SVP: Style-Enhanced Vivid Portrait Talking Head Diffusion Model

0

Sign in to get full access
Overview
- This paper presents a novel diffusion-based model called SVP (Style-Enhanced Vivid Portrait) for generating highly realistic talking head videos.
- The model aims to produce vivid and stylistically consistent facial animations driven by speech input.
- Key innovations include leveraging style information and a multi-stage diffusion process to enhance the realism and quality of the generated outputs.
Plain English Explanation
The SVP model is a new kind of AI system that can create very lifelike videos of a person's face moving and talking. It takes audio input, like someone speaking, and uses that to generate a video of a person's face that matches the speech.
One of the main innovations is that the model can capture the unique "style" of a person's face and expressions. This helps the generated video look more consistent and natural, like it's really the same person speaking. The model also uses a multi-step process, called diffusion, to gradually build up the final video in a way that makes it look extremely realistic and vivid.
Overall, the SVP model represents an important advance in the field of talking head generation, allowing for the creation of highly convincing videos that could have many practical applications, such as in animation, video production, and virtual assistants.
Technical Explanation
The key technical aspects of the SVP model include:
-
Style Encoding: The model learns to encode the unique style of a person's face and facial expressions, which it then uses to guide the generation process and maintain consistency.
-
Multi-Stage Diffusion: SVP employs a multi-stage diffusion process, where an initial low-resolution output is progressively refined through multiple steps to achieve high-fidelity, realistic talking head videos.
-
Conditional Generation: The model conditions the generation process on both the input speech audio and the learned style information, allowing it to produce speech-synchronized animations that match the individual's visual characteristics.
-
Architectural Innovations: The model utilizes a combination of neural network components, such as audio encoders, style encoders, and diffusion-based generators, to enable the effective integration of speech, style, and video generation.
Through these technical innovations, the SVP model is able to generate highly vivid and stylistically consistent talking head videos that outperform previous approaches in terms of realism and quality.
Critical Analysis
The paper provides a comprehensive evaluation of the SVP model, demonstrating its superiority over existing talking head synthesis techniques across various metrics. However, some potential limitations and areas for further research are worth considering:
-
Generalization Capabilities: While the model shows strong performance on the evaluated datasets, its ability to generalize to a wider range of speakers, styles, and speaking scenarios may require further investigation.
-
Computational Efficiency: The multi-stage diffusion process used by SVP may have higher computational and memory requirements compared to some alternative approaches, which could limit its deployment in certain real-time applications.
-
Ethical Considerations: As with any advanced generative model, there are potential ethical concerns around the use of SVP for the creation of fake or manipulated media. Responsible development and deployment of such technologies is crucial.
Overall, the SVP model represents a significant advancement in the field of talking head generation and has the potential to enable a wide range of applications. Continued research and careful consideration of the model's limitations and ethical implications will be important for the continued progress of this technology.
Conclusion
The SVP model presented in this paper is a remarkable achievement in the field of talking head generation. By leveraging style information and a multi-stage diffusion process, the model is able to produce highly realistic and stylistically consistent facial animations driven by speech input. This advancement has the potential to enable a wide range of applications, from virtual assistants to animated content creation.
While the paper showcases the model's impressive performance, further research is needed to address potential limitations and ethical considerations. Nonetheless, the SVP model represents a significant step forward in the quest to create highly convincing and versatile talking head systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SVP: Style-Enhanced Vivid Portrait Talking Head Diffusion Model
Weipeng Tan, Chuming Lin, Chengming Xu, Xiaozhong Ji, Junwei Zhu, Chengjie Wang, Yanwei Fu
Talking Head Generation (THG), typically driven by audio, is an important and challenging task with broad application prospects in various fields such as digital humans, film production, and virtual reality. While diffusion model-based THG methods present high quality and stable content generation, they often overlook the intrinsic style which encompasses personalized features such as speaking habits and facial expressions of a video. As consequence, the generated video content lacks diversity and vividness, thus being limited in real life scenarios. To address these issues, we propose a novel framework named Style-Enhanced Vivid Portrait (SVP) which fully leverages style-related information in THG. Specifically, we first introduce the novel probabilistic style prior learning to model the intrinsic style as a Gaussian distribution using facial expressions and audio embedding. The distribution is learned through the 'bespoked' contrastive objective, effectively capturing the dynamic style information in each video. Then we finetune a pretrained Stable Diffusion (SD) model to inject the learned intrinsic style as a controlling signal via cross attention. Experiments show that our model generates diverse, vivid, and high-quality videos with flexible control over intrinsic styles, outperforming existing state-of-the-art methods.
Read more9/6/2024

0
Stable Video Portraits
Mirela Ostrek, Justus Thies
Rapid advances in the field of generative AI and text-to-image methods in particular have transformed the way we interact with and perceive computer-generated imagery today. In parallel, much progress has been made in 3D face reconstruction, using 3D Morphable Models (3DMM). In this paper, we present SVP, a novel hybrid 2D/3D generation method that outputs photorealistic videos of talking faces leveraging a large pre-trained text-to-image prior (2D), controlled via a 3DMM (3D). Specifically, we introduce a person-specific fine-tuning of a general 2D stable diffusion model which we lift to a video model by providing temporal 3DMM sequences as conditioning and by introducing a temporal denoising procedure. As an output, this model generates temporally smooth imagery of a person with 3DMM-based controls, i.e., a person-specific avatar. The facial appearance of this person-specific avatar can be edited and morphed to text-defined celebrities, without any fine-tuning at test time. The method is analyzed quantitatively and qualitatively, and we show that our method outperforms state-of-the-art monocular head avatar methods.
Read more9/27/2024
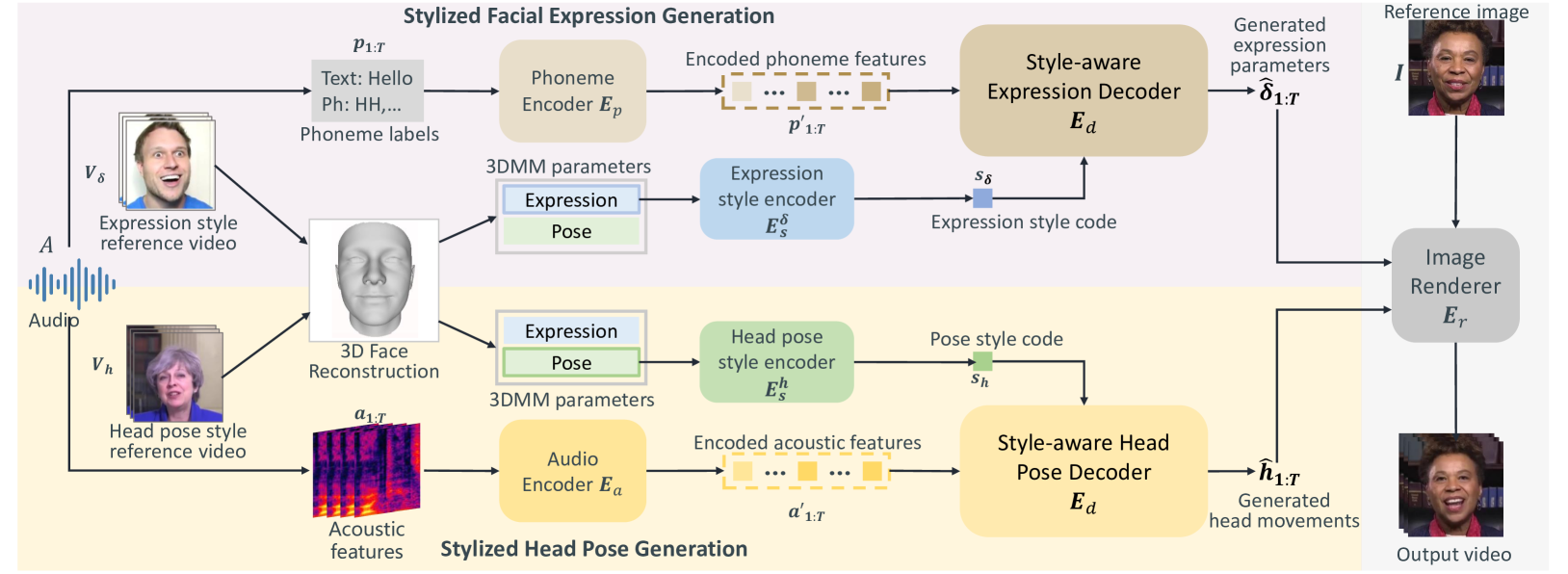
0
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Suzhen Wang, Yifeng Ma, Yu Ding, Zhipeng Hu, Changjie Fan, Tangjie Lv, Zhidong Deng, Xin Yu
Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
Read more9/17/2024
🛸
0
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, Yong-Jin Liu
The generation of stylistic 3D facial animations driven by speech presents a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. In particular, our style includes the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset are at https://diffposetalk.github.io .
Read more5/15/2024