Lucy: Think and Reason to Solve Text-to-SQL

0
🤖
Sign in to get full access
Overview
- Large language models (LLMs) have shown great promise in helping users query databases using natural language.
- However, their performance significantly drops when applied to large enterprise databases with many tables and complex relationships.
- The researchers propose a new solution that combines the power of LLMs in understanding questions with automated reasoning techniques to handle complex database constraints.
- They have developed a new framework that outperforms state-of-the-art techniques in zero-shot text-to-SQL on complex benchmarks.
Plain English Explanation
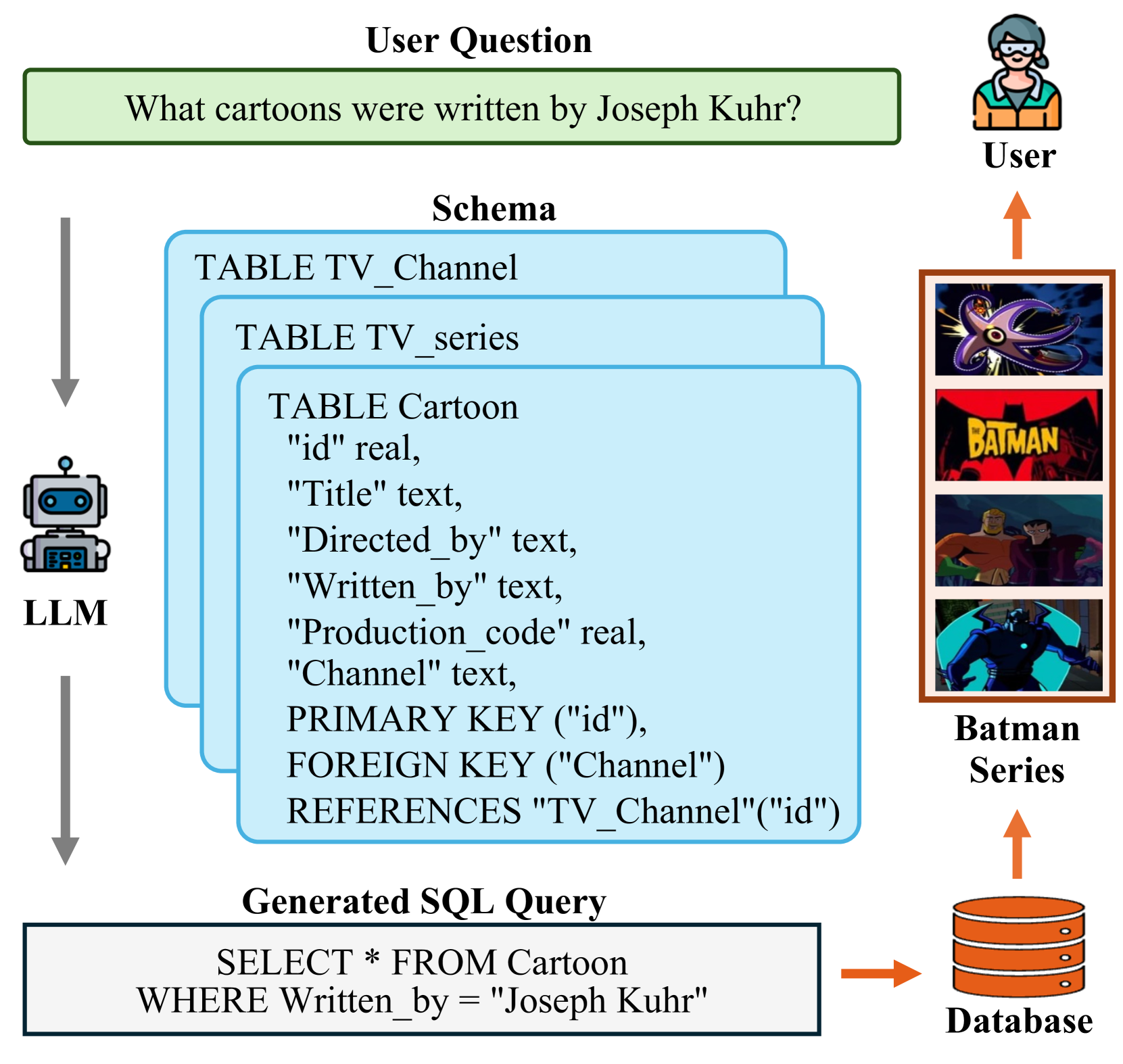
Large language models (LLMs) have made it easier for people to interact with databases using everyday language, rather than having to learn complex database query languages like SQL. However, when these LLM-based techniques are applied to large enterprise databases with many different tables and complex relationships between them, their performance drops significantly.
The reason for this is that LLMs struggle to fully understand and reason about the complex structure and constraints of these large databases. They have a hard time grasping all the different tables and how they are connected.
To address this challenge, the researchers have developed a new solution that combines the natural language understanding capabilities of LLMs with automated reasoning techniques. This allows their system to better handle the intricate details and constraints of large enterprise databases, while still providing an easy-to-use natural language interface for users.
Technical Explanation
The researchers first analyze the key challenges that LLMs face when applied to large enterprise databases. They find that the large number of tables and complex relationships between them make it difficult for LLMs to fully reason about the database structure and constraints.
To address this, the researchers propose a new framework that combines the natural language understanding capabilities of LLMs with automated reasoning techniques. This framework, called "TabSQLify," uses a table-aware encoder to better capture the structure of the database, and a reasoning module to handle complex constraints.
The researchers evaluate their framework on several challenging text-to-SQL benchmarks and show that it outperforms other state-of-the-art approaches. They also compare the resource utilization of their framework to traditional SQL-based systems, demonstrating its efficiency.
Critical Analysis
The researchers acknowledge that while their framework outperforms existing approaches, there is still room for improvement. They note that further research is needed to enhance the reasoning capabilities of LLMs and better handle the complexities of large enterprise databases.
Additionally, the researchers highlight the importance of incorporating domain-specific knowledge and constraints into the reasoning process, which could further improve the system's performance. They also suggest exploring ways to better leverage the contextual information in the user's query to guide the reasoning process.
Overall, the researchers have made a significant contribution to the field of natural language database interfaces, but there are still opportunities for further refinement and advancement of their approach.
Conclusion
The researchers have developed a novel framework that combines the strengths of large language models and automated reasoning techniques to address the challenges of querying large enterprise databases using natural language. Their framework, TabSQLify, outperforms state-of-the-art approaches on complex benchmarks, demonstrating the potential for LLM-based systems to revolutionize how people interact with databases.
While this research represents an important step forward, there is still room for improvement, particularly in enhancing the reasoning capabilities of LLMs and better incorporating domain-specific knowledge. As this field continues to evolve, we can expect to see even more seamless and powerful natural language database interfaces that make it easier for users to access and extract insights from large and complex data sets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Lucy: Think and Reason to Solve Text-to-SQL
Nina Narodytska, Shay Vargaftik
Large Language Models (LLMs) have made significant progress in assisting users to query databases in natural language. While LLM-based techniques provide state-of-the-art results on many standard benchmarks, their performance significantly drops when applied to large enterprise databases. The reason is that these databases have a large number of tables with complex relationships that are challenging for LLMs to reason about. We analyze challenges that LLMs face in these settings and propose a new solution that combines the power of LLMs in understanding questions with automated reasoning techniques to handle complex database constraints. Based on these ideas, we have developed a new framework that outperforms state-of-the-art techniques in zero-shot text-to-SQL on complex benchmarks
Read more7/9/2024
0
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, Xiao Huang
Generating accurate SQL from natural language questions (text-to-SQL) is a long-standing challenge due to the complexities in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems, comprising human engineering and deep neural networks, have made substantial progress. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex, the corresponding user questions also grow more challenging, causing PLMs with parameter constraints to produce incorrect SQL. This necessitates more sophisticated and tailored optimization methods, which, in turn, restricts the applications of PLM-based systems. Recently, large language models (LLMs) have demonstrated significant capabilities in natural language understanding as the model scale increases. Therefore, integrating LLM-based implementation can bring unique opportunities, improvements, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the technical challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future research directions.
Read more7/17/2024
📊
0
Making LLMs Work for Enterprise Data Tasks
c{C}au{g}atay Demiralp, Fabian Wenz, Peter Baile Chen, Moe Kayali, Nesime Tatbul, Michael Stonebraker
Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
Read more7/31/2024

0
A Survey on Employing Large Language Models for Text-to-SQL Tasks
Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang
The increasing volume of data stored in relational databases has led to the need for efficient querying and utilization of this data in various sectors. However, writing SQL queries requires specialized knowledge, which poses a challenge for non-professional users trying to access and query databases. Text-to-SQL parsing solves this issue by converting natural language queries into SQL queries, thus making database access more accessible for non-expert users. To take advantage of the recent developments in Large Language Models (LLMs), a range of new methods have emerged, with a primary focus on prompt engineering and fine-tuning. This survey provides a comprehensive overview of LLMs in text-to-SQL tasks, discussing benchmark datasets, prompt engineering, fine-tuning methods, and future research directions. We hope this review will enable readers to gain a broader understanding of the recent advances in this field and offer some insights into its future trajectory.
Read more9/10/2024