SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs

0
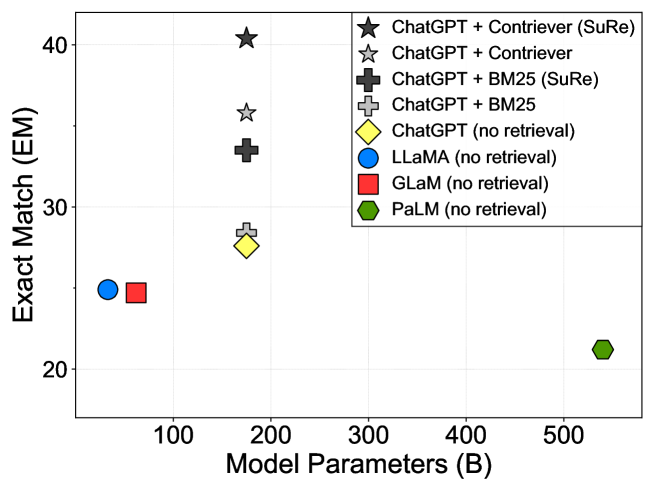
Sign in to get full access
Overview
- Introduces a novel approach called "Summarized Retrieval" (SuRe) to improve open-domain question answering (QA) for large language models (LLMs)
- Aims to address issues with existing retrieval-based QA systems, such as long and irrelevant retrieved passages
- Proposes using answer candidates to summarize the retrieved information, providing more concise and relevant information to the QA model
Plain English Explanation
The paper presents a new technique called "Summarized Retrieval" (SuRe) to enhance open-domain question answering with large language models. Open-domain QA is the task of answering questions using information from a broad range of sources, rather than a specific domain.
One challenge with current retrieval-based QA systems is that they often return long and irrelevant passages, which can overwhelm the QA model and make it harder to find the correct answer. The SuRe approach tries to address this by using the answer candidates generated by the QA model to summarize the retrieved information.
The key idea is to leverage the QA model's understanding of the question and the relevant information needed to answer it. By using the answer candidates as a guide, SuRe can extract the most important and relevant parts of the retrieved passages and present them to the QA model in a more concise and focused way. This can help the model better understand the context and find the correct answer more effectively.
The paper describes the technical details of how SuRe works and presents experiments showing that it can improve the performance of open-domain QA systems compared to traditional retrieval-based approaches. By providing more relevant and summarized information to the QA model, SuRe aims to make open-domain question answering more accurate and efficient.
Technical Explanation
The paper introduces a novel approach called "Summarized Retrieval" (SuRe) to improve open-domain question answering (QA) for large language models (LLMs). The key idea is to use the answer candidates generated by the QA model to summarize the retrieved information, providing more concise and relevant context to the model.
Traditionally, retrieval-based QA systems retrieve relevant passages from a large corpus and pass them to the QA model to generate an answer. However, these retrieved passages can be long and contain irrelevant information, which can overwhelm the QA model and make it harder to find the correct answer.
To address this issue, the SuRe approach works as follows:
- Retrieval: The system first retrieves relevant passages from a large corpus using a standard retrieval model, such as BM25.
- Answer Candidate Generation: The retrieved passages are then passed to the QA model, which generates a set of answer candidates.
- Summarization: The system uses the answer candidates to identify the most relevant parts of the retrieved passages and generate a summary of the information needed to answer the question.
- Final Answer Prediction: The summarized information is then passed back to the QA model to predict the final answer.
The key innovation in SuRe is the use of answer candidates to guide the summarization process. By focusing on the parts of the retrieved passages that are most relevant to the question, as indicated by the answer candidates, SuRe can provide the QA model with a more concise and targeted context, which can lead to improved performance.
The paper presents experiments on open-domain QA benchmarks, showing that SuRe can outperform traditional retrieval-based QA approaches. The results suggest that the summarization step can help the QA model better understand the retrieved information and find the correct answer more effectively.
Critical Analysis
The paper presents a promising approach to improving open-domain question answering with large language models. The key idea of using answer candidates to guide the summarization of retrieved information is a clever and intuitive way to address the limitations of traditional retrieval-based QA systems.
One potential limitation of the SuRe approach is that it relies on the QA model's ability to generate accurate answer candidates, which may not always be the case, especially for more challenging questions. If the answer candidates are not of high quality, the summarization step may not be as effective, and the final QA performance may suffer.
Additionally, the paper does not provide a detailed analysis of the tradeoffs between the length of the summarized information and the QA performance. It would be interesting to see how the system's performance changes as the summarization becomes more or less concise, and whether there is an optimal balance to be struck.
Another area for further research could be exploring ways to incorporate additional sources of information, such as knowledge bases or external text corpora, into the summarization process. This could potentially help the system identify and highlight the most relevant facts and context, further improving the QA performance.
Overall, the SuRe approach is a promising step forward in the field of open-domain question answering, and the paper provides a solid foundation for future research and development in this area.
Conclusion
The paper introduces a novel technique called "Summarized Retrieval" (SuRe) to enhance open-domain question answering with large language models. By using the answer candidates generated by the QA model to guide the summarization of retrieved information, SuRe aims to provide more concise and relevant context to the model, leading to improved QA performance.
The key innovation in SuRe is the way it leverages the QA model's understanding of the question and the relevant information needed to answer it. This allows the system to focus on the most important parts of the retrieved passages, rather than presenting the model with long and irrelevant information.
The paper's experimental results suggest that SuRe can outperform traditional retrieval-based QA approaches, demonstrating the potential of this technique to advance the state of the art in open-domain question answering. As the field of large language models continues to evolve, approaches like SuRe may play an important role in making these models more effective and efficient at answering a wide range of questions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Jaehyung Kim, Jaehyun Nam, Sangwoo Mo, Jongjin Park, Sang-Woo Lee, Minjoon Seo, Jung-Woo Ha, Jinwoo Shin
Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
Read more4/23/2024
🛸
0
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
Read more5/30/2024

0
Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering
Minsang Kim, Cheoneum Park, Seungjun Baek
Retrieval-augmented generation (RAG) has received much attention for Open-domain question-answering (ODQA) tasks as a means to compensate for the parametric knowledge of large language models (LLMs). While previous approaches focused on processing retrieved passages to remove irrelevant context, they still rely heavily on the quality of retrieved passages which can degrade if the question is ambiguous or complex. In this paper, we propose a simple yet efficient method called question and passage augmentation (QPaug) via LLMs for open-domain QA. QPaug first decomposes the original questions into multiple-step sub-questions. By augmenting the original question with detailed sub-questions and planning, we are able to make the query more specific on what needs to be retrieved, improving the retrieval performance. In addition, to compensate for the case where the retrieved passages contain distracting information or divided opinions, we augment the retrieved passages with self-generated passages by LLMs to guide the answer extraction. Experimental results show that QPaug outperforms the previous state-of-the-art and achieves significant performance gain over existing RAG methods. The source code is available at url{https://github.com/kmswin1/QPaug}.
Read more9/30/2024
🛸
0
Modeling Uncertainty and Using Post-fusion as Fallback Improves Retrieval Augmented Generation with LLMs
Ye Liu, Semih Yavuz, Rui Meng, Meghana Moorthy, Shafiq Joty, Caiming Xiong, Yingbo Zhou
The integration of retrieved passages and large language models (LLMs), such as ChatGPTs, has significantly contributed to improving open-domain question answering. However, there is still a lack of exploration regarding the optimal approach for incorporating retrieved passages into the answer generation process. This paper aims to fill this gap by investigating different methods of combining retrieved passages with LLMs to enhance answer generation. We begin by examining the limitations of a commonly-used concatenation approach. Surprisingly, this approach often results in generating unknown outputs, even when the correct document is among the top-k retrieved passages. To address this issue, we explore four alternative strategies for integrating the retrieved passages with the LLMs. These strategies include two single-round methods that utilize chain-of-thought reasoning and two multi-round strategies that incorporate feedback loops. Through comprehensive analyses and experiments, we provide insightful observations on how to effectively leverage retrieved passages to enhance the answer generation capability of LLMs.
Read more4/9/2024