Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering

0

Sign in to get full access
Overview
• This paper explores the use of retrieval-augmented generation, a technique that combines large language models (LLMs) with information retrieval, to improve open-domain question answering.
• The researchers propose two key innovations: augmenting the query to better match relevant passages, and jointly optimizing the retrieval and generation components.
• The goal is to leverage the strengths of both retrieval and generation to provide more accurate and informative answers to open-ended questions.
Plain English Explanation
The paper is about a new approach to open-domain question answering, which is the task of answering questions on a wide range of topics using information from the internet or other large data sources. The researchers combine two powerful AI techniques - information retrieval and large language models - to try to improve the quality and usefulness of the answers.
The key ideas are:
-
Enhancing the query: They find ways to modify the original question asked by the user to better match the relevant information in their database. This helps the system understand the question more accurately.
-
Joint optimization: They train the retrieval and generation components of the system together, so they can work in harmony to produce better answers. The retrieval part finds the most relevant information, and the generation part synthesizes that into a coherent response.
By using these techniques, the researchers aim to create an AI system that can answer open-ended questions more reliably and provide users with more complete and informative responses. This could be helpful in many real-world applications, such as search engines, virtual assistants, and educational tools.
Technical Explanation
The paper proposes two key innovations to improve retrieval-augmented generation (RAG) for open-domain question answering:
-
Query Augmentation: The researchers develop a method to dynamically expand the user's original query by identifying the most relevant passages from a large corpus. This helps the system better understand the context and intent behind the question, allowing it to retrieve more pertinent information.
-
Joint Optimization: Instead of training the retrieval and generation components separately, the paper introduces a "DuetRAG" architecture that jointly optimizes the two modules. This enables the system to learn how to best combine retrieval and generation for improved performance on the overall task.
The proposed methods are evaluated on several open-domain QA benchmarks, where they demonstrate improved results compared to previous RAG approaches as well as other state-of-the-art models. The authors also conduct detailed analyses to understand the strengths and limitations of their approach.
Critical Analysis
The paper makes valuable contributions to the field of retrieval-augmented generation for open-domain QA. The proposed query augmentation and joint optimization techniques are well-motivated and show promising empirical results. However, the authors acknowledge several limitations and areas for future work:
- The performance gains, while significant, may still fall short of human-level question answering abilities. Further improvements to the underlying retrieval and generation components are needed.
- The approach relies on a large corpus of text data, which may not be available or practical in all real-world settings. Exploring ways to adapt the system to smaller or more specialized knowledge bases is an important direction.
- The paper does not deeply examine the safety and reliability concerns that can arise when using large language models for open-ended tasks. Addressing these issues will be crucial for deploying such systems in high-stakes applications.
Overall, the research represents a valuable step forward in the quest to build more capable and trustworthy question answering systems. Continued advancements in this area could lead to significant benefits for a wide range of users and applications.
Conclusion
This paper proposes innovative techniques to enhance retrieval-augmented generation for open-domain question answering. By improving the way queries are matched to relevant passages and jointly optimizing the retrieval and generation components, the researchers demonstrate tangible improvements in QA performance.
While the work has limitations and further research is needed, it represents an important contribution to the field of AI-powered question answering. If these methods can be further refined and scaled, they could lead to more reliable and informative virtual assistants, search engines, and educational tools that can better support human users in finding answers to their questions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering
Minsang Kim, Cheoneum Park, Seungjun Baek
Retrieval-augmented generation (RAG) has received much attention for Open-domain question-answering (ODQA) tasks as a means to compensate for the parametric knowledge of large language models (LLMs). While previous approaches focused on processing retrieved passages to remove irrelevant context, they still rely heavily on the quality of retrieved passages which can degrade if the question is ambiguous or complex. In this paper, we propose a simple yet efficient method called question and passage augmentation (QPaug) via LLMs for open-domain QA. QPaug first decomposes the original questions into multiple-step sub-questions. By augmenting the original question with detailed sub-questions and planning, we are able to make the query more specific on what needs to be retrieved, improving the retrieval performance. In addition, to compensate for the case where the retrieved passages contain distracting information or divided opinions, we augment the retrieved passages with self-generated passages by LLMs to guide the answer extraction. Experimental results show that QPaug outperforms the previous state-of-the-art and achieves significant performance gain over existing RAG methods. The source code is available at url{https://github.com/kmswin1/QPaug}.
Read more9/30/2024
0
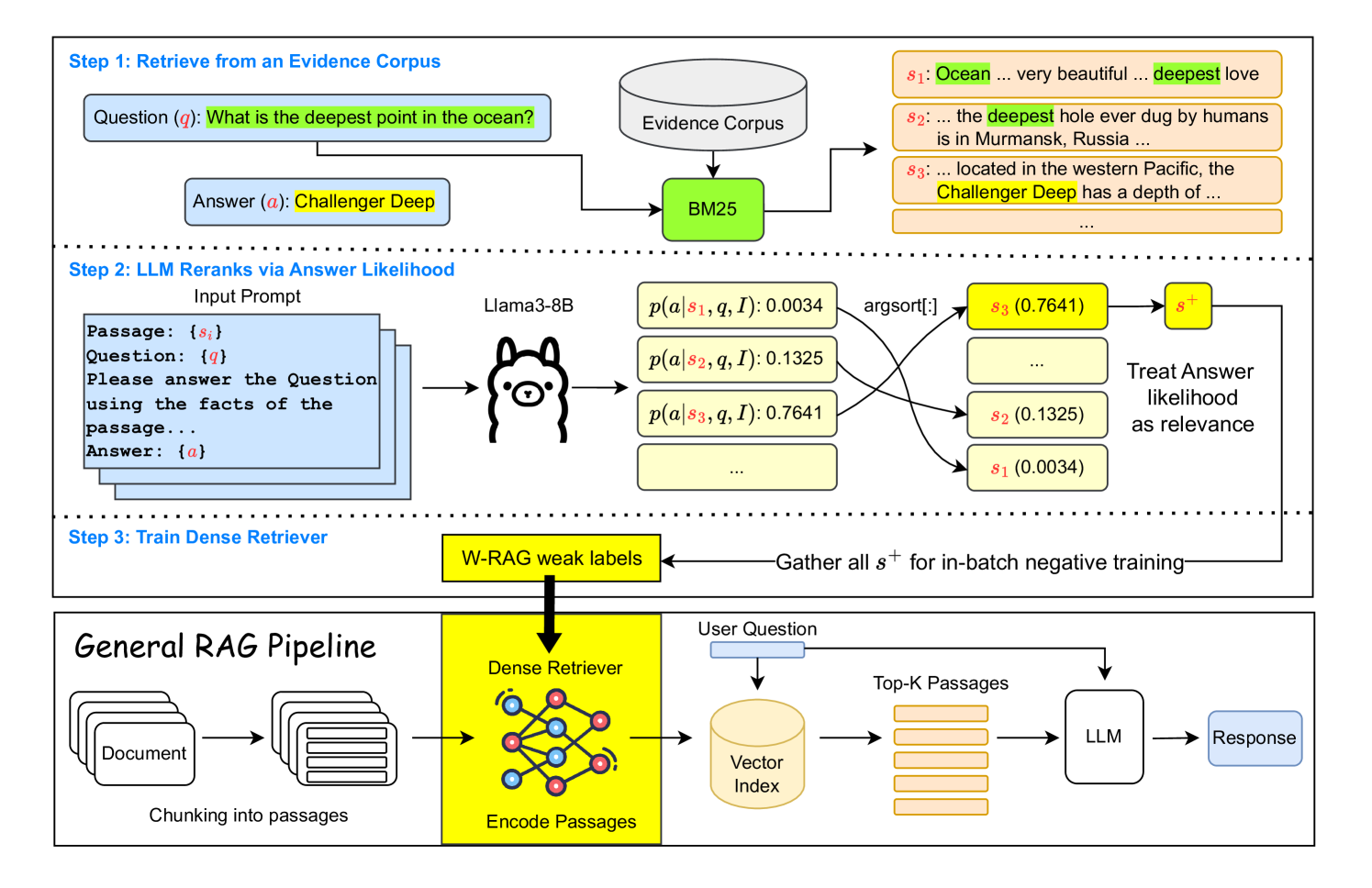
W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering
Jinming Nian, Zhiyuan Peng, Qifan Wang, Yi Fang
In knowledge-intensive tasks such as open-domain question answering (OpenQA), Large Language Models (LLMs) often struggle to generate factual answers relying solely on their internal (parametric) knowledge. To address this limitation, Retrieval-Augmented Generation (RAG) systems enhance LLMs by retrieving relevant information from external sources, thereby positioning the retriever as a pivotal component. Although dense retrieval demonstrates state-of-the-art performance, its training poses challenges due to the scarcity of ground-truth evidence, largely attributed to the high costs of human annotation. In this paper, we propose W-RAG by utilizing the ranking capabilities of LLMs to create weakly labeled data for training dense retrievers. Specifically, we rerank the top-$K$ passages retrieved via BM25 by assessing the probability that LLMs will generate the correct answer based on the question and each passage. The highest-ranking passages are then used as positive training examples for dense retrieval. Our comprehensive experiments across four publicly available OpenQA datasets demonstrate that our approach enhances both retrieval and OpenQA performance compared to baseline models.
Read more8/19/2024

0
Learning When to Retrieve, What to Rewrite, and How to Respond in Conversational QA
Nirmal Roy, Leonardo F. R. Ribeiro, Rexhina Blloshmi, Kevin Small
Augmenting Large Language Models (LLMs) with information retrieval capabilities (i.e., Retrieval-Augmented Generation (RAG)) has proven beneficial for knowledge-intensive tasks. However, understanding users' contextual search intent when generating responses is an understudied topic for conversational question answering (QA). This conversational extension leads to additional concerns when compared to single-turn QA as it is more challenging for systems to comprehend conversational context and manage retrieved passages over multiple turns. In this work, we propose a method for enabling LLMs to decide when to retrieve in RAG settings given a conversational context. When retrieval is deemed necessary, the LLM then rewrites the conversation for passage retrieval and judges the relevance of returned passages before response generation. Operationally, we build on the single-turn SELF-RAG framework (Asai et al., 2023) and propose SELF-multi-RAG for conversational settings. SELF-multi-RAG demonstrates improved capabilities over single-turn variants with respect to retrieving relevant passages (by using summarized conversational context) and assessing the quality of generated responses. Experiments on three conversational QA datasets validate the enhanced response generation capabilities of SELF-multi-RAG, with improvements of ~13% measured by human annotation.
Read more9/25/2024
🛸
0
MKRAG: Medical Knowledge Retrieval Augmented Generation for Medical Question Answering
Yucheng Shi, Shaochen Xu, Tianze Yang, Zhengliang Liu, Tianming Liu, Quanzheng Li, Xiang Li, Ninghao Liu
Large Language Models (LLMs), although powerful in general domains, often perform poorly on domain-specific tasks such as medical question answering (QA). In addition, LLMs tend to function as black-boxes, making it challenging to modify their behavior. To address the problem, our work employs a transparent process of retrieval augmented generation (RAG), aiming to improve LLM responses without the need for fine-tuning or retraining. Specifically, we propose a comprehensive retrieval strategy to extract medical facts from an external knowledge base, and then inject them into the LLM's query prompt. Focusing on medical QA, we evaluate the impact of different retrieval models and the number of facts on LLM performance using the MedQA-SMILE dataset. Notably, our retrieval-augmented Vicuna-7B model exhibited an accuracy improvement from 44.46% to 48.54%. This work underscores the potential of RAG to enhance LLM performance, offering a practical approach to mitigate the challenges posed by black-box LLMs.
Read more8/19/2024