Supporting Self-Reflection at Scale with Large Language Models: Insights from Randomized Field Experiments in Classrooms
2406.07571
0
0
💬
Abstract
Self-reflection on learning experiences constitutes a fundamental cognitive process, essential for the consolidation of knowledge and the enhancement of learning efficacy. However, traditional methods to facilitate reflection often face challenges in personalization, immediacy of feedback, engagement, and scalability. Integration of Large Language Models (LLMs) into the reflection process could mitigate these limitations. In this paper, we conducted two randomized field experiments in undergraduate computer science courses to investigate the potential of LLMs to help students engage in post-lesson reflection. In the first experiment (N=145), students completed a take-home assignment with the support of an LLM assistant; half of these students were then provided access to an LLM designed to facilitate self-reflection. The results indicated that the students assigned to LLM-guided reflection reported increased self-confidence and performed better on a subsequent exam two weeks later than their peers in the control condition. In the second experiment (N=112), we evaluated the impact of LLM-guided self-reflection against other scalable reflection methods, such as questionnaire-based activities and review of key lecture slides, after assignment. Our findings suggest that the students in the questionnaire and LLM-based reflection groups performed equally well and better than those who were only exposed to lecture slides, according to their scores on a proctored exam two weeks later on the same subject matter. These results underscore the utility of LLM-guided reflection and questionnaire-based activities in improving learning outcomes. Our work highlights that focusing solely on the accuracy of LLMs can overlook their potential to enhance metacognitive skills through practices such as self-reflection. We discuss the implications of our research for the Edtech community.
Create account to get full access
Overview
- This paper explores the use of Large Language Models (LLMs) to enhance student self-reflection and improve learning outcomes in undergraduate computer science courses.
- The researchers conducted two randomized field experiments to investigate the potential of LLMs to facilitate post-lesson reflection.
- The results suggest that LLM-guided reflection and questionnaire-based activities can improve learning outcomes compared to traditional methods, such as reviewing lecture slides.
Plain English Explanation
Self-reflection is an important process that helps students consolidate their knowledge and become more effective learners. However, traditional methods of facilitating reflection often face challenges in terms of personalization, timely feedback, student engagement, and scalability.
The researchers in this study explored the use of Large Language Models (LLMs) to address these limitations. LLMs are powerful AI models that can understand and generate human-like text. The researchers believed that integrating LLMs into the reflection process could make it more personalized, immediate, engaging, and scalable for students.
In the first experiment, students completed a take-home assignment with the help of an LLM assistant. Half of these students were then provided access to an LLM designed to guide their self-reflection. The results showed that the students who used the LLM-guided reflection reported increased self-confidence and performed better on a subsequent exam compared to their peers in the control group.
In the second experiment, the researchers evaluated the impact of LLM-guided self-reflection against other scalable reflection methods, such as questionnaire-based activities and reviewing key lecture slides. The findings suggested that the students in the questionnaire and LLM-based reflection groups performed equally well and better than those who only reviewed the lecture slides on a proctored exam two weeks later.
These results highlight the potential of LLM-guided reflection and questionnaire-based activities to improve learning outcomes. The researchers note that focusing solely on the accuracy of LLMs can overlook their ability to enhance metacognitive skills, such as self-reflection. This study has important implications for the educational technology (Edtech) community in leveraging the power of LLMs to enhance student learning and reflection.
Technical Explanation
The researchers conducted two randomized field experiments in undergraduate computer science courses to investigate the potential of LLMs to facilitate self-reflection and improve learning outcomes.
In the first experiment (N=145), students completed a take-home assignment with the support of an LLM assistant. Half of these students were then provided access to an LLM designed to guide their self-reflection. The LLM-guided reflection focused on prompting students to assess their understanding, identify areas for improvement, and plan for future learning. The researchers measured student self-confidence and performance on a subsequent exam two weeks later.
The results of the first experiment indicated that the students assigned to the LLM-guided reflection condition reported increased self-confidence and performed better on the exam compared to their peers in the control group.
In the second experiment (N=112), the researchers evaluated the impact of LLM-guided self-reflection against other scalable reflection methods, such as questionnaire-based activities and review of key lecture slides. The students in the questionnaire and LLM-based reflection groups performed equally well and better than those who were only exposed to the lecture slides, as measured by their scores on a proctored exam two weeks later.
These findings suggest that LLM-guided reflection and questionnaire-based activities can be effective in improving learning outcomes, potentially by enhancing students' metacognitive skills and self-regulation. The researchers argue that focusing solely on the accuracy of LLMs can overlook their potential to support cognitive processes like self-reflection.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their study. Firstly, the experiments were conducted in a specific academic context (undergraduate computer science courses), and the generalizability of the findings to other disciplines or educational settings remains to be explored.
Additionally, the study did not delve into the specific mechanisms or cognitive processes underlying the observed improvements in learning outcomes. Further research is needed to understand how LLM-guided reflection and other reflection methods influence students' learning and metacognitive development.
Another potential limitation is the short-term nature of the assessments, as the experiments only measured performance on exams two weeks after the interventions. The long-term impact of these reflection methods on students' learning and academic achievement over a more extended period remains to be investigated.
Moreover, the study did not explore the potential challenges or barriers to the implementation of LLM-guided reflection in real-world educational settings, such as technological limitations, teacher training needs, or student acceptance and engagement.
Overall, the study provides a promising foundation for understanding the role of LLMs in enhancing student self-reflection and learning, but more research is needed to fully explore the implications and potential limitations of this approach.
Conclusion
This study highlights the potential of integrating Large Language Models (LLMs) into the self-reflection process to improve learning outcomes in undergraduate computer science courses. The researchers found that LLM-guided reflection and questionnaire-based activities can lead to increased student self-confidence and better performance on subsequent exams, compared to traditional methods like reviewing lecture slides.
These findings suggest that focusing on the accuracy of LLMs may overlook their ability to enhance metacognitive skills, such as self-reflection. The study has important implications for the educational technology (Edtech) community, underscoring the value of leveraging LLMs to support personalized, timely, and engaging self-reflection practices that can ultimately enhance student learning and academic achievement.
While the study provides a promising starting point, further research is needed to explore the generalizability of these findings, the underlying cognitive mechanisms, and the long-term impacts of LLM-guided reflection. Addressing these areas will help to solidify the role of LLMs in transforming self-reflection and learning experiences for students across various educational contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

When Hindsight is Not 20/20: Testing Limits on Reflective Thinking in Large Language Models
Yanhong Li, Chenghao Yang, Allyson Ettinger
0
0
Recent studies suggest that self-reflective prompting can significantly enhance the reasoning capabilities of Large Language Models (LLMs). However, the use of external feedback as a stop criterion raises doubts about the true extent of LLMs' ability to emulate human-like self-reflection. In this paper, we set out to clarify these capabilities under a more stringent evaluation setting in which we disallow any kind of external feedback. Our findings under this setting show a split: while self-reflection enhances performance in TruthfulQA, it adversely affects results in HotpotQA. We conduct follow-up analyses to clarify the contributing factors in these patterns, and find that the influence of self-reflection is impacted both by reliability of accuracy in models' initial responses, and by overall question difficulty: specifically, self-reflection shows the most benefit when models are less likely to be correct initially, and when overall question difficulty is higher. We also find that self-reflection reduces tendency toward majority voting. Based on our findings, we propose guidelines for decisions on when to implement self-reflection. We release the codebase for reproducing our experiments at https://github.com/yanhong-lbh/LLM-SelfReflection-Eval.
4/16/2024
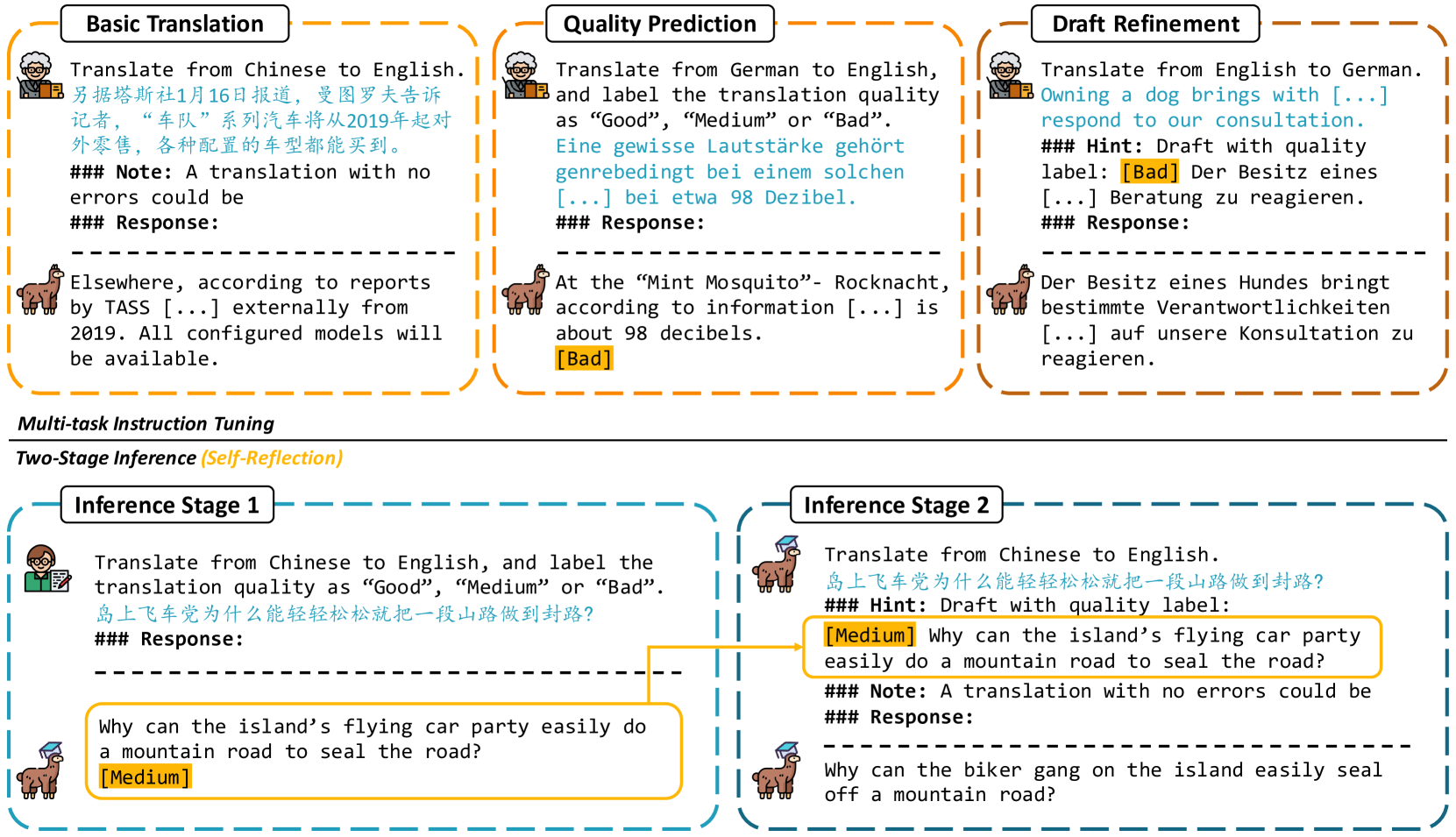
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
0
0
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
6/13/2024
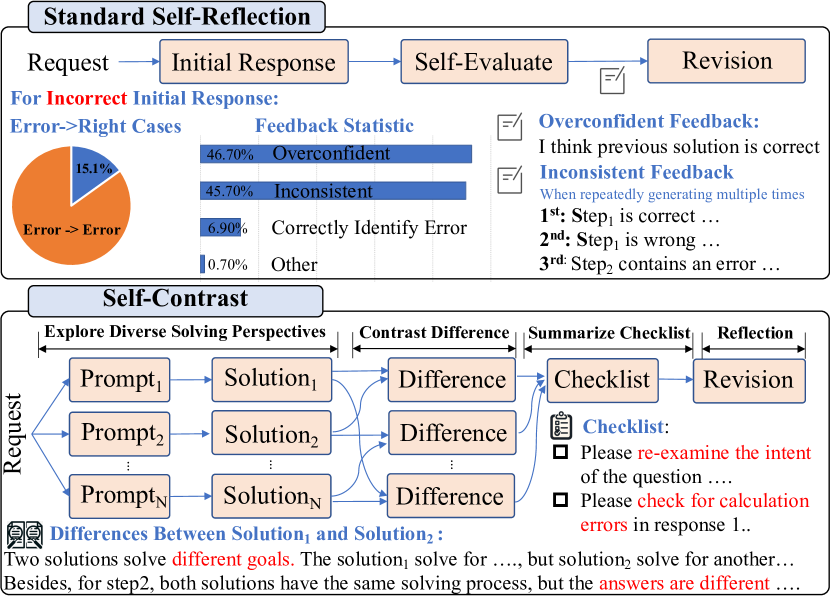
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives
Wenqi Zhang, Yongliang Shen, Linjuan Wu, Qiuying Peng, Jun Wang, Yueting Zhuang, Weiming Lu
0
0
The reflection capacity of Large Language Model (LLM) has garnered extensive attention. A post-hoc prompting strategy, e.g., reflexion and self-refine, refines LLM's response based on self-evaluated or external feedback. However, recent research indicates without external feedback, LLM's intrinsic reflection is unstable. Our investigation unveils that the key bottleneck is the quality of the self-evaluated feedback. We find LLMs often exhibit overconfidence or high randomness when self-evaluate, offering stubborn or inconsistent feedback, which causes poor reflection. To remedy this, we advocate Self-Contrast: It adaptively explores diverse solving perspectives tailored to the request, contrasts the differences, and summarizes these discrepancies into a checklist which could be used to re-examine and eliminate discrepancies. Our method endows LLM with diverse perspectives to alleviate stubborn biases. Moreover, their discrepancies indicate potential errors or inherent uncertainties that LLM often overlooks. Reflecting upon these can catalyze more accurate and stable reflection. Experiments conducted on a series of reasoning and translation tasks with different LLMs serve to underscore the effectiveness and generality of our strategy.
6/10/2024
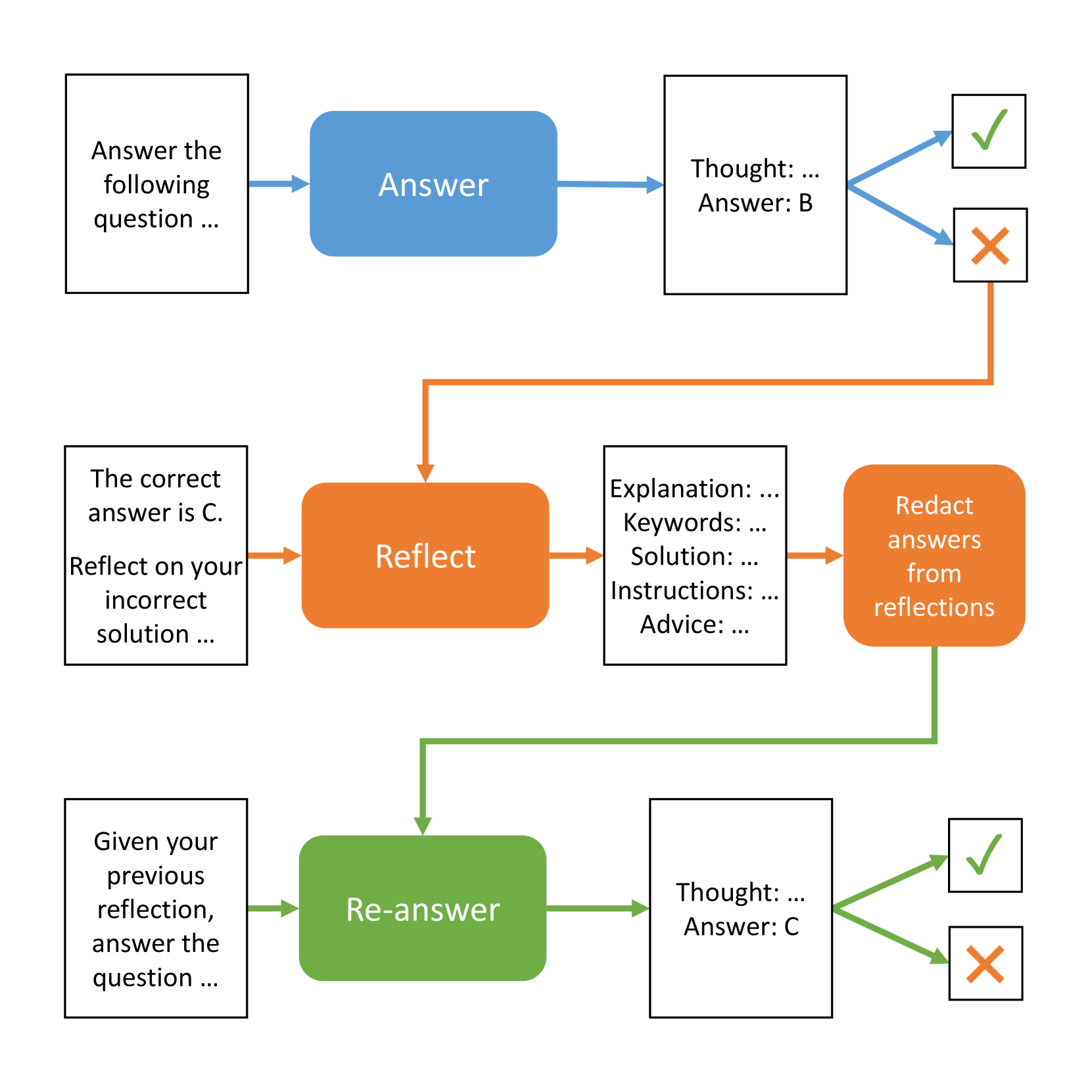
Self-Reflection in LLM Agents: Effects on Problem-Solving Performance
Matthew Renze, Erhan Guven
0
0
In this study, we investigated the effects of self-reflection in large language models (LLMs) on problem-solving performance. We instructed nine popular LLMs to answer a series of multiple-choice questions to provide a performance baseline. For each incorrectly answered question, we instructed eight types of self-reflecting LLM agents to reflect on their mistakes and provide themselves with guidance to improve problem-solving. Then, using this guidance, each self-reflecting agent attempted to re-answer the same questions. Our results indicate that LLM agents are able to significantly improve their problem-solving performance through self-reflection ($p < 0.001$). In addition, we compared the various types of self-reflection to determine their individual contribution to performance. All code and data are available on GitHub at https://github.com/matthewrenze/self-reflection
5/14/2024