SWE-bench-java: A GitHub Issue Resolving Benchmark for Java

0

Sign in to get full access
Overview
- SWE-bench-java is a GitHub issue resolving benchmark for Java projects.
- It provides a dataset of real-world GitHub issues to evaluate the performance of language models in resolving Java-related issues.
- The benchmark aims to advance research in automating software engineering tasks using artificial intelligence.
Plain English Explanation
SWE-bench-java is a new benchmark that allows researchers to test how well AI language models can solve real software engineering problems. The key idea is to take a large number of actual issues reported on GitHub for Java projects, and see how accurately AI models can understand and resolve those issues.
This is an important task because manually fixing software issues is a major part of a developer's job. If AI could automate this process, it could save a lot of time and money. The SWE-bench-java benchmark provides a standardized way to measure the progress of AI in this area and identify areas for improvement.
By testing AI models on a diverse set of real-world issues, the benchmark can give a realistic assessment of the current state of the technology. This can help guide future research and development efforts to make AI-powered software engineering tools more reliable and effective.
Technical Explanation
The SWE-bench-java benchmark consists of a dataset of over 16,000 GitHub issues from 100 popular Java projects. Each issue includes the original text description, associated code, and the eventual resolution provided by human developers.
Researchers can use this dataset to train and evaluate AI models on the task of understanding the issue descriptions and proposing appropriate solutions. The benchmark defines various performance metrics, such as the ability to correctly classify the issue type, identify relevant code changes, and generate a high-quality fix recommendation.
By testing on this diverse set of real-world issues, the benchmark aims to provide a more realistic and comprehensive assessment of an AI system's software engineering capabilities compared to prior, more limited datasets. The insights gained can inform the design of more effective AI-powered tools to assist human developers in their work.
Critical Analysis
The SWE-bench-java benchmark represents an important step forward in benchmarking AI systems for software engineering tasks. By using real-world GitHub data, it avoids the potential pitfalls of synthetic or curated datasets that may not fully capture the complexity and diversity of real-world software issues.
However, the authors acknowledge that the benchmark has some limitations. For example, the issues in the dataset may not be representative of all types of software engineering problems, and the quality of the human-provided resolutions is not guaranteed. Additionally, the benchmark focuses solely on Java projects, so its applicability to other programming languages is unclear.
Further research is needed to explore the generalizability of the benchmark's findings and to investigate the factors that influence an AI system's performance on software engineering tasks. Addressing these limitations could help to make the SWE-bench-java benchmark an even more valuable tool for advancing the state of the art in AI-powered software engineering.
Conclusion
The SWE-bench-java benchmark represents a significant contribution to the field of AI-powered software engineering. By providing a standardized dataset and evaluation framework, it enables researchers to rigorously assess the capabilities of AI systems in understanding and resolving real-world software issues.
The insights gained from this benchmark can inform the development of more effective AI-powered tools to assist human developers, ultimately leading to faster, more efficient, and higher-quality software development. As the field of AI continues to advance, benchmarks like SWE-bench-java will play a crucial role in driving progress and ensuring that AI systems are truly capable of tackling the complex challenges of software engineering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Daoguang Zan, Zhirong Huang, Ailun Yu, Shaoxin Lin, Yifan Shi, Wei Liu, Dong Chen, Zongshuai Qi, Hao Yu, Lei Yu, Dezhi Ran, Muhan Zeng, Bo Shen, Pan Bian, Guangtai Liang, Bei Guan, Pengjie Huang, Tao Xie, Yongji Wang, Qianxiang Wang
GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
Read more8/27/2024
💬
1
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, Karthik Narasimhan
Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We find real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. To this end, we introduce SWE-bench, an evaluation framework consisting of $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. The best-performing model, Claude 2, is able to solve a mere $1.96$% of the issues. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
Read more4/9/2024

0
CodeR: Issue Resolving with Multi-Agent and Task Graphs
Dong Chen, Shaoxin Lin, Muhan Zeng, Daoguang Zan, Jian-Gang Wang, Anton Cheshkov, Jun Sun, Hao Yu, Guoliang Dong, Artem Aliev, Jie Wang, Xiao Cheng, Guangtai Liang, Yuchi Ma, Pan Bian, Tao Xie, Qianxiang Wang
GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.33% of issues, when submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.
Read more6/12/2024
0
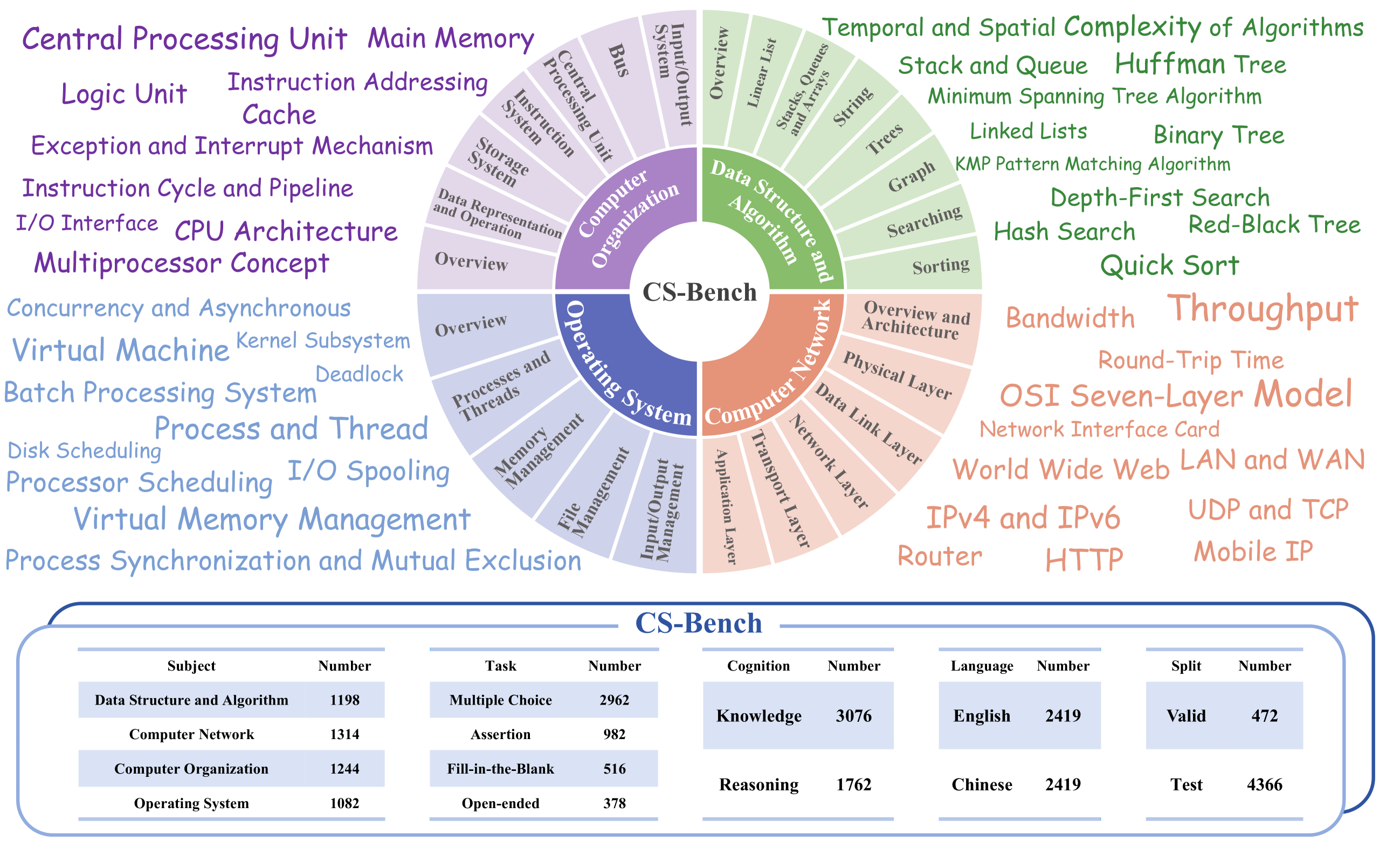
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024