Swarm Intelligence in Geo-Localization: A Multi-Agent Large Vision-Language Model Collaborative Framework

0
📈
Sign in to get full access
Overview
- Visual geo-localization is the task of associating images with their real-world geographic locations.
- Traditional methods based on data-matching struggle because it's impractical to store visual records of all global landmarks.
- Large Vision-Language Models (LVLMs) have shown promise for geo-localization through Visual Question Answering (VQA), without needing external geo-tagged image records.
- However, the performance of a single LVLM is limited by its inherent knowledge and reasoning capabilities.
Plain English Explanation
The paper introduces a novel visual geo-localization framework that integrates the inherent knowledge of multiple LVLM agents via inter-agent communication to achieve more effective geo-localization of images. This framework also employs a dynamic learning strategy to optimize the communication patterns among agents, reducing unnecessary discussions and improving efficiency.
The key idea is that by combining the knowledge and reasoning skills of multiple LVLMs, the framework can overcome the limitations of a single model and achieve better geo-localization performance. The dynamic learning strategy helps the agents communicate more effectively, further boosting the overall system's capabilities.
Technical Explanation
The paper presents a novel visual geo-localization framework that integrates multiple LVLM agents through inter-agent communication. This allows the system to leverage the inherent knowledge and reasoning capabilities of the individual models, going beyond what a single LVLM can achieve.
Furthermore, the framework employs a dynamic learning strategy to optimize the communication patterns among the LVLM agents. This reduces unnecessary discussions and improves the overall efficiency of the system.
To validate the effectiveness of the proposed framework, the authors construct a new dataset called GeoGlobe, specifically designed for visual geo-localization tasks. Extensive testing on this dataset demonstrates that the authors' approach significantly outperforms state-of-the-art methods.
Critical Analysis
The paper's key contribution is the development of a multi-agent framework that can leverage the combined knowledge and reasoning capabilities of multiple LVLMs to achieve superior visual geo-localization performance.
One potential limitation mentioned in the paper is that the framework's performance is still dependent on the inherent knowledge and reasoning skills of the individual LVLM agents. If the agents have fundamental shortcomings or biases, these could still affect the overall system's performance.
Additionally, the authors note that the dynamic learning strategy, while improving efficiency, may introduce some complexity in terms of training and tuning the communication patterns among the agents. This could be an area for further research and optimization.
Conclusion
This paper presents a novel multi-agent framework for visual geo-localization that integrates the knowledge and reasoning capabilities of multiple LVLM agents. By leveraging inter-agent communication and a dynamic learning strategy, the framework can achieve significantly better performance than state-of-the-art methods.
The proposed approach demonstrates the potential of combining multiple AI models to tackle complex tasks, like precisely associating images with their real-world geographic locations. As vision-language models continue to advance, this type of multi-agent framework could become an increasingly valuable tool for a wide range of geospatial applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Swarm Intelligence in Geo-Localization: A Multi-Agent Large Vision-Language Model Collaborative Framework
Xiao Han, Chen Zhu, Xiangyu Zhao, Hengshu Zhu
Visual geo-localization demands in-depth knowledge and advanced reasoning skills to associate images with real-world geographic locations precisely. In general, traditional methods based on data-matching are hindered by the impracticality of storing adequate visual records of global landmarks. Recently, Large Vision-Language Models (LVLMs) have demonstrated the capability of geo-localization through Visual Question Answering (VQA), enabling a solution that does not require external geo-tagged image records. However, the performance of a single LVLM is still limited by its intrinsic knowledge and reasoning capabilities. Along this line, in this paper, we introduce a novel visual geo-localization framework called name that integrates the inherent knowledge of multiple LVLM agents via inter-agent communication to achieve effective geo-localization of images. Furthermore, our framework employs a dynamic learning strategy to optimize the communication patterns among agents, reducing unnecessary discussions among agents and improving the efficiency of the framework. To validate the effectiveness of the proposed framework, we construct GeoGlobe, a novel dataset for visual geo-localization tasks. Extensive testing on the dataset demonstrates that our approach significantly outperforms state-of-the-art methods.
Read more8/22/2024
🤔
0
Image-Based Geolocation Using Large Vision-Language Models
Yi Liu, Junchen Ding, Gelei Deng, Yuekang Li, Tianwei Zhang, Weisong Sun, Yaowen Zheng, Jingquan Ge, Yang Liu
Geolocation is now a vital aspect of modern life, offering numerous benefits but also presenting serious privacy concerns. The advent of large vision-language models (LVLMs) with advanced image-processing capabilities introduces new risks, as these models can inadvertently reveal sensitive geolocation information. This paper presents the first in-depth study analyzing the challenges posed by traditional deep learning and LVLM-based geolocation methods. Our findings reveal that LVLMs can accurately determine geolocations from images, even without explicit geographic training. To address these challenges, we introduce tool{}, an innovative framework that significantly enhances image-based geolocation accuracy. tool{} employs a systematic chain-of-thought (CoT) approach, mimicking human geoguessing strategies by carefully analyzing visual and contextual cues such as vehicle types, architectural styles, natural landscapes, and cultural elements. Extensive testing on a dataset of 50,000 ground-truth data points shows that tool{} outperforms both traditional models and human benchmarks in accuracy. It achieves an impressive average score of 4550.5 in the GeoGuessr game, with an 85.37% win rate, and delivers highly precise geolocation predictions, with the closest distances as accurate as 0.3 km. Furthermore, our study highlights issues related to dataset integrity, leading to the creation of a more robust dataset and a refined framework that leverages LVLMs' cognitive capabilities to improve geolocation precision. These findings underscore tool{}'s superior ability to interpret complex visual data, the urgent need to address emerging security vulnerabilities posed by LVLMs, and the importance of responsible AI development to ensure user privacy protection.
Read more8/20/2024
0
GeoReasoner: Geo-localization with Reasoning in Street Views using a Large Vision-Language Model
Ling Li, Yu Ye, Bingchuan Jiang, Wei Zeng
This work tackles the problem of geo-localization with a new paradigm using a large vision-language model (LVLM) augmented with human inference knowledge. A primary challenge here is the scarcity of data for training the LVLM - existing street-view datasets often contain numerous low-quality images lacking visual clues, and lack any reasoning inference. To address the data-quality issue, we devise a CLIP-based network to quantify the degree of street-view images being locatable, leading to the creation of a new dataset comprising highly locatable street views. To enhance reasoning inference, we integrate external knowledge obtained from real geo-localization games, tapping into valuable human inference capabilities. The data are utilized to train GeoReasoner, which undergoes fine-tuning through dedicated reasoning and location-tuning stages. Qualitative and quantitative evaluations illustrate that GeoReasoner outperforms counterpart LVLMs by more than 25% at country-level and 38% at city-level geo-localization tasks, and surpasses StreetCLIP performance while requiring fewer training resources. The data and code are available at https://github.com/lingli1996/GeoReasoner.
Read more6/28/2024
0
Towards Vision-Language Geo-Foundation Model: A Survey
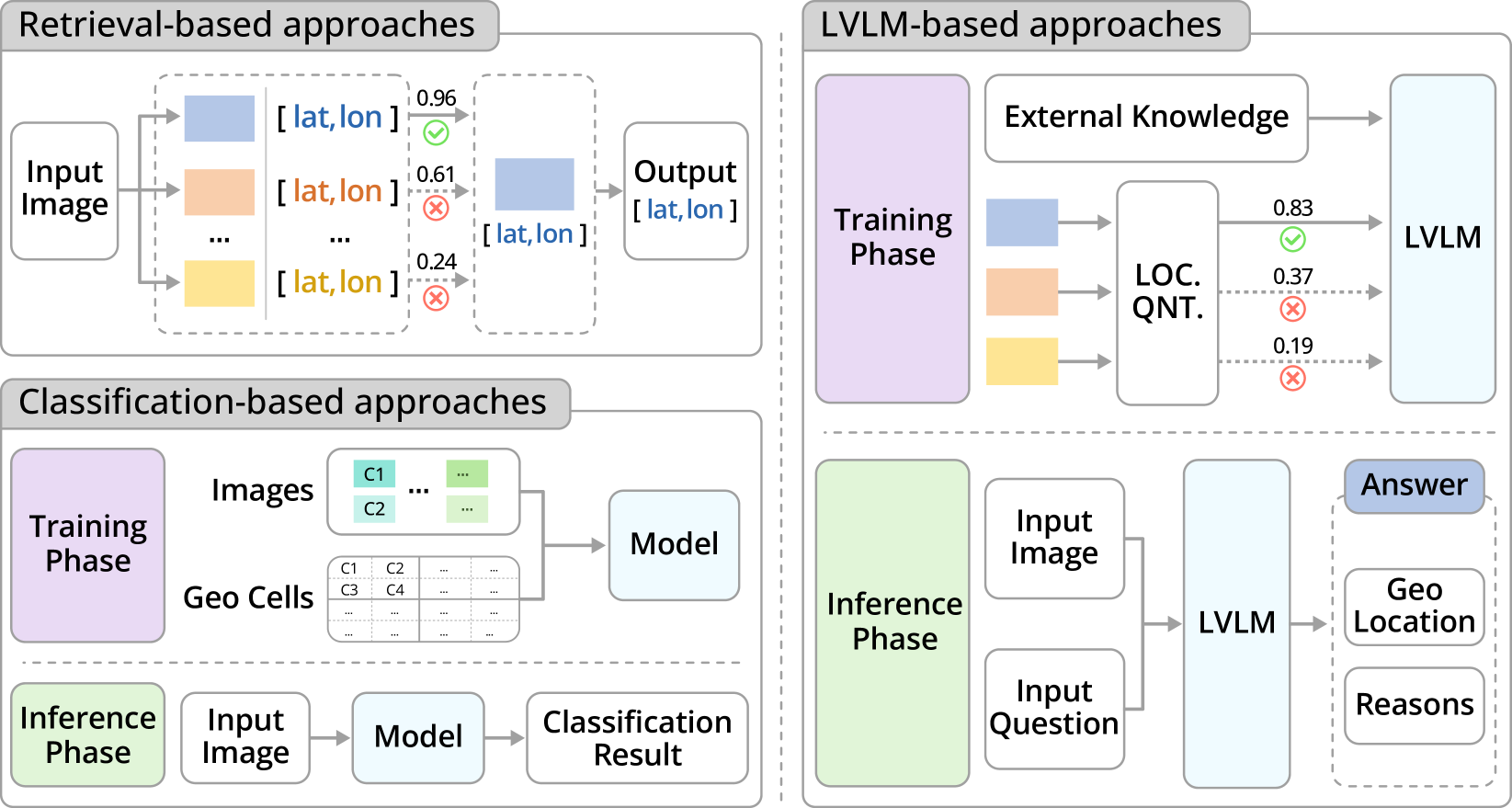
Yue Zhou, Litong Feng, Yiping Ke, Xue Jiang, Junchi Yan, Xue Yang, Wayne Zhang
Vision-Language Foundation Models (VLFMs) have made remarkable progress on various multimodal tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding. However, most methods rely on training with general image datasets, and the lack of geospatial data leads to poor performance on earth observation. Numerous geospatial image-text pair datasets and VLFMs fine-tuned on them have been proposed recently. These new approaches aim to leverage large-scale, multimodal geospatial data to build versatile intelligent models with diverse geo-perceptive capabilities, which we refer to as Vision-Language Geo-Foundation Models (VLGFMs). This paper thoroughly reviews VLGFMs, summarizing and analyzing recent developments in the field. In particular, we introduce the background and motivation behind the rise of VLGFMs, highlighting their unique research significance. Then, we systematically summarize the core technologies employed in VLGFMs, including data construction, model architectures, and applications of various multimodal geospatial tasks. Finally, we conclude with insights, issues, and discussions regarding future research directions. To the best of our knowledge, this is the first comprehensive literature review of VLGFMs. We keep tracing related works at https://github.com/zytx121/Awesome-VLGFM.
Read more6/14/2024