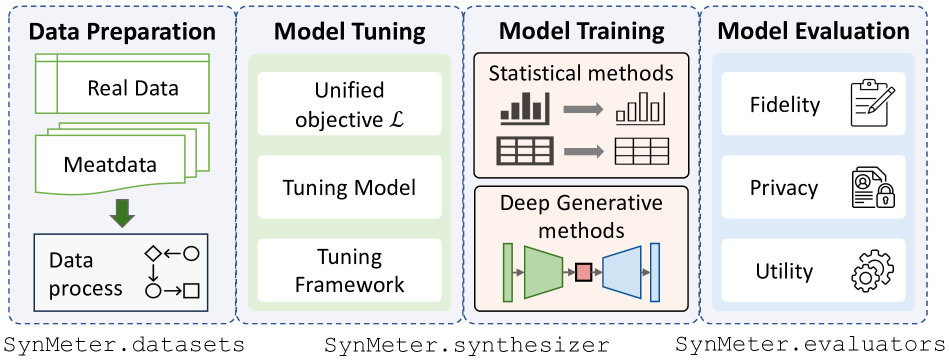
Systematic Assessment of Tabular Data Synthesis Algorithms
Yuntao Du, Ninghui Li
0
0
Data synthesis has been advocated as an important approach for utilizing data while protecting data privacy. A large number of tabular data synthesis algorithms (which we call synthesizers) have been proposed. Some synthesizers satisfy Differential Privacy, while others aim to provide privacy in a heuristic fashion. A comprehensive understanding of the strengths and weaknesses of these synthesizers remains elusive due to drawbacks in evaluation metrics and missing head-to-head comparisons of newly developed synthesizers that take advantage of diffusion models and large language models with state-of-the-art marginal-based synthesizers. In this paper, we present a systematic evaluation framework for assessing tabular data synthesis algorithms. Specifically, we examine and critique existing evaluation metrics, and introduce a set of new metrics in terms of fidelity, privacy, and utility to address their limitations. Based on the proposed metrics, we also devise a unified objective for tuning, which can consistently improve the quality of synthetic data for all methods. We conducted extensive evaluations of 8 different types of synthesizers on 12 real-world datasets and identified some interesting findings, which offer new directions for privacy-preserving data synthesis.
4/16/2024
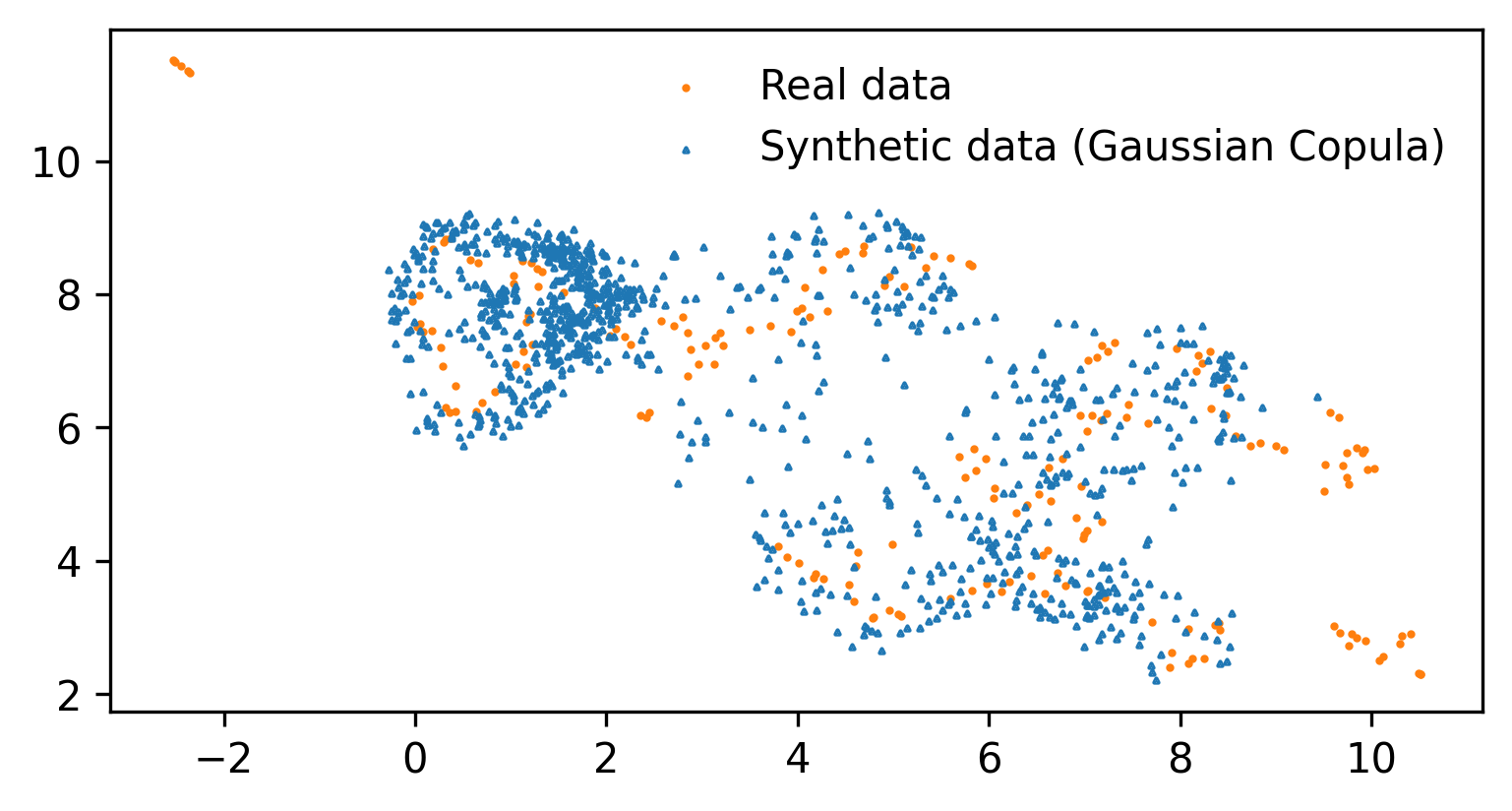
An evaluation framework for synthetic data generation models
Ioannis E. Livieris, Nikos Alimpertis, George Domalis, Dimitris Tsakalidis
0
0
Nowadays, the use of synthetic data has gained popularity as a cost-efficient strategy for enhancing data augmentation for improving machine learning models performance as well as addressing concerns related to sensitive data privacy. Therefore, the necessity of ensuring quality of generated synthetic data, in terms of accurate representation of real data, consists of primary importance. In this work, we present a new framework for evaluating synthetic data generation models' ability for developing high-quality synthetic data. The proposed approach is able to provide strong statistical and theoretical information about the evaluation framework and the compared models' ranking. Two use case scenarios demonstrate the applicability of the proposed framework for evaluating the ability of synthetic data generation models to generated high quality data. The implementation code can be found in https://github.com/novelcore/synthetic_data_evaluation_framework.
4/16/2024
📊
TabSynDex: A Universal Metric for Robust Evaluation of Synthetic Tabular Data
Vikram S Chundawat, Ayush K Tarun, Murari Mandal, Mukund Lahoti, Pratik Narang
0
0
Synthetic tabular data generation becomes crucial when real data is limited, expensive to collect, or simply cannot be used due to privacy concerns. However, producing good quality synthetic data is challenging. Several probabilistic, statistical, generative adversarial networks (GANs), and variational auto-encoder (VAEs) based approaches have been presented for synthetic tabular data generation. Once generated, evaluating the quality of the synthetic data is quite challenging. Some of the traditional metrics have been used in the literature but there is lack of a common, robust, and single metric. This makes it difficult to properly compare the effectiveness of different synthetic tabular data generation methods. In this paper we propose a new universal metric, TabSynDex, for robust evaluation of synthetic data. The proposed metric assesses the similarity of synthetic data with real data through different component scores which evaluate the characteristics that are desirable for ``high quality'' synthetic data. Being a single score metric and having an implicit bound, TabSynDex can also be used to observe and evaluate the training of neural network based approaches. This would help in obtaining insights that was not possible earlier. We present several baseline models for comparative analysis of the proposed evaluation metric with existing generative models. We also give a comparative analysis between TabSynDex and existing synthetic tabular data evaluation metrics. This shows the effectiveness and universality of our metric over the existing metrics. Source Code: url{https://github.com/vikram2000b/tabsyndex}
6/11/2024