Synthetic Data: Revisiting the Privacy-Utility Trade-off

0

Sign in to get full access
Overview
- This paper explores the trade-off between privacy and utility in the generation of synthetic data, which is data that is artificially created to resemble real-world data without revealing sensitive information.
- The authors investigate different techniques for generating synthetic data and evaluate their performance in terms of privacy preservation and the utility of the generated data for downstream tasks.
- They provide insights into how to navigate the privacy-utility trade-off and offer guidance for practitioners on choosing appropriate synthetic data generation methods.
Plain English Explanation
The paper looks at the challenge of creating fake data that is similar to real data, but doesn't reveal private information. Generating this kind of "synthetic data" is useful for things like training machine learning models without using sensitive real-world data.
The researchers tested out different methods for producing synthetic data and measured how well they balanced protecting people's privacy while still making the data useful for analysis and other applications. They found that there are trade-offs - techniques that maximize privacy may reduce the usefulness of the data, while methods focused on utility can sometimes compromise people's confidentiality.
The key takeaway is that there's no one-size-fits-all solution, and practitioners need to carefully consider their priorities and choose the right synthetic data generation approach for their specific needs. The paper provides guidance to help navigate this tricky balance between privacy and usefulness.
Technical Explanation
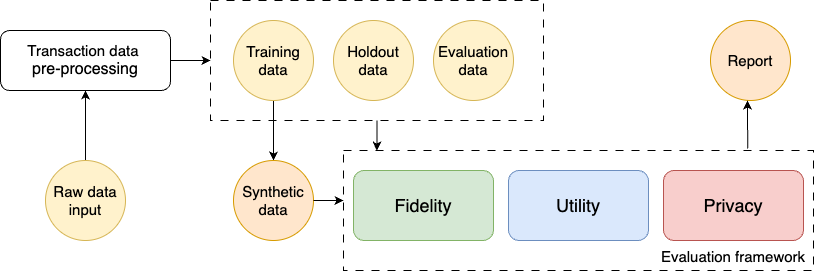
The paper examines the privacy-utility trade-off in the context of synthetic data generation. The authors evaluate different techniques, including differentially private synthetic data generation and controllable trust-based approaches, in terms of their ability to preserve privacy while maintaining the utility of the generated data for downstream tasks.
The experimental design involves generating synthetic versions of real-world datasets and assessing their fidelity to the original data distribution, as well as their performance on specific machine learning tasks. The authors also investigate the impact of outliers and other potential sources of privacy leakage in the synthetic data.
The results provide insights into the trade-offs between privacy and utility for different synthetic data generation methods. The authors discuss the implications of their findings for practitioners and highlight areas for further research, such as the development of more advanced techniques for balancing privacy and utility.
Critical Analysis
The paper presents a thorough investigation of the privacy-utility trade-off in synthetic data generation, and the authors acknowledge several limitations and avenues for future work. One potential area for further research is the impact of specific data characteristics (e.g., dimensionality, sparsity) on the performance of different synthetic data generation techniques.
Additionally, the paper focuses on quantitative metrics for privacy and utility, but does not explore qualitative aspects, such as the interpretability or explainability of the generated data. Incorporating these factors into the evaluation framework could provide a more holistic understanding of the practical implications of synthetic data usage.
Another aspect that could be investigated is the scalability and computational efficiency of the tested methods, as real-world applications may involve large-scale datasets or time-sensitive requirements that could impact the choice of synthetic data generation approach.
Overall, the paper provides a valuable contribution to the field of synthetic data research, but continued exploration of the privacy-utility trade-off, as well as a broader consideration of relevant factors, could further enhance the practical applicability of this technology.
Conclusion
This paper offers a comprehensive examination of the trade-offs between privacy and utility in synthetic data generation. The authors evaluate various techniques and provide insights into navigating this critical balance, which is essential for the effective and responsible use of synthetic data in real-world applications.
The findings highlight the need for careful consideration of the specific requirements and constraints of a given use case when selecting a synthetic data generation method. By understanding the strengths, limitations, and trade-offs of different approaches, practitioners can make informed decisions that optimize the privacy-utility balance and unlock the full potential of synthetic data in their respective domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Synthetic Data: Revisiting the Privacy-Utility Trade-off
Fatima Jahan Sarmin, Atiquer Rahman Sarkar, Yang Wang, Noman Mohammed
Synthetic data has been considered a better privacy-preserving alternative to traditionally sanitized data across various applications. However, a recent article challenges this notion, stating that synthetic data does not provide a better trade-off between privacy and utility than traditional anonymization techniques, and that it leads to unpredictable utility loss and highly unpredictable privacy gain. The article also claims to have identified a breach in the differential privacy guarantees provided by PATEGAN and PrivBayes. When a study claims to refute or invalidate prior findings, it is crucial to verify and validate the study. In our work, we analyzed the implementation of the privacy game described in the article and found that it operated in a highly specialized and constrained environment, which limits the applicability of its findings to general cases. Our exploration also revealed that the game did not satisfy a crucial precondition concerning data distributions, which contributed to the perceived violation of the differential privacy guarantees offered by PATEGAN and PrivBayes. We also conducted a privacy-utility trade-off analysis in a more general and unconstrained environment. Our experimentation demonstrated that synthetic data achieves a more favorable privacy-utility trade-off compared to the provided implementation of k-anonymization, thereby reaffirming earlier conclusions.
Read more7/12/2024
0
Advancing Retail Data Science: Comprehensive Evaluation of Synthetic Data
Yu Xia, Chi-Hua Wang, Joshua Mabry, Guang Cheng
The evaluation of synthetic data generation is crucial, especially in the retail sector where data accuracy is paramount. This paper introduces a comprehensive framework for assessing synthetic retail data, focusing on fidelity, utility, and privacy. Our approach differentiates between continuous and discrete data attributes, providing precise evaluation criteria. Fidelity is measured through stability and generalizability. Stability ensures synthetic data accurately replicates known data distributions, while generalizability confirms its robustness in novel scenarios. Utility is demonstrated through the synthetic data's effectiveness in critical retail tasks such as demand forecasting and dynamic pricing, proving its value in predictive analytics and strategic planning. Privacy is safeguarded using Differential Privacy, ensuring synthetic data maintains a perfect balance between resembling training and holdout datasets without compromising security. Our findings validate that this framework provides reliable and scalable evaluation for synthetic retail data. It ensures high fidelity, utility, and privacy, making it an essential tool for advancing retail data science. This framework meets the evolving needs of the retail industry with precision and confidence, paving the way for future advancements in synthetic data methodologies.
Read more6/21/2024
📊
0
The Real Deal Behind the Artificial Appeal: Inferential Utility of Tabular Synthetic Data
Alexander Decruyenaere, Heidelinde Dehaene, Paloma Rabaey, Christiaan Polet, Johan Decruyenaere, Stijn Vansteelandt, Thomas Demeester
Recent advances in generative models facilitate the creation of synthetic data to be made available for research in privacy-sensitive contexts. However, the analysis of synthetic data raises a unique set of methodological challenges. In this work, we highlight the importance of inferential utility and provide empirical evidence against naive inference from synthetic data, whereby synthetic data are treated as if they were actually observed. Before publishing synthetic data, it is essential to develop statistical inference tools for such data. By means of a simulation study, we show that the rate of false-positive findings (type 1 error) will be unacceptably high, even when the estimates are unbiased. Despite the use of a previously proposed correction factor, this problem persists for deep generative models, in part due to slower convergence of estimators and resulting underestimation of the true standard error. We further demonstrate our findings through a case study.
Read more6/13/2024

0
Differentially Private Synthetic Data with Private Density Estimation
Nikolija Bojkovic, Po-Ling Loh
The need to analyze sensitive data, such as medical records or financial data, has created a critical research challenge in recent years. In this paper, we adopt the framework of differential privacy, and explore mechanisms for generating an entire dataset which accurately captures characteristics of the original data. We build upon the work of Boedihardjo et al, which laid the foundations for a new optimization-based algorithm for generating private synthetic data. Importantly, we adapt their algorithm by replacing a uniform sampling step with a private distribution estimator; this allows us to obtain better computational guarantees for discrete distributions, and develop a novel algorithm suitable for continuous distributions. We also explore applications of our work to several statistical tasks.
Read more5/9/2024