A Survey in Mathematical Language Processing
2205.15231
0
0
💬
Abstract
Informal mathematical text underpins real-world quantitative reasoning and communication. Developing sophisticated methods of retrieval and abstraction from this dual modality is crucial in the pursuit of the vision of automating discovery in quantitative science and mathematics. We track the development of informal mathematical language processing approaches across five strategic sub-areas in recent years, highlighting the prevailing successful methodological elements along with existing limitations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Informal mathematical text is crucial for quantitative reasoning and communication in the real world.
- Developing sophisticated methods to retrieve and abstract information from this dual modality (text and mathematical content) is key to automating discovery in quantitative science and mathematics.
- This paper tracks the development of approaches for processing informal mathematical language across five strategic sub-areas in recent years, highlighting both successes and limitations.
Plain English Explanation
Mathematical concepts and reasoning are often expressed in informal, natural language rather than formal, symbolic representations. This informal mathematical text is critical for how quantitative information is understood and communicated in the real world.
To automate the process of scientific and mathematical discovery, researchers need to develop advanced techniques to extract and abstract key information from this dual modality of text and mathematical content.
This paper examines the progress made in this area over recent years, looking at five key sub-topics. It identifies the methodological elements that have been most successful, as well as the limitations that still exist in this rapidly evolving field.
Technical Explanation
The paper tracks the development of approaches for processing informal mathematical language across five strategic sub-areas:
- Recognizing and extracting mathematical expressions from text
- Interpreting the semantics and logical structure of informal mathematical content
- Aligning informal mathematical text with formal representations
- Generating natural language explanations of mathematical concepts and procedures
- Applying language models to automate mathematical reasoning and problem-solving
For each sub-area, the authors highlight the prevailing successful methodological elements, such as the use of large language models and advanced natural language processing techniques. They also discuss the existing limitations and challenges that researchers continue to grapple with.
Critical Analysis
The paper provides a comprehensive overview of the progress made in processing informal mathematical language using modern AI and natural language processing techniques. However, it also acknowledges the significant challenges that remain, particularly in areas like semantic understanding, logical reasoning, and generating human-like explanations of mathematical concepts.
One potential limitation is that the review is focused on recent research, so it may not capture the full historical context and evolution of this field. Additionally, the paper does not delve deeply into the specific architectural choices, training approaches, or evaluation methodologies used in the various studies it cites.
Overall, this paper serves as a valuable snapshot of the current state of the art in using large language models for mathematical de-formalization and naturalization, highlighting both the exciting progress and the substantial work that remains to be done in this important area of research.
Conclusion
Informal mathematical text is a crucial component of real-world quantitative reasoning and communication. Developing effective methods to retrieve and abstract information from this dual modality of text and mathematical content is crucial for automating scientific and mathematical discovery.
This paper provides a comprehensive overview of recent research progress in this area, identifying both successful methodological elements and persistent limitations. While significant strides have been made, particularly through the use of large language models, substantial challenges remain in areas like semantic understanding, logical reasoning, and generating human-like explanations of mathematical concepts.
Overcoming these challenges will be key to realizing the vision of AI systems that can truly assist and collaborate with humans in the pursuit of quantitative knowledge and insights.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
0
0
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
4/8/2024
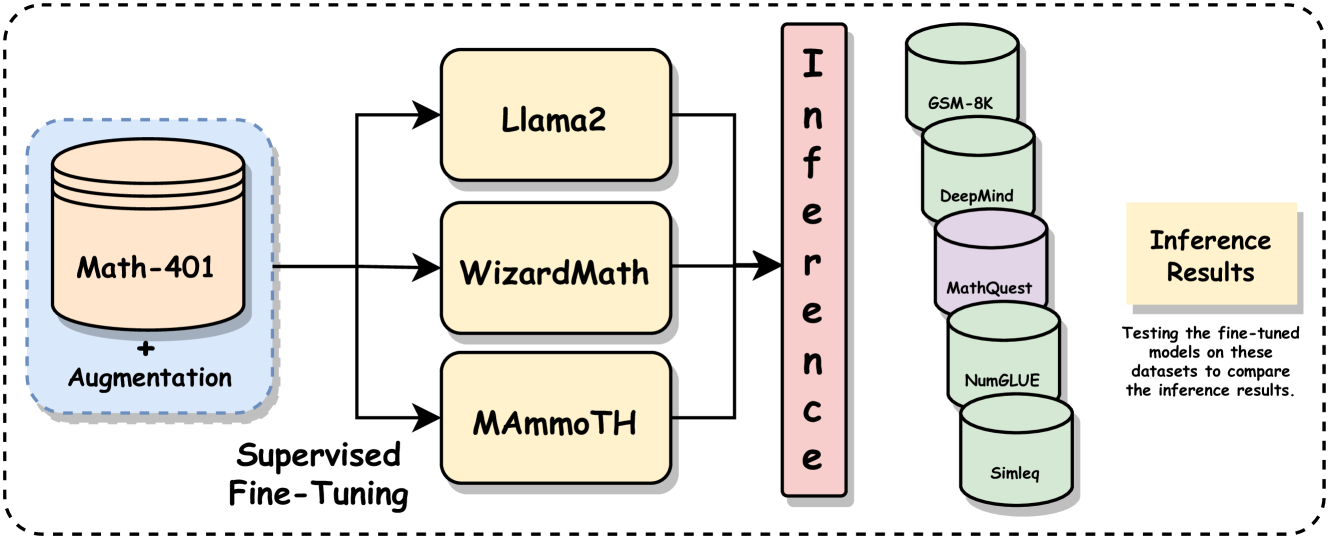
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024
💬
Can Large Language Models put 2 and 2 together? Probing for Entailed Arithmetical Relationships
D. Panas, S. Seth, V. Belle
0
0
Two major areas of interest in the era of Large Language Models regard questions of what do LLMs know, and if and how they may be able to reason (or rather, approximately reason). Since to date these lines of work progressed largely in parallel (with notable exceptions), we are interested in investigating the intersection: probing for reasoning about the implicitly-held knowledge. Suspecting the performance to be lacking in this area, we use a very simple set-up of comparisons between cardinalities associated with elements of various subjects (e.g. the number of legs a bird has versus the number of wheels on a tricycle). We empirically demonstrate that although LLMs make steady progress in knowledge acquisition and (pseudo)reasoning with each new GPT release, their capabilities are limited to statistical inference only. It is difficult to argue that pure statistical learning can cope with the combinatorial explosion inherent in many commonsense reasoning tasks, especially once arithmetical notions are involved. Further, we argue that bigger is not always better and chasing purely statistical improvements is flawed at the core, since it only exacerbates the dangerous conflation of the production of correct answers with genuine reasoning ability.
5/1/2024
💬
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning
Jun Zhao, Jingqi Tong, Yurong Mou, Ming Zhang, Qi Zhang, Xuanjing Huang
0
0
Human cognition exhibits systematic compositionality, the algebraic ability to generate infinite novel combinations from finite learned components, which is the key to understanding and reasoning about complex logic. In this work, we investigate the compositionality of large language models (LLMs) in mathematical reasoning. Specifically, we construct a new dataset textsc{MathTrap}footnotemark[3] by introducing carefully designed logical traps into the problem descriptions of MATH and GSM8k. Since problems with logical flaws are quite rare in the real world, these represent ``unseen'' cases to LLMs. Solving these requires the models to systematically compose (1) the mathematical knowledge involved in the original problems with (2) knowledge related to the introduced traps. Our experiments show that while LLMs possess both components of requisite knowledge, they do not textbf{spontaneously} combine them to handle these novel cases. We explore several methods to mitigate this deficiency, such as natural language prompts, few-shot demonstrations, and fine-tuning. We find that LLMs' performance can be textbf{passively} improved through the above external intervention. Overall, systematic compositionality remains an open challenge for large language models.
5/14/2024