Survey on Plagiarism Detection in Large Language Models: The Impact of ChatGPT and Gemini on Academic Integrity

0
Sign in to get full access
Overview
- This paper surveys the impact of large language models (LLMs) like ChatGPT and Gemini on plagiarism detection and academic integrity.
- It explores the challenges posed by these advanced AI systems in terms of their ability to generate human-like text that can bypass traditional plagiarism detection methods.
- The paper also discusses various approaches and tools being developed to address this issue and maintain academic honesty in the face of increasingly sophisticated AI-generated content.
Plain English Explanation
Large language models like ChatGPT and Gemini have revolutionized the field of natural language processing, with their ability to generate highly coherent and human-like text. However, this capability also poses a significant challenge for academic integrity, as these AI systems can be used to produce content that may be difficult to distinguish from original work.
The paper explores this issue in depth, examining the ways in which LLMs can be leveraged for plagiarism and the impact this has on the academic landscape. It highlights the need for new approaches to plagiarism detection that can effectively identify AI-generated content, as traditional methods may no longer be sufficient.
The researchers discuss various tools and techniques that are being developed to address this problem, such as PlagBench, which aims to benchmark the performance of plagiarism detection systems against LLM-generated content. They also explore the role of content monitoring and the impact of LLM usage in academic writing.
Overall, the paper highlights the need for a multifaceted approach to addressing the plagiarism challenge posed by advanced AI systems, involving technological solutions, educational initiatives, and policy-level changes to maintain the integrity of academic work.
Technical Explanation
The paper begins by outlining the growing problem of plagiarism in academia, driven in part by the emergence of LLMs like ChatGPT and Gemini. These models have demonstrated remarkable abilities to generate human-like text, making it increasingly difficult for traditional plagiarism detection tools to identify AI-generated content.
The researchers discuss various approaches being developed to address this challenge, including PlagBench, a benchmark specifically designed to test the performance of plagiarism detection systems against LLM-generated text. The paper also explores content monitoring techniques that aim to detect and flag AI-generated content at scale, as well as studies on the impact of LLM usage in academic writing.
Additionally, the paper reviews the comparative performance of LLMs on conversational QA tasks, which can provide insights into the capabilities and limitations of these models in generating human-like responses.
The researchers also discuss the broader implications of LLMs for the future of learning, exploring how these powerful AI systems may shape the educational landscape and the ways in which we assess and validate academic work.
Critical Analysis
The paper acknowledges the significant challenges posed by LLMs in the context of plagiarism detection and academic integrity. It rightly highlights the need for a multifaceted approach, encompassing technological solutions, educational initiatives, and policy-level changes, to effectively address this issue.
While the paper provides a comprehensive survey of the current state of research in this area, it would be helpful to see a more in-depth discussion of the limitations and potential drawbacks of the proposed solutions. For example, the effectiveness and scalability of content monitoring approaches, as well as the potential for adversarial attacks on plagiarism detection systems, could be further explored.
Additionally, the paper could benefit from a more critical examination of the broader societal implications of LLMs in the academic context. How might these technologies exacerbate existing inequalities or create new challenges for students and educators from diverse backgrounds? What ethical considerations should be taken into account as these technologies become more prevalent in academic settings?
Overall, the paper provides a valuable contribution to the ongoing discussion on the impact of LLMs on academic integrity. By continuing to encourage critical thinking and nuanced analysis, researchers can help ensure that the benefits of these powerful AI systems are harnessed in a way that preserves the integrity and fairness of academic work.
Conclusion
This paper offers a comprehensive survey of the growing challenge of plagiarism detection in the era of large language models like ChatGPT and Gemini. It highlights the significant impact these advanced AI systems can have on academic integrity, as their ability to generate human-like text makes it increasingly difficult for traditional plagiarism detection methods to identify AI-generated content.
The researchers discuss various approaches being developed to address this issue, including benchmarking tools, content monitoring techniques, and studies on the usage of LLMs in academic writing. By exploring these solutions and the broader implications for the future of learning, the paper provides valuable insights for researchers, educators, and policymakers working to maintain the integrity of academic work in the face of rapidly evolving AI technologies.
As LLMs continue to advance, the need for a comprehensive and multifaceted response to the plagiarism challenge will only grow more pressing. This paper serves as an important contribution to this ongoing conversation, and its findings can help guide the development of more robust and effective strategies for preserving academic honesty in the digital age.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Survey on Plagiarism Detection in Large Language Models: The Impact of ChatGPT and Gemini on Academic Integrity
Shushanta Pudasaini, Luis Miralles-Pechu'an, David Lillis, Marisa Llorens Salvador
The rise of Large Language Models (LLMs) such as ChatGPT and Gemini has posed new challenges for the academic community. With the help of these models, students can easily complete their assignments and exams, while educators struggle to detect AI-generated content. This has led to a surge in academic misconduct, as students present work generated by LLMs as their own, without putting in the effort required for learning. As AI tools become more advanced and produce increasingly human-like text, detecting such content becomes more challenging. This development has significantly impacted the academic world, where many educators are finding it difficult to adapt their assessment methods to this challenge. This research first demonstrates how LLMs have increased academic dishonesty, and then reviews state-of-the-art solutions for academic plagiarism in detail. A survey of datasets, algorithms, tools, and evasion strategies for plagiarism detection has been conducted, focusing on how LLMs and AI-generated content (AIGC) detection have affected this area. The survey aims to identify the gaps in existing solutions. Lastly, potential long-term solutions are presented to address the issue of academic plagiarism using LLMs based on AI tools and educational approaches in an ever-changing world.
Read more7/19/2024

0
PlagBench: Exploring the Duality of Large Language Models in Plagiarism Generation and Detection
Jooyoung Lee, Toshini Agrawal, Adaku Uchendu, Thai Le, Jinghui Chen, Dongwon Lee
Recent literature has highlighted potential risks to academic integrity associated with large language models (LLMs), as they can memorize parts of training instances and reproduce them in the generated texts without proper attribution. In addition, given their capabilities in generating high-quality texts, plagiarists can exploit LLMs to generate realistic paraphrases or summaries indistinguishable from original work. In response to possible malicious use of LLMs in plagiarism, we introduce PlagBench, a comprehensive dataset consisting of 46.5K synthetic plagiarism cases generated using three instruction-tuned LLMs across three writing domains. The quality of PlagBench is ensured through fine-grained automatic evaluation for each type of plagiarism, complemented by human annotation. We then leverage our proposed dataset to evaluate the plagiarism detection performance of five modern LLMs and three specialized plagiarism checkers. Our findings reveal that GPT-3.5 tends to generates paraphrases and summaries of higher quality compared to Llama2 and GPT-4. Despite LLMs' weak performance in summary plagiarism identification, they can surpass current commercial plagiarism detectors. Overall, our results highlight the potential of LLMs to serve as robust plagiarism detection tools.
Read more6/26/2024
1
Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Weixin Liang, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, Haotian Ye, Sheng Liu, Zhi Huang, Daniel A. McFarland, James Y. Zou
We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.
Read more6/18/2024
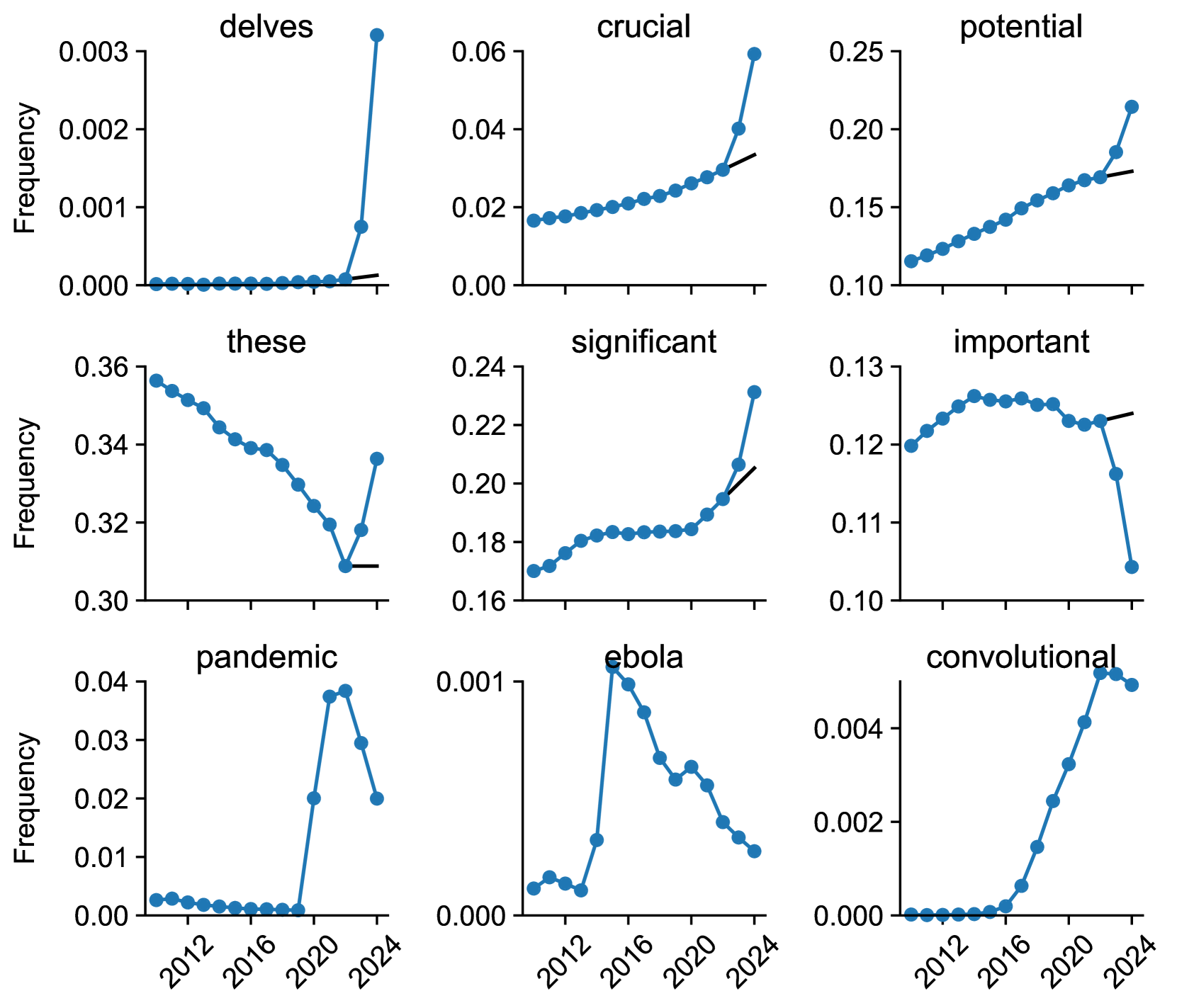
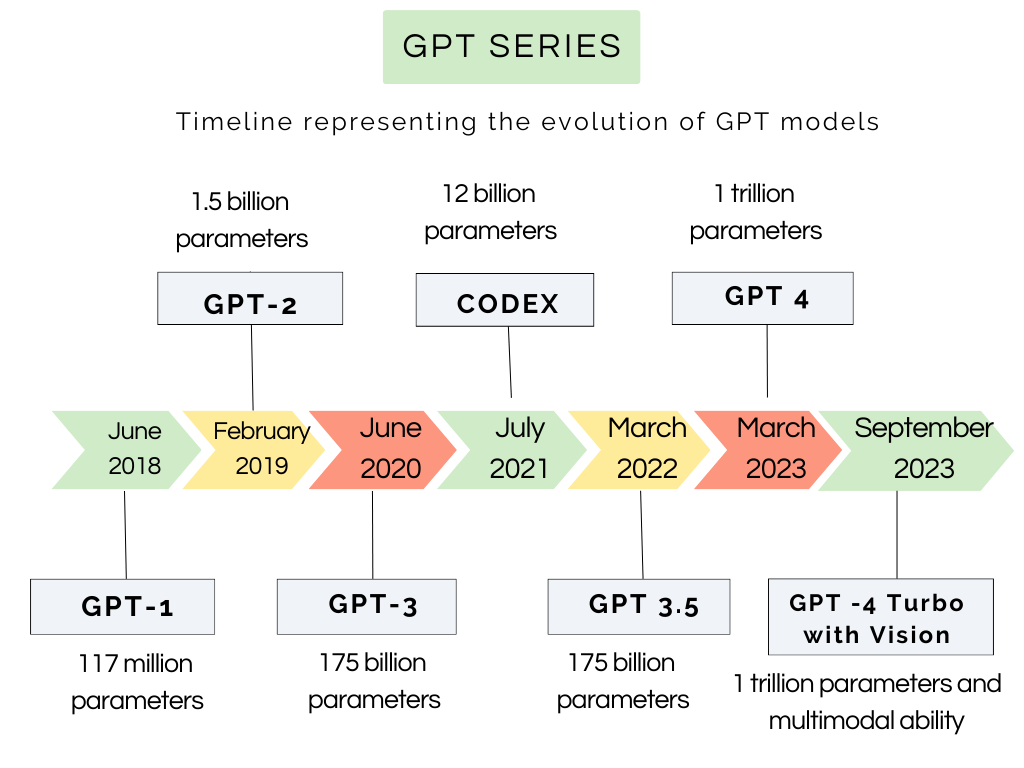
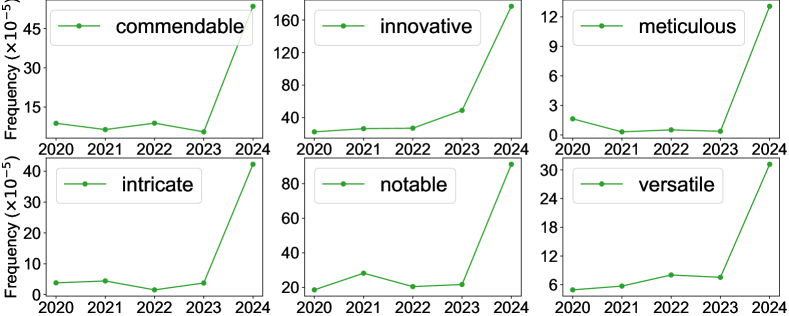
114
Delving into ChatGPT usage in academic writing through excess vocabulary
Dmitry Kobak, Rita Gonz'alez-M'arquez, EmH{o}ke-'Agnes Horv'at, Jan Lause
Recent large language models (LLMs) can generate and revise text with human-level performance, and have been widely commercialized in systems like ChatGPT. These models come with clear limitations: they can produce inaccurate information, reinforce existing biases, and be easily misused. Yet, many scientists have been using them to assist their scholarly writing. How wide-spread is LLM usage in the academic literature currently? To answer this question, we use an unbiased, large-scale approach, free from any assumptions on academic LLM usage. We study vocabulary changes in 14 million PubMed abstracts from 2010-2024, and show how the appearance of LLMs led to an abrupt increase in the frequency of certain style words. Our analysis based on excess words usage suggests that at least 10% of 2024 abstracts were processed with LLMs. This lower bound differed across disciplines, countries, and journals, and was as high as 30% for some PubMed sub-corpora. We show that the appearance of LLM-based writing assistants has had an unprecedented impact in the scientific literature, surpassing the effect of major world events such as the Covid pandemic.
Read more7/4/2024