A Survey on 3D Human Avatar Modeling -- From Reconstruction to Generation
2406.04253
0
0
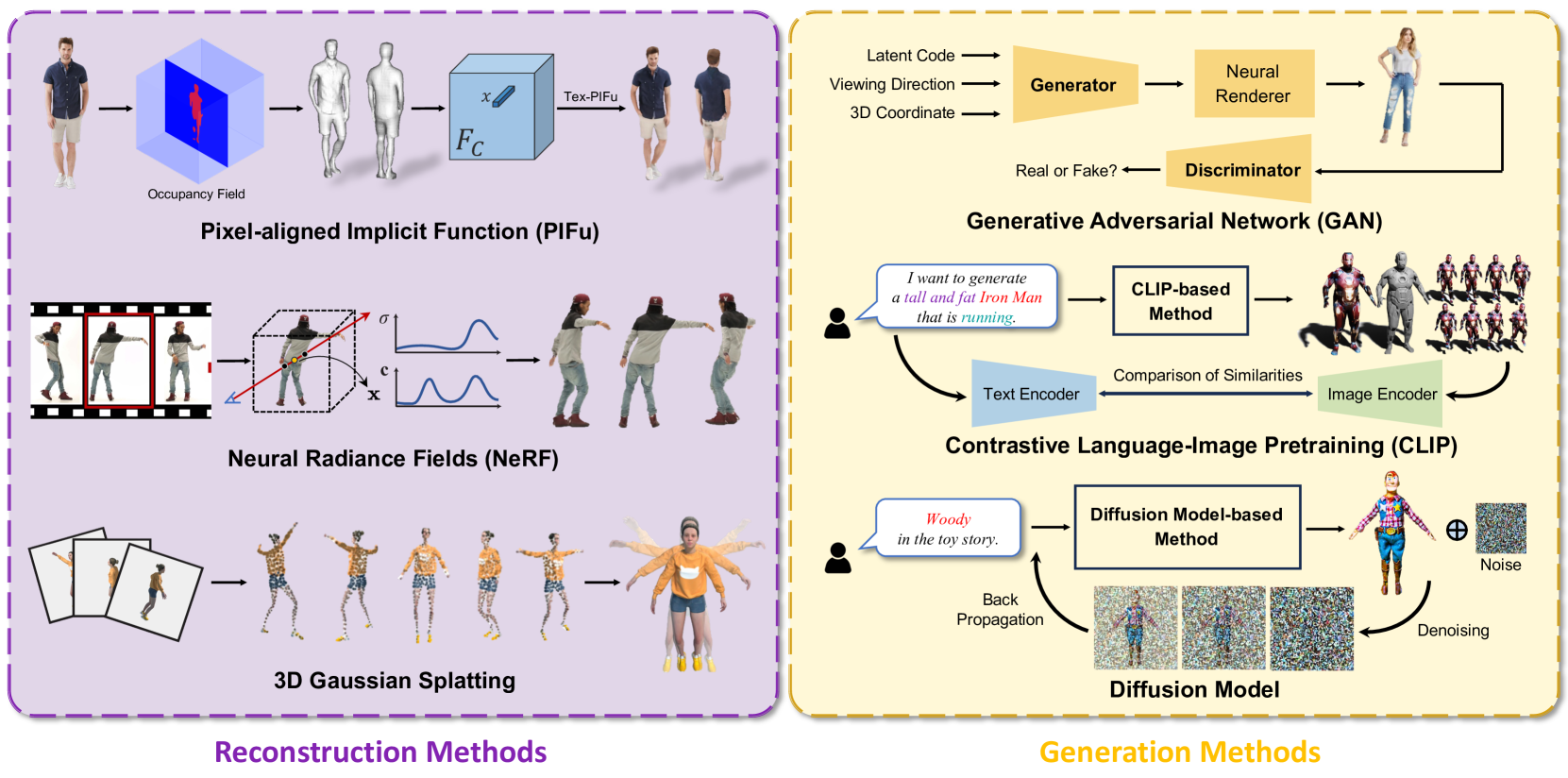
Abstract
3D modeling has long been an important area in computer vision and computer graphics. Recently, thanks to the breakthroughs in neural representations and generative models, we witnessed a rapid development of 3D modeling. 3D human modeling, lying at the core of many real-world applications, such as gaming and animation, has attracted significant attention. Over the past few years, a large body of work on creating 3D human avatars has been introduced, forming a new and abundant knowledge base for 3D human modeling. The scale of the literature makes it difficult for individuals to keep track of all the works. This survey aims to provide a comprehensive overview of these emerging techniques for 3D human avatar modeling, from both reconstruction and generation perspectives. Firstly, we review representative methods for 3D human reconstruction, including methods based on pixel-aligned implicit function, neural radiance field, and 3D Gaussian Splatting, etc. We then summarize representative methods for 3D human generation, especially those using large language models like CLIP, diffusion models, and various 3D representations, which demonstrate state-of-the-art performance. Finally, we discuss our reflection on existing methods and open challenges for 3D human avatar modeling, shedding light on future research.
Create account to get full access
Overview
- This paper provides a comprehensive survey of 3D human avatar modeling, covering techniques for both reconstruction from real-world data and generation from scratch.
- It explores the latest advancements in areas like human image generation, high-resolution human modeling, 3D human reconstruction from wild and synthetic data, and efficient 3D head reconstruction.
- The survey also covers approaches for generating 3D content from text, a emerging field with many potential applications.
Plain English Explanation
This paper looks at the latest techniques for creating 3D digital models of humans, also known as "avatars." Avatars are important for a variety of applications, like video games, virtual reality, and online communication.
The paper explores two main approaches for creating these 3D human avatars:
-
Reconstruction: Taking real-world data, like photos or videos of a person, and using algorithms to reconstruct a 3D model of them. This allows creating avatars that closely match the appearance of a real person.
-
Generation: Creating 3D human models from scratch, without needing to start with real-world data. This gives more flexibility to design unique avatar appearances, but can be more challenging to make them look realistic.
The paper covers the latest advancements in both reconstruction and generation techniques. For example, it discusses how researchers are using machine learning to create high-quality, detailed 3D human models from just a few photographs. It also explores ways to reconstruct 3D humans from "in the wild" data, like images found online, as well as more efficient methods for 3D head reconstruction.
Additionally, the paper looks at emerging techniques for generating 3D human content directly from text descriptions, which could make it easier to create customized 3D avatars and scenes.
Technical Explanation
The paper begins by providing an overview of the field of 3D human avatar modeling, including the key challenges and important applications. It then divides the topic into two main areas: reconstruction from real-world data, and generation from scratch.
For reconstruction, the survey covers techniques that use photographs, videos, or other "in the wild" data to build 3D models of human subjects. This includes approaches that leverage machine learning to create high-resolution, detailed 3D human avatars from limited input data. The paper also examines efficient 3D head reconstruction methods, which are important for applications like virtual communication.
For generation, the survey looks at techniques that can create fully synthetic 3D human models without requiring real-world data as input. This includes exploring recent advancements in text-to-3D content generation, where machine learning models are trained to generate 3D human avatars and scenes based on textual descriptions.
Throughout the technical discussion, the paper highlights key insights, experimental results, and architectural innovations from the latest research in this rapidly evolving field.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the state-of-the-art in 3D human avatar modeling. The authors do a commendable job of covering a broad range of techniques, from reconstruction to generation, and highlighting the latest advancements in each area.
One potential limitation of the survey is that it may not delve deeply into the specific challenges and trade-offs of each approach. For example, while the paper discusses the benefits of text-to-3D generation, it does not explore in detail the difficulties in achieving photorealistic results or maintaining semantic consistency with the input text.
Additionally, the paper could have further explored the ethical considerations around 3D human avatar modeling, such as the potential for misuse in the creation of synthetic media or the implications for user privacy and consent. As this technology continues to advance, it will be important for the research community to grapple with these types of societal impacts.
Overall, this survey serves as a valuable resource for researchers and practitioners working in the field of 3D human avatar modeling. By synthesizing the latest developments and highlighting key trends, it provides a solid foundation for understanding the current state of the art and identifying promising avenues for future exploration.
Conclusion
This comprehensive survey paper examines the current state of 3D human avatar modeling, covering both reconstruction from real-world data and generation from scratch. The authors explore the latest advancements in areas like high-resolution human modeling, efficient 3D head reconstruction, and text-to-3D content generation, highlighting the key insights and innovations from the latest research.
While the paper provides a thorough overview of the technical aspects, it could have delved deeper into the critical challenges and ethical considerations surrounding this rapidly evolving field. Nevertheless, this survey serves as a valuable resource for researchers and practitioners working to push the boundaries of 3D human avatar modeling and its diverse applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Human Image Generation: A Comprehensive Survey
Zhen Jia, Zhang Zhang, Liang Wang, Tieniu Tan
0
0
Image and video synthesis has become a blooming topic in computer vision and machine learning communities along with the developments of deep generative models, due to its great academic and application value. Many researchers have been devoted to synthesizing high-fidelity human images as one of the most commonly seen object categories in daily lives, where a large number of studies are performed based on various models, task settings and applications. Thus, it is necessary to give a comprehensive overview on these variant methods on human image generation. In this paper, we divide human image generation techniques into three paradigms, i.e., data-driven methods, knowledge-guided methods and hybrid methods. For each paradigm, the most representative models and the corresponding variants are presented, where the advantages and characteristics of different methods are summarized in terms of model architectures. Besides, the main public human image datasets and evaluation metrics in the literature are summarized. Furthermore, due to the wide application potentials, the typical downstream usages of synthesized human images are covered. Finally, the challenges and potential opportunities of human image generation are discussed to shed light on future research.
5/27/2024
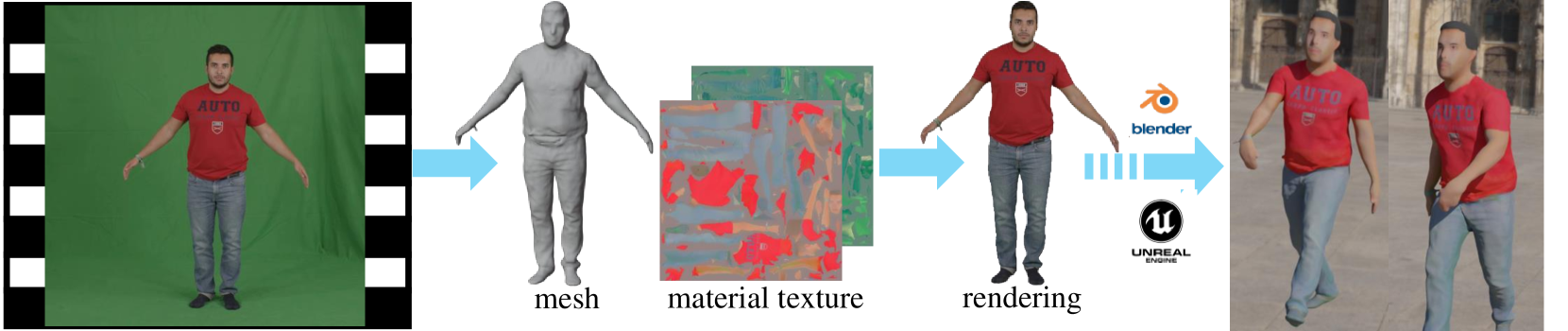
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
0
0
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
5/21/2024
3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
Yongtao Ge, Wenjia Wang, Yongfan Chen, Hao Chen, Chunhua Shen
0
0
In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
4/12/2024

Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Yuxuan Xue, Xianghui Xie, Riccardo Marin, Gerard Pons-Moll
0
0
Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
6/13/2024