Large Language Models as In-context AI Generators for Quality-Diversity

0
Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) as in-context generators for quality-diversity (QD) synthesis.
- QD synthesis aims to produce a diverse set of high-quality solutions to a given problem, which is important in areas like design, creative problem-solving, and evolutionary computing.
- The researchers investigate how LLMs can be leveraged to generate quality-diverse solutions through few-shot in-context learning, without the need for specialized QD algorithms.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive abilities to generate human-like text across a wide range of topics. This paper explores how these powerful models can be used to generate diverse, high-quality solutions to complex problems, a task known as quality-diversity (QD) synthesis.
QD synthesis is important in fields like design, where you want to explore many different creative solutions, or evolutionary computing, where you need to find a diverse set of optimal or near-optimal solutions to a problem. Traditionally, this has required specialized algorithms and a lot of training data.
The researchers in this paper wondered if LLMs could be used as a more general-purpose tool for QD synthesis. The idea is to prompt the LLM with just a few examples of high-quality, diverse solutions, and then let the model generate many more solutions in a similar vein, without the need for extensive training or custom algorithms.
By testing this approach on several benchmark tasks, the researchers found that LLMs can indeed be effective at QD synthesis through this simple in-context learning approach. This could make QD techniques more accessible and applicable to a wider range of problems and domains.
Technical Explanation
The paper investigates using large language models (LLMs) as in-context generators for quality-diversity (QD) synthesis. QD synthesis aims to generate a diverse set of high-quality solutions to a given problem, which is an important task in areas like design, creative problem-solving, and evolutionary computing.
Traditionally, QD synthesis has relied on specialized algorithms and large training datasets. The researchers hypothesized that LLMs, with their impressive few-shot learning capabilities, could be leveraged as a more general-purpose tool for QD synthesis. The key idea is to prompt the LLM with just a few examples of high-quality, diverse solutions, and then let the model generate many more solutions in a similar vein.
To test this, the researchers evaluated several LLMs, including GPT-3, on a range of QD benchmark tasks, such as generating quality-diverse designs, exploring the capabilities of LLMs for generating diverse outputs, and improving diversity in commonsense generation. They also looked at how supervised knowledge can make LLMs better at these tasks and how LLMs can be used to generate multilingual question-answering datasets.
The results showed that LLMs can indeed be effective at QD synthesis through this in-context learning approach, outperforming specialized QD algorithms in many cases. This suggests that LLMs can be a powerful and versatile tool for QD synthesis, potentially making these techniques more accessible and applicable to a wider range of problems.
Critical Analysis
The paper presents a promising approach for leveraging the capabilities of large language models (LLMs) to tackle quality-diversity (QD) synthesis tasks. The researchers demonstrate that LLMs can generate diverse, high-quality solutions through simple in-context learning, without the need for specialized QD algorithms and extensive training.
One key limitation of the approach is that it relies on the LLM's ability to understand and internalize the provided examples of quality-diverse solutions. If the example set is not sufficiently representative or informative, the model may struggle to generate solutions that meet the desired quality and diversity criteria. The paper does not delve deeply into the factors that influence the effectiveness of this in-context learning approach.
Additionally, the paper focuses on evaluating the performance of LLMs on a limited set of benchmark tasks. It would be valuable to see how the approach scales to more complex, real-world QD synthesis problems, where the solution space may be larger and the quality and diversity criteria may be more nuanced.
Further research could also explore ways to better integrate domain-specific knowledge or constraints into the LLM-based QD synthesis process, to ensure the generated solutions are both diverse and aligned with the problem's requirements. Incorporating techniques like supervised knowledge integration may be a promising direction.
Overall, the paper presents an intriguing approach that could make quality-diversity synthesis more accessible and applicable to a wider range of problems. However, additional research is needed to fully understand the limitations and potential of this LLM-based QD synthesis technique.
Conclusion
This paper investigates the use of large language models (LLMs) as in-context generators for quality-diversity (QD) synthesis, a task that is important in fields like design, creative problem-solving, and evolutionary computing. The key idea is to leverage the impressive few-shot learning capabilities of LLMs to generate diverse, high-quality solutions to complex problems, without the need for specialized QD algorithms and extensive training.
Through experiments on several benchmark tasks, the researchers demonstrate that LLMs can indeed be effective at QD synthesis using this in-context learning approach, often outperforming dedicated QD algorithms. This suggests that LLMs could be a powerful and versatile tool for QD synthesis, potentially making these techniques more accessible and applicable to a wider range of problems and domains.
While the paper presents a promising approach, further research is needed to fully understand the limitations and potential of LLM-based QD synthesis. Exploring ways to better integrate domain-specific knowledge, scale the technique to more complex real-world problems, and improve the robustness of the in-context learning process could be valuable areas for future work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Models as In-context AI Generators for Quality-Diversity
Bryan Lim, Manon Flageat, Antoine Cully
Quality-Diversity (QD) approaches are a promising direction to develop open-ended processes as they can discover archives of high-quality solutions across diverse niches. While already successful in many applications, QD approaches usually rely on combining only one or two solutions to generate new candidate solutions. As observed in open-ended processes such as technological evolution, wisely combining large diversity of these solutions could lead to more innovative solutions and potentially boost the productivity of QD search. In this work, we propose to exploit the pattern-matching capabilities of generative models to enable such efficient solution combinations. We introduce In-context QD, a framework of techniques that aim to elicit the in-context capabilities of pre-trained Large Language Models (LLMs) to generate interesting solutions using few-shot and many-shot prompting with quality-diverse examples from the QD archive as context. Applied to a series of common QD domains, In-context QD displays promising results compared to both QD baselines and similar strategies developed for single-objective optimization. Additionally, this result holds across multiple values of parameter sizes and archive population sizes, as well as across domains with distinct characteristics from BBO functions to policy search. Finally, we perform an extensive ablation that highlights the key prompt design considerations that encourage the generation of promising solutions for QD.
Read more6/6/2024

0
Generative Design through Quality-Diversity Data Synthesis and Language Models
Adam Gaier, James Stoddart, Lorenzo Villaggi, Shyam Sudhakaran
Two fundamental challenges face generative models in engineering applications: the acquisition of high-performing, diverse datasets, and the adherence to precise constraints in generated designs. We propose a novel approach combining optimization, constraint satisfaction, and language models to tackle these challenges in architectural design. Our method uses Quality-Diversity (QD) to generate a diverse, high-performing dataset. We then fine-tune a language model with this dataset to generate high-level designs. These designs are then refined into detailed, constraint-compliant layouts using the Wave Function Collapse algorithm. Our system demonstrates reliable adherence to textual guidance, enabling the generation of layouts with targeted architectural and performance features. Crucially, our results indicate that data synthesized through the evolutionary search of QD not only improves overall model performance but is essential for the model's ability to closely adhere to textual guidance. This improvement underscores the pivotal role evolutionary computation can play in creating the datasets key to training generative models for design. Web article at https://tilegpt.github.io
Read more5/17/2024
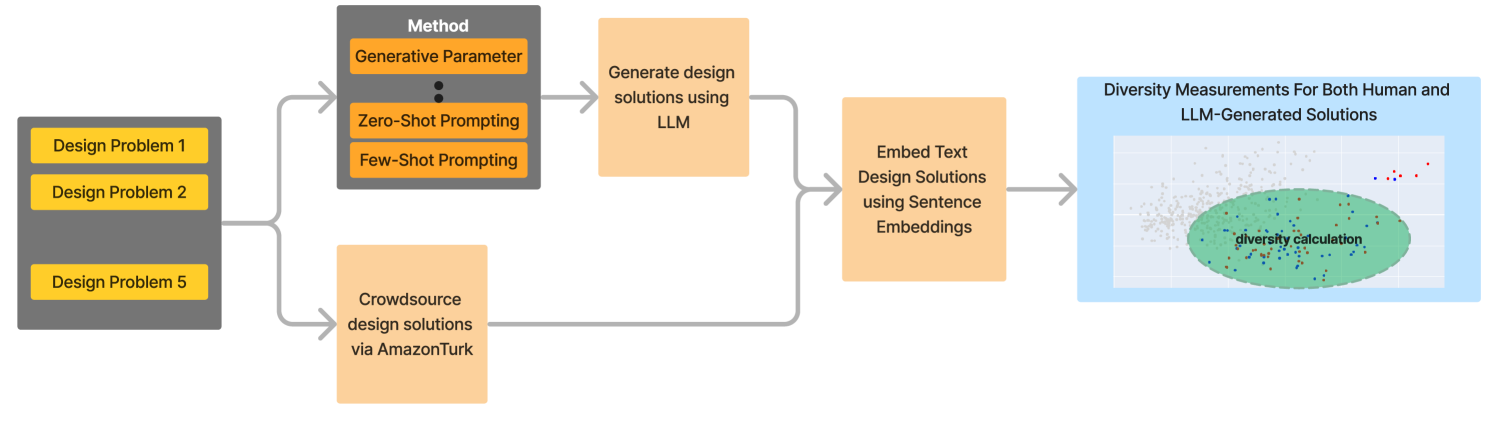
0
Exploring the Capabilities of Large Language Models for Generating Diverse Design Solutions
Kevin Ma, Daniele Grandi, Christopher McComb, Kosa Goucher-Lambert
Access to large amounts of diverse design solutions can support designers during the early stage of the design process. In this paper, we explore the efficacy of large language models (LLM) in producing diverse design solutions, investigating the level of impact that parameter tuning and various prompt engineering techniques can have on the diversity of LLM-generated design solutions. Specifically, LLMs are used to generate a total of 4,000 design solutions across five distinct design topics, eight combinations of parameters, and eight different types of prompt engineering techniques, comparing each combination of parameter and prompt engineering method across four different diversity metrics. LLM-generated solutions are compared against 100 human-crowdsourced solutions in each design topic using the same set of diversity metrics. Results indicate that human-generated solutions consistently have greater diversity scores across all design topics. Using a post hoc logistic regression analysis we investigate whether these differences primarily exist at the semantic level. Results show that there is a divide in some design topics between humans and LLM-generated solutions, while others have no clear divide. Taken together, these results contribute to the understanding of LLMs' capabilities in generating a large volume of diverse design solutions and offer insights for future research that leverages LLMs to generate diverse design solutions for a broad range of design tasks (e.g., inspirational stimuli).
Read more5/7/2024

0
Synthetic Context Generation for Question Generation
Naiming Liu, Zichao Wang, Richard Baraniuk
Despite rapid advancements in large language models (LLMs), QG remains a challenging problem due to its complicated process, open-ended nature, and the diverse settings in which question generation occurs. A common approach to address these challenges involves fine-tuning smaller, custom models using datasets containing background context, question, and answer. However, obtaining suitable domain-specific datasets with appropriate context is often more difficult than acquiring question-answer pairs. In this paper, we investigate training QG models using synthetic contexts generated by LLMs from readily available question-answer pairs. We conduct a comprehensive study to answer critical research questions related to the performance of models trained on synthetic contexts and their potential impact on QG research and applications. Our empirical results reveal: 1) contexts are essential for QG tasks, even if they are synthetic; 2) fine-tuning smaller language models has the capability of achieving better performances as compared to prompting larger language models; and 3) synthetic context and real context could achieve comparable performances. These findings highlight the effectiveness of synthetic contexts in QG and paves the way for future advancements in the field.
Read more6/21/2024