Learn from Failure: Fine-Tuning LLMs with Trial-and-Error Data for Intuitionistic Propositional Logic Proving
2404.07382
0
0

Abstract
Recent advances in Automated Theorem Proving have shown the effectiveness of leveraging a (large) language model that generates tactics (i.e. proof steps) to search through proof states. The current model, while trained solely on successful proof paths, faces a discrepancy at the inference stage, as it must sample and try various tactics at each proof state until finding success, unlike its training which does not incorporate learning from failed attempts. Intuitively, a tactic that leads to a failed search path would indicate that similar tactics should receive less attention during the following trials. In this paper, we demonstrate the benefit of training models that additionally learn from failed search paths. Facing the lack of such trial-and-error data in existing open-source theorem-proving datasets, we curate a dataset on intuitionistic propositional logic theorems and formalize it in Lean, such that we can reliably check the correctness of proofs. We compare our model trained on relatively short trial-and-error information (TrialMaster) with models trained only on the correct paths and discover that the former solves more unseen theorems with lower trial searches.
Create account to get full access
Overview
• This research paper explores a new approach to fine-tuning large language models (LLMs) for the task of proving intuitionistic propositional logic (IPL) theorems.
• The authors propose a novel dataset called PropL that includes both successful and unsuccessful proof attempts, allowing the LLMs to learn from their mistakes.
• The paper investigates whether LLMs can effectively learn from this trial-and-error data and improve their IPL theorem-proving capabilities through fine-tuning.
Plain English Explanation
The researchers wanted to create a way for large language models (LLMs) to get better at proving logical theorems, specifically in the area of intuitionistic propositional logic (IPL). IPL is a type of logical reasoning that is slightly different from the more common classical logic.
To do this, the researchers built a new dataset called PropL that included both successful and unsuccessful attempts at proving IPL theorems. The idea was that by exposing the LLMs to examples of both good and bad proof attempts, the models could learn from their mistakes and improve their theorem-proving abilities.
The researchers then fine-tuned the LLMs using this dataset, which means they trained the models further on the PropL data after the models had already been trained on a large amount of general text. The goal was to see if the LLMs could effectively learn from this trial-and-error data and become better at proving IPL theorems.
Technical Explanation
The authors first introduce a new dataset called PropL that contains both successful and unsuccessful proof attempts for intuitionistic propositional logic (IPL) theorems. This dataset is designed to allow large language models (LLMs) to learn from their mistakes during the fine-tuning process.
The researchers then fine-tune several state-of-the-art LLMs, including GPT-3 and T5, on the PropL dataset. They evaluate the fine-tuned models' performance on a held-out test set of IPL theorems and compare the results to models trained on only successful proofs or randomly sampled data.
The paper's key findings are that LLMs can indeed learn from their mistakes when fine-tuned on the trial-and-error data in the PropL dataset. The models trained on both successful and unsuccessful proofs outperform those trained only on successful proofs or random data, demonstrating the value of learning from failure.
The authors also provide an analysis of the types of errors the LLMs make and how the fine-tuning process helps them overcome these issues, leading to more robust and effective IPL theorem-proving capabilities.
Critical Analysis
The researchers have made a compelling case for the benefits of fine-tuning LLMs on datasets that include both successful and unsuccessful examples, using the domain of IPL theorem proving as a case study. The PropL dataset they created seems to be a valuable resource for this line of research.
One potential limitation of the study is the relatively small size of the PropL dataset, which may limit the ability of the LLMs to fully learn from their mistakes. Expanding the dataset with more examples, especially of unsuccessful proof attempts, could potentially lead to even greater improvements in the models' capabilities.
Additionally, the paper does not explore the generalization of the fine-tuning approach to other logical reasoning domains beyond IPL. It would be interesting to see if the benefits of learning from failure extend to other types of logical reasoning tasks or even to more general reasoning and problem-solving abilities in LLMs.
Overall, this research represents an important step forward in understanding how LLMs can learn from their mistakes and use that knowledge to become more effective and robust reasoners. The findings could have significant implications for the development of LLMs for natural language understanding and reasoning tasks.
Conclusion
This paper introduces a novel approach to fine-tuning large language models (LLMs) for the task of proving intuitionistic propositional logic (IPL) theorems. By creating a dataset called PropL that includes both successful and unsuccessful proof attempts, the researchers have demonstrated that LLMs can effectively learn from their mistakes and improve their IPL theorem-proving capabilities.
The findings from this research suggest that incorporating trial-and-error data into the fine-tuning process can be a valuable technique for enhancing the reasoning abilities of LLMs, not just in the domain of IPL but potentially in other areas of logical reasoning and problem-solving as well. This could have significant implications for the development of more capable and robust LLM-based systems that can learn from their failures and continually improve their performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning From Failure: Integrating Negative Examples when Fine-tuning Large Language Models as Agents
Renxi Wang, Haonan Li, Xudong Han, Yixuan Zhang, Timothy Baldwin
0
0
Large language models (LLMs) have achieved success in acting as agents, which interact with environments through tools such as search engines. However, LLMs are optimized for language generation instead of tool use during training or alignment, limiting their effectiveness as agents. To resolve this problem, previous work has first collected interaction trajectories between LLMs and environments, using only trajectories that successfully finished the task to fine-tune smaller models, making fine-tuning data scarce and acquiring it both difficult and costly. Discarding failed trajectories also leads to significant wastage of data and resources and limits the possible optimization paths during fine-tuning. In this paper, we argue that unsuccessful trajectories offer valuable insights, and LLMs can learn from these trajectories through appropriate quality control and fine-tuning strategies. By simply adding a prefix or suffix that tells the model whether to generate a successful trajectory during training, we improve model performance by a large margin on mathematical reasoning, multi-hop question answering, and strategic question answering tasks. We further analyze the inference results and find that our method provides a better trade-off between valuable information and errors in unsuccessful trajectories. To our knowledge, we are the first to demonstrate the value of negative trajectories and their application in agent-tunning scenarios. Our findings offer guidance for developing better agent-tuning methods and low-resource data usage techniques.
4/17/2024
📊
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, Xiaodan Liang
0
0
Proof assistants like Lean have revolutionized mathematical proof verification, ensuring high accuracy and reliability. Although large language models (LLMs) show promise in mathematical reasoning, their advancement in formal theorem proving is hindered by a lack of training data. To address this issue, we introduce an approach to generate extensive Lean 4 proof data derived from high-school and undergraduate-level mathematical competition problems. This approach involves translating natural language problems into formal statements, filtering out low-quality statements, and generating proofs to create synthetic data. After fine-tuning the DeepSeekMath 7B model on this synthetic dataset, which comprises 8 million formal statements with proofs, our model achieved whole-proof generation accuracies of 46.3% with 64 samples and 52% cumulatively on the Lean 4 miniF2F test, surpassing the baseline GPT-4 at 23.0% with 64 samples and a tree search reinforcement learning method at 41.0%. Additionally, our model successfully proved 5 out of 148 problems in the Lean 4 Formalized International Mathematical Olympiad (FIMO) benchmark, while GPT-4 failed to prove any. These results demonstrate the potential of leveraging large-scale synthetic data to enhance theorem-proving capabilities in LLMs. Both the synthetic dataset and the model will be made available to facilitate further research in this promising field.
5/24/2024
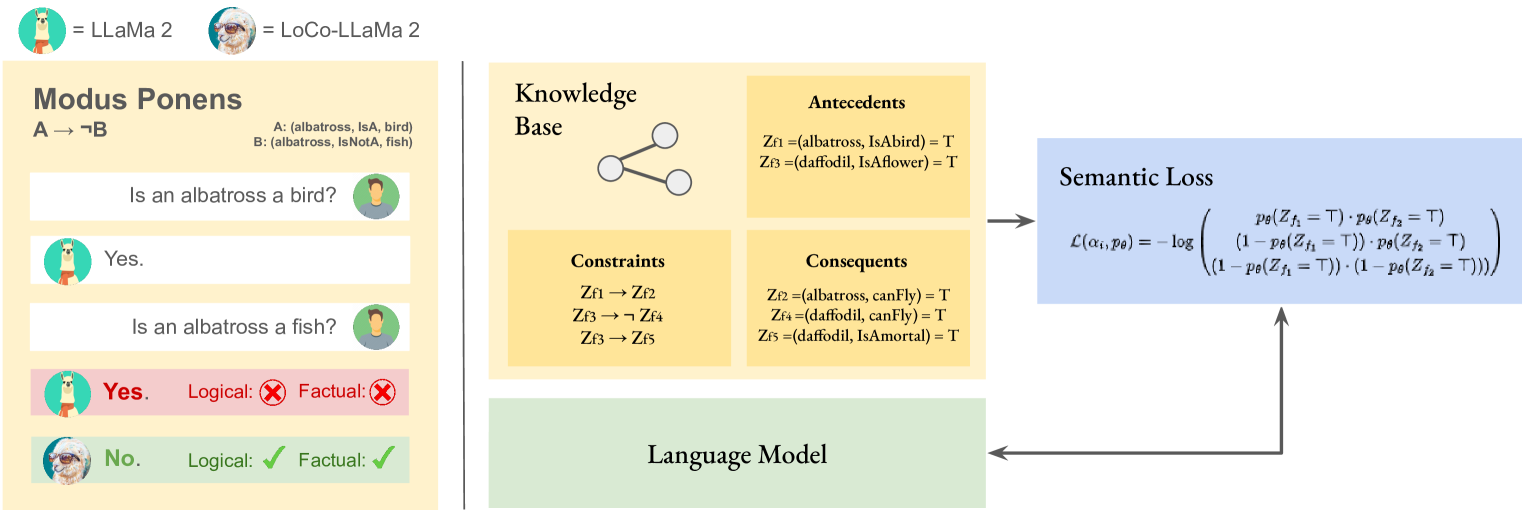
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
0
0
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
4/22/2024

A Systematic Analysis of Large Language Models as Soft Reasoners: The Case of Syllogistic Inferences
Leonardo Bertolazzi, Albert Gatt, Raffaella Bernardi
0
0
The reasoning abilities of Large Language Models (LLMs) are becoming a central focus of study in NLP. In this paper, we consider the case of syllogistic reasoning, an area of deductive reasoning studied extensively in logic and cognitive psychology. Previous research has shown that pre-trained LLMs exhibit reasoning biases, such as $textit{content effects}$, avoid answering that $textit{no conclusion follows}$, display human-like difficulties, and struggle with multi-step reasoning. We contribute to this research line by systematically investigating the effects of chain-of-thought reasoning, in-context learning (ICL), and supervised fine-tuning (SFT) on syllogistic reasoning, considering syllogisms with conclusions that support or violate world knowledge, as well as ones with multiple premises. Crucially, we go beyond the standard focus on accuracy, with an in-depth analysis of the conclusions generated by the models. Our results suggest that the behavior of pre-trained LLMs can be explained by heuristics studied in cognitive science and that both ICL and SFT improve model performance on valid inferences, although only the latter mitigates most reasoning biases without harming model consistency.
6/18/2024