A Survey on Text-guided 3D Visual Grounding: Elements, Recent Advances, and Future Directions
2406.05785
0
0

Abstract
Text-guided 3D visual grounding (T-3DVG), which aims to locate a specific object that semantically corresponds to a language query from a complicated 3D scene, has drawn increasing attention in the 3D research community over the past few years. Compared to 2D visual grounding, this task presents great potential and challenges due to its closer proximity to the real world and the complexity of data collection and 3D point cloud source processing. In this survey, we attempt to provide a comprehensive overview of the T-3DVG progress, including its fundamental elements, recent research advances, and future research directions. To the best of our knowledge, this is the first systematic survey on the T-3DVG task. Specifically, we first provide a general structure of the T-3DVG pipeline with detailed components in a tutorial style, presenting a complete background overview. Then, we summarize the existing T-3DVG approaches into different categories and analyze their strengths and weaknesses. We also present the benchmark datasets and evaluation metrics to assess their performances. Finally, we discuss the potential limitations of existing T-3DVG and share some insights on several promising research directions. The latest papers are continually collected at https://github.com/liudaizong/Awesome-3D-Visual-Grounding.
Create account to get full access
Overview
• This paper provides a comprehensive survey of the field of text-guided 3D visual grounding, which involves using language to identify and localize 3D objects in visual scenes.
• The survey covers the key elements of this task, including cross-modal reasoning, multimodal learning, 3D scene understanding, object retrieval, and the intersection of vision and language.
• It also reviews recent advancements in this area and outlines promising future research directions.
Plain English Explanation
Text-guided 3D visual grounding is the process of using language to find and locate 3D objects in three-dimensional visual environments. Imagine you're looking at a 3D virtual room and someone says "Can you point to the blue chair in the corner?" Being able to understand the language cue ("blue chair") and then identify and highlight the correct 3D object in the scene is the essence of this task.
This paper provides an overview of the key components involved, such as the ability to reason across language and visual data, learn from multimodal (text and image) information, and build 3D scene understanding. It also covers how this can be used for practical applications like object retrieval, where you could search for a specific 3D item in a larger database using natural language.
The survey highlights recent progress in this area, including new algorithms and datasets that have advanced the state-of-the-art. Importantly, it also outlines promising future research directions, such as enhancing the data efficiency of 3D visual grounding models and addressing issues of hallucination and better grounding in 3D scenes.
Technical Explanation
The paper begins by defining the key elements of text-guided 3D visual grounding, including the need for cross-modal reasoning to connect language and visual information, the use of multimodal learning techniques, and the importance of 3D scene understanding. It also discusses how this task relates to other areas like object retrieval and the intersection of vision and language.
The survey then reviews recent advancements in this field, covering new datasets like Weakly-Supervised 3D Visual Grounding and COT-3DRef, as well as innovative modeling approaches such as data-efficient 3D visual grounding and text-to-3D content generation.
The authors also discuss several open challenges and future research directions, including the need for better grounding and less hallucination in 3D scenes, as well as the potential to leverage language for more data-efficient 3D learning.
Critical Analysis
The survey provides a thorough and well-structured overview of the text-guided 3D visual grounding field, covering the key elements, recent advances, and promising future directions. The authors have done an excellent job of synthesizing a large body of work and highlighting the core technical insights.
One potential limitation is that the paper does not delve deeply into the specific architectural details or training approaches of the reviewed models. While the high-level summaries are informative, readers interested in replicating or building upon this research may benefit from more granular technical descriptions.
Additionally, the survey could have further explored the real-world implications and potential societal impacts of this technology. As language-guided 3D understanding becomes more sophisticated, it will be important to consider issues of bias, privacy, and ethical deployment.
Overall, this paper serves as a valuable reference for researchers and practitioners in the fields of computer vision, natural language processing, and 3D scene understanding. By outlining the current state-of-the-art and future research directions, it provides a roadmap for advancing the state of the art in text-guided 3D visual grounding.
Conclusion
This comprehensive survey paper offers a thorough overview of the text-guided 3D visual grounding field, covering its key elements, recent advancements, and promising future research directions. By synthesizing a diverse body of work, the authors have provided the community with a valuable resource for understanding the current state of the art and exploring new avenues for innovation. As the intersections of language, vision, and 3D understanding continue to evolve, this survey will serve as an important guide for researchers and practitioners working to push the boundaries of what's possible in this exciting and rapidly progressing area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Weakly-Supervised 3D Visual Grounding based on Visual Linguistic Alignment
Xiaoxu Xu, Yitian Yuan, Qiudan Zhang, Wenhui Wu, Zequn Jie, Lin Ma, Xu Wang
0
0
Learning to ground natural language queries to target objects or regions in 3D point clouds is quite essential for 3D scene understanding. Nevertheless, existing 3D visual grounding approaches require a substantial number of bounding box annotations for text queries, which is time-consuming and labor-intensive to obtain. In this paper, we propose textbf{3D-VLA}, a weakly supervised approach for textbf{3D} visual grounding based on textbf{V}isual textbf{L}inguistic textbf{A}lignment. Our 3D-VLA exploits the superior ability of current large-scale vision-language models (VLMs) on aligning the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds with no need for fine-grained box annotations in the training procedure. During the inference stage, the learned text-3D correspondence will help us ground the text queries to the 3D target objects even without 2D images. To the best of our knowledge, this is the first work to investigate 3D visual grounding in a weakly supervised manner by involving large scale vision-language models, and extensive experiments on ReferIt3D and ScanRefer datasets demonstrate that our 3D-VLA achieves comparable and even superior results over the fully supervised methods.
4/16/2024

CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
Eslam Mohamed Bakr, Mohamed Ayman, Mahmoud Ahmed, Habib Slim, Mohamed Elhoseiny
0
0
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence Seq2Seq task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data. The code is available at https:eslambakr.github.io/cot3dref.github.io/.
4/23/2024
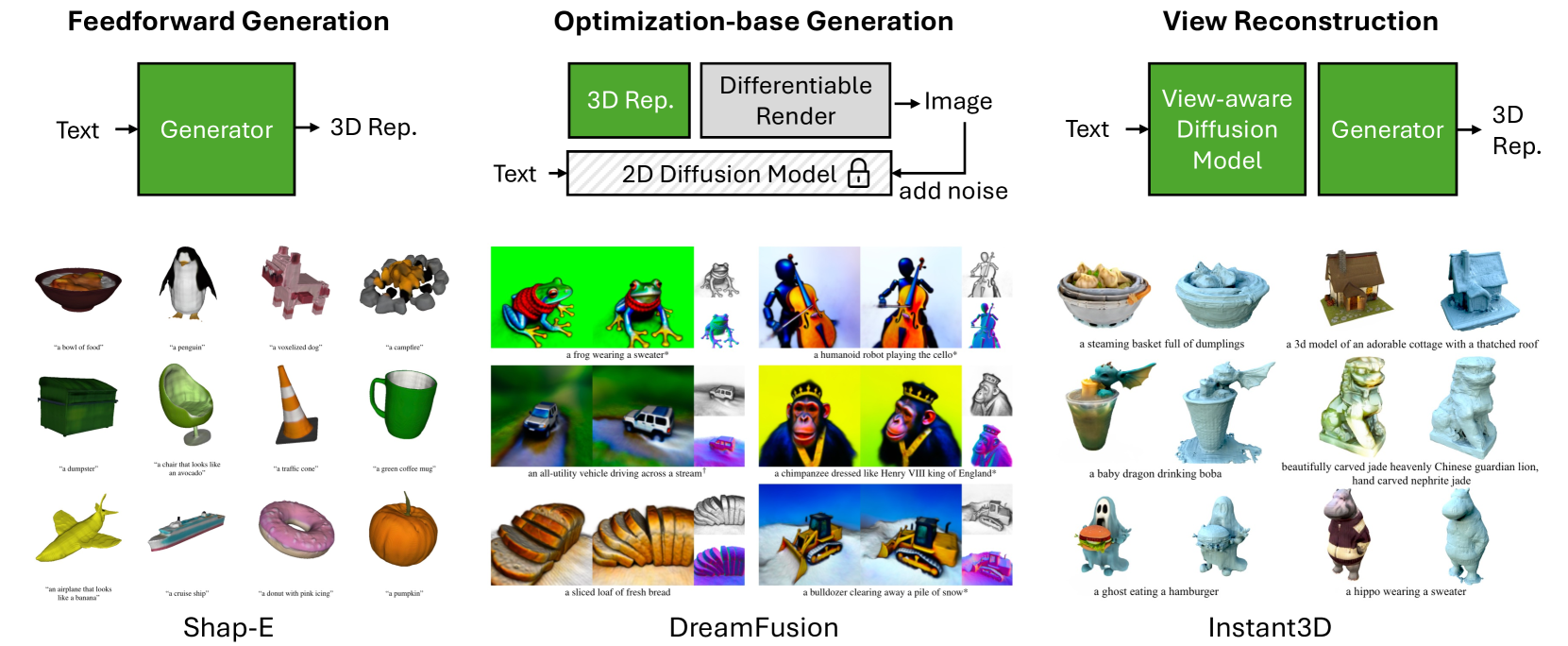
A Survey On Text-to-3D Contents Generation In The Wild
Chenhan Jiang
0
0
3D content creation plays a vital role in various applications, such as gaming, robotics simulation, and virtual reality. However, the process is labor-intensive and time-consuming, requiring skilled designers to invest considerable effort in creating a single 3D asset. To address this challenge, text-to-3D generation technologies have emerged as a promising solution for automating 3D creation. Leveraging the success of large vision language models, these techniques aim to generate 3D content based on textual descriptions. Despite recent advancements in this area, existing solutions still face significant limitations in terms of generation quality and efficiency. In this survey, we conduct an in-depth investigation of the latest text-to-3D creation methods. We provide a comprehensive background on text-to-3D creation, including discussions on datasets employed in training and evaluation metrics used to assess the quality of generated 3D models. Then, we delve into the various 3D representations that serve as the foundation for the 3D generation process. Furthermore, we present a thorough comparison of the rapidly growing literature on generative pipelines, categorizing them into feedforward generators, optimization-based generation, and view reconstruction approaches. By examining the strengths and weaknesses of these methods, we aim to shed light on their respective capabilities and limitations. Lastly, we point out several promising avenues for future research. With this survey, we hope to inspire researchers further to explore the potential of open-vocabulary text-conditioned 3D content creation.
5/16/2024
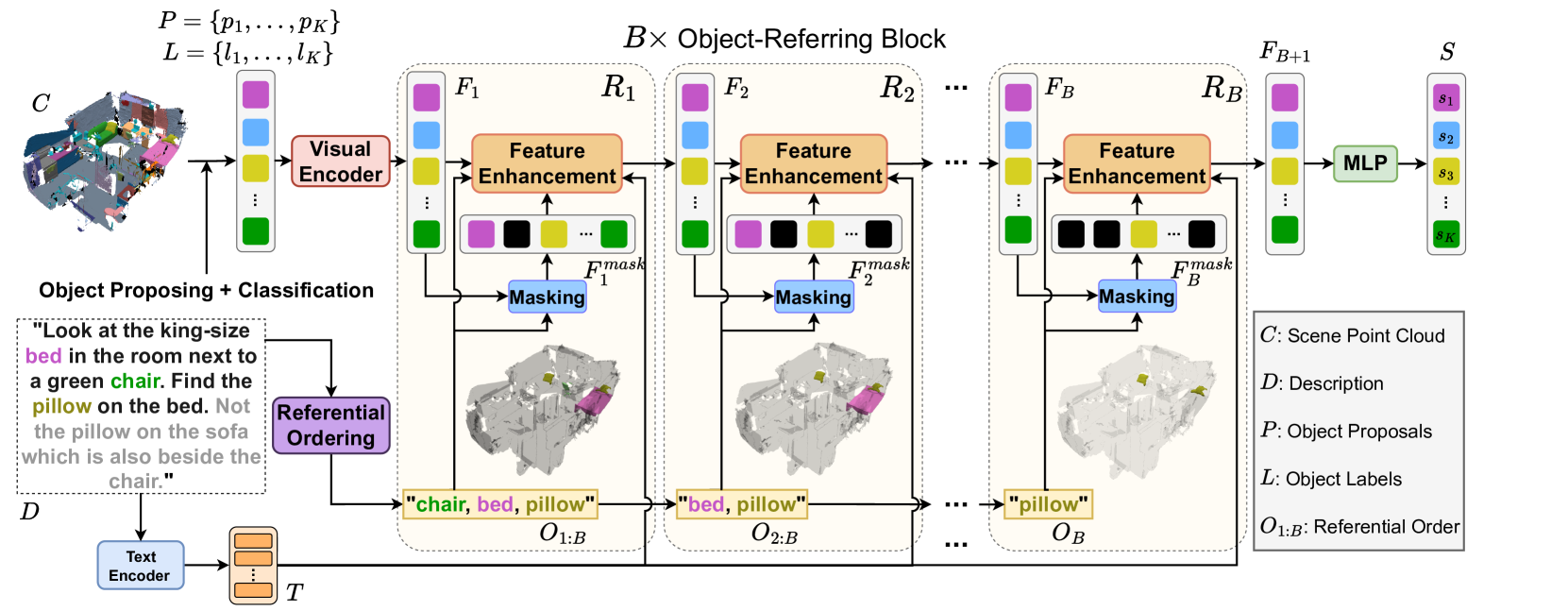
Data-Efficient 3D Visual Grounding via Order-Aware Referring
Tung-Yu Wu, Sheng-Yu Huang, Yu-Chiang Frank Wang
0
0
3D visual grounding aims to identify the target object within a 3D point cloud scene referred to by a natural language description. Previous works usually require significant data relating to point color and their descriptions to exploit the corresponding complicated verbo-visual relations. In our work, we introduce Vigor, a novel Data-Efficient 3D Visual Grounding framework via Order-aware Referring. Vigor leverages LLM to produce a desirable referential order from the input description for 3D visual grounding. With the proposed stacked object-referring blocks, the predicted anchor objects in the above order allow one to locate the target object progressively without supervision on the identities of anchor objects or exact relations between anchor/target objects. In addition, we present an order-aware warm-up training strategy, which augments referential orders for pre-training the visual grounding framework. This allows us to better capture the complex verbo-visual relations and benefit the desirable data-efficient learning scheme. Experimental results on the NR3D and ScanRefer datasets demonstrate our superiority in low-resource scenarios. In particular, Vigor surpasses current state-of-the-art frameworks by 9.3% and 7.6% grounding accuracy under 1% data and 10% data settings on the NR3D dataset, respectively.
6/3/2024