Towards Vision-Language Geo-Foundation Model: A Survey

0
Sign in to get full access
Overview
- This paper provides a comprehensive survey of the emerging field of vision-language geo-foundation models, which aim to develop large-scale models that can understand and reason about both visual and textual data in the context of geospatial applications.
- The paper covers the background, key developments, and critical analysis of this rapidly evolving research area, offering insights into the potential of these models to transform various domains, including remote sensing, urban planning, and disaster response.
Plain English Explanation
Vision-language geo-foundation models are a new type of AI system that can understand and work with both visual data (like images and videos) and language data (like text). These models are being developed to tackle a wide range of problems in fields that deal with geographic or location-based information, such as remote sensing, urban planning, and disaster response.
The key idea behind these models is to create a powerful "foundation" that can be used for many different tasks, similar to how language models have become a foundation for various natural language processing applications. By training these models on a vast amount of visual and textual data related to geographic locations, they can learn to understand and reason about the world in a way that combines both visual and linguistic information.
For example, a vision-language geo-foundation model could be used to analyze satellite images of a disaster-affected area and automatically generate detailed reports describing the damage, identify areas that need immediate attention, and suggest response strategies based on the available information. This could greatly improve the efficiency and effectiveness of disaster relief efforts.
Technical Explanation
The paper begins by providing background on the recent advancements in vision-language models and multi-modal foundation models, which have demonstrated the potential to understand and reason about both visual and textual data. The authors then introduce the concept of vision-language geo-foundation models, which aim to extend these capabilities to the geospatial domain.
The paper discusses key research directions and developments in this emerging field, including:
- Architectures: The use of transformer-based models, such as ViL-T and VLN-BERT, to enable effective fusion of visual and textual information.
- Datasets: The creation of large-scale, diverse datasets that combine geospatial data (e.g., satellite imagery, maps) with associated textual descriptions and annotations.
- Multi-Task Learning: Approaches that leverage multi-task learning to enable these models to perform a wide range of geospatial tasks, from land cover classification to disaster response.
The paper also provides a critical analysis of the current state of the field, discussing challenges such as the need for better cross-modal reasoning, the integration of domain-specific knowledge, and the ethical considerations surrounding the deployment of these models in real-world applications.
Critical Analysis
The paper highlights several important caveats and limitations of the current research on vision-language geo-foundation models. One key challenge is the need for better cross-modal reasoning capabilities, as these models still struggle to fully integrate and reason about the complex relationships between visual and textual data in the geospatial context.
Additionally, the authors note the importance of incorporating domain-specific knowledge, such as geographic information systems (GIS) data and expert knowledge, to enhance the models' understanding and decision-making capabilities. Without this integration, these models may have difficulty generalizing to real-world geospatial problems.
The paper also raises ethical concerns, such as the potential for biases and privacy issues when deploying these models in sensitive domains like urban planning and disaster response. The authors emphasize the need for careful consideration of these issues to ensure the responsible development and use of vision-language geo-foundation models.
Overall, the paper provides a comprehensive and insightful analysis of this emerging field, highlighting both the significant potential and the critical challenges that researchers and practitioners will need to address to realize the full benefits of these powerful AI systems.
Conclusion
This survey paper on vision-language geo-foundation models presents a timely and important overview of a rapidly evolving research area. By combining the strengths of vision-language models and multi-modal foundation models with a focus on geospatial applications, these systems have the potential to transform a wide range of domains, from remote sensing and urban planning to disaster response and environmental monitoring.
The key takeaways from this paper include the need for continued advancements in cross-modal reasoning, the integration of domain-specific knowledge, and the careful consideration of ethical implications. As the field continues to progress, the development of robust and responsible vision-language geo-foundation models will be crucial for unlocking new possibilities and addressing some of the most pressing challenges facing our world today.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Vision-Language Geo-Foundation Model: A Survey
Yue Zhou, Litong Feng, Yiping Ke, Xue Jiang, Junchi Yan, Xue Yang, Wayne Zhang
Vision-Language Foundation Models (VLFMs) have made remarkable progress on various multimodal tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding. However, most methods rely on training with general image datasets, and the lack of geospatial data leads to poor performance on earth observation. Numerous geospatial image-text pair datasets and VLFMs fine-tuned on them have been proposed recently. These new approaches aim to leverage large-scale, multimodal geospatial data to build versatile intelligent models with diverse geo-perceptive capabilities, which we refer to as Vision-Language Geo-Foundation Models (VLGFMs). This paper thoroughly reviews VLGFMs, summarizing and analyzing recent developments in the field. In particular, we introduce the background and motivation behind the rise of VLGFMs, highlighting their unique research significance. Then, we systematically summarize the core technologies employed in VLGFMs, including data construction, model architectures, and applications of various multimodal geospatial tasks. Finally, we conclude with insights, issues, and discussions regarding future research directions. To the best of our knowledge, this is the first comprehensive literature review of VLGFMs. We keep tracing related works at https://github.com/zytx121/Awesome-VLGFM.
Read more6/14/2024
📈
0
Swarm Intelligence in Geo-Localization: A Multi-Agent Large Vision-Language Model Collaborative Framework
Xiao Han, Chen Zhu, Xiangyu Zhao, Hengshu Zhu
Visual geo-localization demands in-depth knowledge and advanced reasoning skills to associate images with real-world geographic locations precisely. In general, traditional methods based on data-matching are hindered by the impracticality of storing adequate visual records of global landmarks. Recently, Large Vision-Language Models (LVLMs) have demonstrated the capability of geo-localization through Visual Question Answering (VQA), enabling a solution that does not require external geo-tagged image records. However, the performance of a single LVLM is still limited by its intrinsic knowledge and reasoning capabilities. Along this line, in this paper, we introduce a novel visual geo-localization framework called name that integrates the inherent knowledge of multiple LVLM agents via inter-agent communication to achieve effective geo-localization of images. Furthermore, our framework employs a dynamic learning strategy to optimize the communication patterns among agents, reducing unnecessary discussions among agents and improving the efficiency of the framework. To validate the effectiveness of the proposed framework, we construct GeoGlobe, a novel dataset for visual geo-localization tasks. Extensive testing on the dataset demonstrates that our approach significantly outperforms state-of-the-art methods.
Read more8/22/2024

0
Examining the Commitments and Difficulties Inherent in Multimodal Foundation Models for Street View Imagery
Zhenyuan Yang, Xuhui Lin, Qinyi He, Ziye Huang, Zhengliang Liu, Hanqi Jiang, Peng Shu, Zihao Wu, Yiwei Li, Stephen Law, Gengchen Mai, Tianming Liu, Tao Yang
The emergence of Large Language Models (LLMs) and multimodal foundation models (FMs) has generated heightened interest in their applications that integrate vision and language. This paper investigates the capabilities of ChatGPT-4V and Gemini Pro for Street View Imagery, Built Environment, and Interior by evaluating their performance across various tasks. The assessments include street furniture identification, pedestrian and car counts, and road width measurement in Street View Imagery; building function classification, building age analysis, building height analysis, and building structure classification in the Built Environment; and interior room classification, interior design style analysis, interior furniture counts, and interior length measurement in Interior. The results reveal proficiency in length measurement, style analysis, question answering, and basic image understanding, but highlight limitations in detailed recognition and counting tasks. While zero-shot learning shows potential, performance varies depending on the problem domains and image complexities. This study provides new insights into the strengths and weaknesses of multimodal foundation models for practical challenges in Street View Imagery, Built Environment, and Interior. Overall, the findings demonstrate foundational multimodal intelligence, emphasizing the potential of FMs to drive forward interdisciplinary applications at the intersection of computer vision and language.
Read more8/26/2024
0
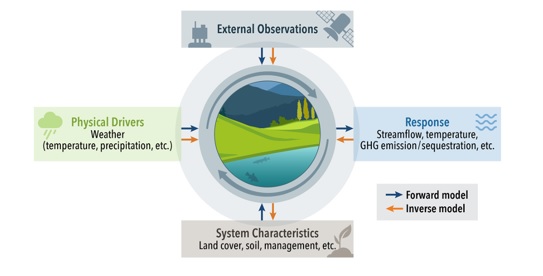
Towards a Knowledge guided Multimodal Foundation Model for Spatio-Temporal Remote Sensing Applications
Praveen Ravirathinam, Ankush Khandelwal, Rahul Ghosh, Vipin Kumar
In recent years, there is increased interest in foundation models for geoscience due to vast amount of earth observing satellite imagery. Existing remote sensing foundation models make use of the various sources of spectral imagery to create large models pretrained on masked reconstruction task. The embeddings from these foundation models are then used for various downstream remote sensing applications. In this paper we propose a foundational modeling framework for remote sensing geoscience applications, that goes beyond these traditional single modality masked autoencoder family of foundation models. This framework leverages the knowledge guided principles that the spectral imagery captures the impact of the physical drivers on the environmental system, and that the relationship between them is governed by the characteristics of the system. Specifically, our method, called MultiModal Variable Step Forecasting (MM-VSF), uses mutlimodal data (spectral imagery and weather) as its input and a variable step forecasting task as its pretraining objective. In our evaluation we show forecasting of satellite imagery using weather can be used as an effective pretraining task for foundation models. We further show the effectiveness of the embeddings from MM-VSF on the downstream task of pixel wise crop mapping, when compared with a model trained in the traditional setting of single modality input and masked reconstruction based pretraining.
Read more7/30/2024