SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
2310.06770
2
0
💬
Abstract
Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We find real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. To this end, we introduce SWE-bench, an evaluation framework consisting of $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. The best-performing model, Claude 2, is able to solve a mere $1.96$% of the issues. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers find real-world software engineering tasks to be a useful testbed for evaluating the capabilities of large language models (LLMs)
- They introduce SWE-bench, an evaluation framework with 2,294 software engineering problems from GitHub issues and pull requests across 12 Python repositories
- The goal is for LLMs to edit code to resolve the issues, which requires understanding and coordinating changes across multiple functions, classes, and files
- Evaluations show that even state-of-the-art models can only resolve the simplest issues, with the best-performing model solving just 1.96% of the problems
Plain English Explanation
As language models like GPT-3 have become increasingly capable, it's become harder to effectively evaluate their full range of abilities. Researchers believe that real-world software engineering tasks could provide a rich, challenging testbed for assessing the next generation of these models.
To explore this, the researchers created SWE-bench, a collection of over 2,000 software engineering problems drawn from actual GitHub issues and pull requests. These issues often require coordinating changes across multiple parts of the codebase, understanding the execution environment, and performing complex reasoning - going well beyond typical code generation.
The researchers then tested both state-of-the-art commercial models and a fine-tuned model called SWE-Llama on these software engineering challenges. The results were sobering - even the best-performing model could only solve about 2% of the problems. This shows that current language models still have significant limitations when it comes to practical, real-world tasks that involve in-depth reasoning and interaction with complex software systems.
Improving performance on benchmarks like SWE-bench would be an important step towards developing language models that are more practical, intelligent, and autonomous. The insights from this research could help guide the development of the next generation of AI that can truly assist with software engineering and other demanding, real-world applications.
Technical Explanation
The researchers introduce SWE-bench, an evaluation framework consisting of 2,294 software engineering problems drawn from real GitHub issues and pull requests across 12 popular Python repositories. Given a codebase and a description of an issue to be resolved, language models are tasked with editing the codebase to address the problem.
Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts, and perform complex reasoning that goes far beyond traditional code generation tasks.
The researchers evaluated both state-of-the-art proprietary models and their own fine-tuned model, SWE-Llama, on the SWE-bench challenges. Their results showed that even the best-performing model, Claude 2, could only solve a mere 1.96% of the issues.
These findings highlight the significant limitations of current language models when it comes to practical, real-world tasks that involve in-depth reasoning and interaction with complex software systems. Improving performance on benchmarks like SWE-bench and S3-Eval would be an important step towards developing more practical, intelligent, and autonomous language models that can assist with software engineering and other demanding, real-world applications.
Critical Analysis
The researchers acknowledge several limitations of their study. First, the SWE-bench dataset may not fully capture the breadth of software engineering challenges that language models would face in the real world. The problems were drawn from a limited set of 12 Python repositories, and there may be important types of issues or codebases that are not represented.
Additionally, the researchers only evaluated models on their ability to edit code, rather than other important software engineering skills like understanding requirements, designing architecture, or debugging complex systems. A more comprehensive evaluation framework would be needed to fully assess the capabilities of language models in this domain.
It's also worth noting that the state-of-the-art models tested, while impressive in many ways, are not necessarily representative of the full potential of large language models. As the field continues to advance, more capable and specialized models may emerge that are better suited for software engineering tasks.
Nevertheless, the findings of this study are a sobering reminder that current language models still have significant limitations when it comes to practical, real-world applications. Continued research and benchmarking in this area will be crucial for driving progress towards more intelligent and autonomous AI systems that can truly assist with software development and other complex, knowledge-intensive domains.
Conclusion
This research introduces SWE-bench, a new evaluation framework for assessing the capabilities of large language models on real-world software engineering tasks. The results show that even state-of-the-art models struggle to resolve the majority of the issues, highlighting the significant limitations of current language technology when it comes to practical, intelligent interaction with complex software systems.
While more work is needed to fully capture the breadth of software engineering challenges, the insights from this study represent an important step towards developing the next generation of language models that are more practical, autonomous, and capable of assisting with demanding, real-world applications. Continued research and benchmarking in this area will be crucial for driving progress in this direction.
Related Papers
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024
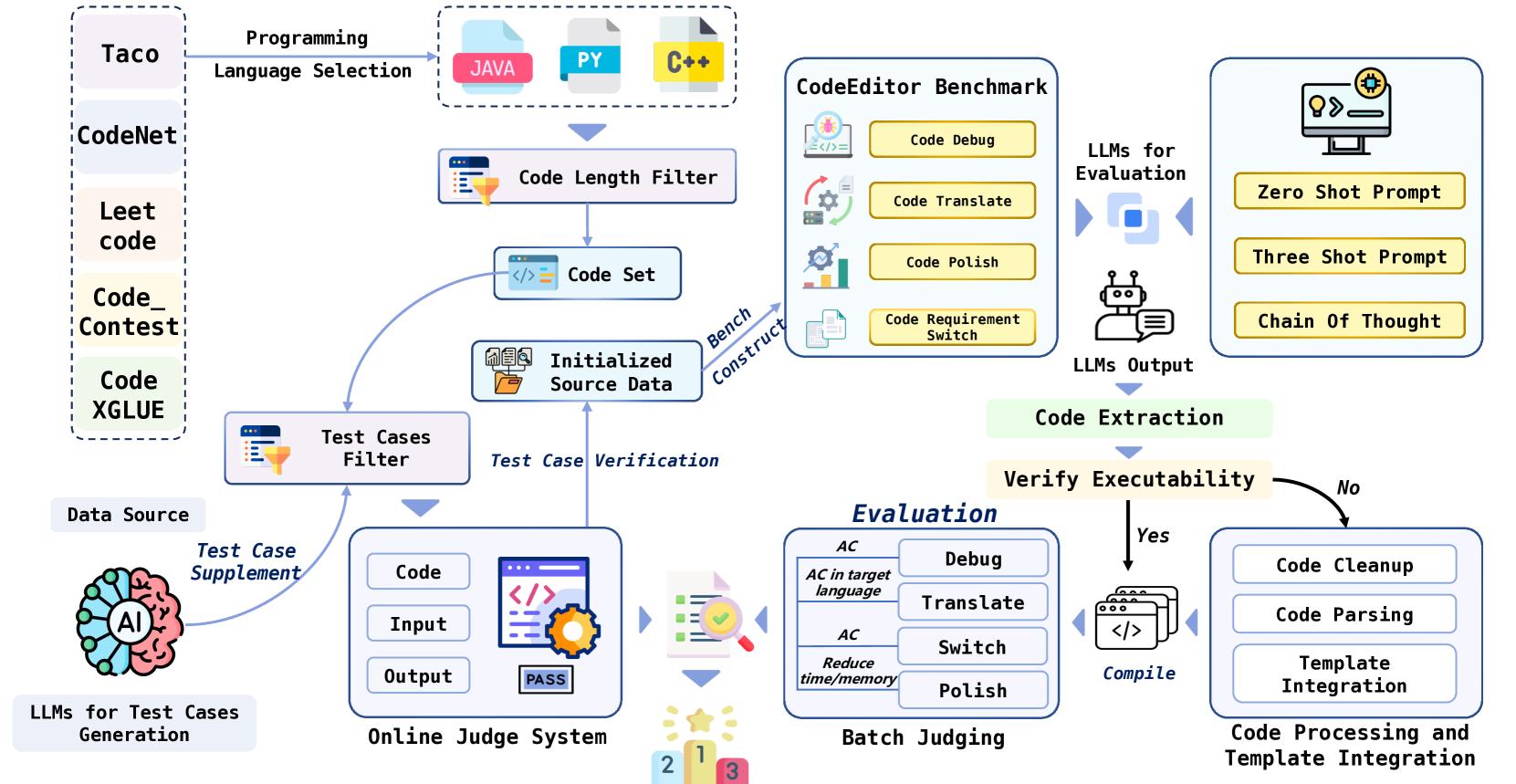
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
💬
Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code
Ziyin Zhang, Chaoyu Chen, Bingchang Liu, Cong Liao, Zi Gong, Hang Yu, Jianguo Li, Rui Wang
0
0
In this work we systematically review the recent advancements in code processing with language models, covering 50+ models, 30+ evaluation tasks, 170+ datasets, and 800 related works. We break down code processing models into general language models represented by the GPT family and specialized models that are specifically pretrained on code, often with tailored objectives. We discuss the relations and differences between these models, and highlight the historical transition of code modeling from statistical models and RNNs to pretrained Transformers and LLMs, which is exactly the same course that had been taken by NLP. We also discuss code-specific features such as AST, CFG, and unit tests, along with their application in training code language models, and identify key challenges and potential future directions in this domain. We keep the survey open and updated on GitHub at https://github.com/codefuse-ai/Awesome-Code-LLM.
4/17/2024

AutoCodeRover: Autonomous Program Improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, Abhik Roychoudhury
0
0
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
4/16/2024