Synthetic dual image generation for reduction of labeling efforts in semantic segmentation of micrographs with a customized metric function

0
🖼️
Sign in to get full access
Overview
- Training semantic segmentation models for material analysis requires micrographs and corresponding masks.
- Perfect masks are difficult to create, especially at object edges, and the available data may be limited.
- These challenges make it problematic to train a robust model.
Plain English Explanation
The paper presents a workflow to improve semantic segmentation models for analyzing micrographs (images of microscopic structures). Semantic segmentation is the process of identifying and categorizing the different elements within an image.
One challenge is that it can be quite difficult to create perfect masks, which are the labeled images that show the boundaries of the different materials or structures. This is especially true at the edges of the objects in the micrographs. Additionally, researchers may only have access to a small number of samples, limiting the available training data.
These issues make it challenging to train a robust and accurate semantic segmentation model. To address this, the researchers demonstrate a workflow that generates synthetic microstructural images and masks. This synthetic data is then used along with the limited real data to train the segmentation model.
The key steps are:
- Gather a few real micrographs and their corresponding masks.
- Use these real samples to train a Vector Quantised-Variational AutoEncoder (VQ-VAE) model. This model learns to encode the real data into a discrete representation.
- Train a PixelCNN generative model on the encoded real data. This allows the system to generate new synthetic codes.
- Decode the synthetic codes using the VQ-VAE to generate new micrograph images and corresponding masks.
- Use the synthetic data, along with the limited real data, to train a U-Net semantic segmentation model.
The researchers show that this approach can reduce the time and effort required for sample preparation, image acquisition, and data labeling, while still achieving good performance on real, non-synthetic test images.
Technical Explanation
The paper introduces a workflow to generate synthetic micrographs and corresponding segmentation masks to improve the training of semantic segmentation models.
The key components are:
- VQ-VAE: This model learns to encode the real micrographs and masks into a discrete latent representation, creating an embedding space that captures the distribution of the input data.
- PixelCNN: This generative model is trained on the encoded real data from the VQ-VAE. It learns the underlying distribution of the discrete codes and can be used to sample new codes.
- Decoding: The sampled codes from the PixelCNN are decoded by the VQ-VAE to generate new synthetic micrographs and masks.
- U-Net: The synthetic data, along with the limited real data, is used to train a U-Net semantic segmentation model. The U-Net is then evaluated on real, non-synthetic test images.
Additionally, the researchers introduce a customized metric derived from the mean Intersection over Union (mIoU) to evaluate the segmentation performance. This metric is designed to be less sensitive to a few falsely predicted pixels, which can greatly reduce the mIoU value.
Critical Analysis
The paper addresses an important challenge in training semantic segmentation models for material analysis, where the availability of high-quality labeled data can be limited. The proposed workflow for generating synthetic data is a clever solution to augment the real data and improve the model's performance.
One potential limitation is the reliance on the VQ-VAE and PixelCNN models, which may introduce their own biases and limitations into the synthetic data. The researchers do not extensively explore the quality and fidelity of the generated synthetic data compared to the real data.
Additionally, the paper does not provide a detailed analysis of the generalization capabilities of the trained U-Net model. It would be interesting to see how the model performs on a wider range of micrograph samples, including those from different materials or with different characteristics.
Finally, the researchers could have explored the potential for active learning or other semi-supervised techniques to further reduce the need for extensive manual labeling of the real data.
Conclusion
This paper presents a practical workflow for improving semantic segmentation models for material analysis by generating synthetic micrographs and masks. The approach can help reduce the time and effort required for sample preparation, data acquisition, and labeling, while still achieving good performance on real test data.
The techniques demonstrated in this paper could be generalized to other types of image data, making it a potentially useful solution for training models when only a small amount of real, labeled data is available.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Synthetic dual image generation for reduction of labeling efforts in semantic segmentation of micrographs with a customized metric function
Matias Oscar Volman Stern, Dominic Hohs, Andreas Jansche, Timo Bernthaler, Gerhard Schneider
Training of semantic segmentation models for material analysis requires micrographs and their corresponding masks. It is quite unlikely that perfect masks will be drawn, especially at the edges of objects, and sometimes the amount of data that can be obtained is small, since only a few samples are available. These aspects make it very problematic to train a robust model. We demonstrate a workflow for the improvement of semantic segmentation models of micrographs through the generation of synthetic microstructural images in conjunction with masks. The workflow only requires joining a few micrographs with their respective masks to create the input for a Vector Quantised-Variational AutoEncoder model that includes an embedding space, which is trained such that a generative model (PixelCNN) learns the distribution of each input, transformed into discrete codes, and can be used to sample new codes. The latter will eventually be decoded by VQ-VAE to generate images alongside corresponding masks for semantic segmentation. To evaluate the synthetic data, we have trained U-Net models with different amounts of these synthetic data in conjunction with real data. These models were then evaluated using non-synthetic images only. Additionally, we introduce a customized metric derived from the mean Intersection over Union (mIoU). The proposed metric prevents a few falsely predicted pixels from greatly reducing the value of the mIoU. We have achieved a reduction in sample preparation and acquisition times, as well as the efforts, needed for image processing and labeling tasks, are less when it comes to training semantic segmentation model. The approach could be generalized to various types of image data such that it serves as a user-friendly solution for training models with a small number of real images.
Read more8/2/2024
🏋️
0
Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
Ryota Yoshihashi, Yuya Otsuka, Kenji Doi, Tomohiro Tanaka, Hirokatsu Kataoka
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
Read more4/16/2024

0
Semi-Supervised Segmentation via Embedding Matching
Weiyi Xie, Nathalie Willems, Nikolas Lessmann, Tom Gibbons, Daniele De Massari
Deep convolutional neural networks are widely used in medical image segmentation but require many labeled images for training. Annotating three-dimensional medical images is a time-consuming and costly process. To overcome this limitation, we propose a novel semi-supervised segmentation method that leverages mostly unlabeled images and a small set of labeled images in training. Our approach involves assessing prediction uncertainty to identify reliable predictions on unlabeled voxels from the teacher model. These voxels serve as pseudo-labels for training the student model. In voxels where the teacher model produces unreliable predictions, pseudo-labeling is carried out based on voxel-wise embedding correspondence using reference voxels from labeled images. We applied this method to automate hip bone segmentation in CT images, achieving notable results with just 4 CT scans. The proposed approach yielded a Hausdorff distance with 95th percentile (HD95) of 3.30 and IoU of 0.929, surpassing existing methods achieving HD95 (4.07) and IoU (0.927) at their best.
Read more7/8/2024
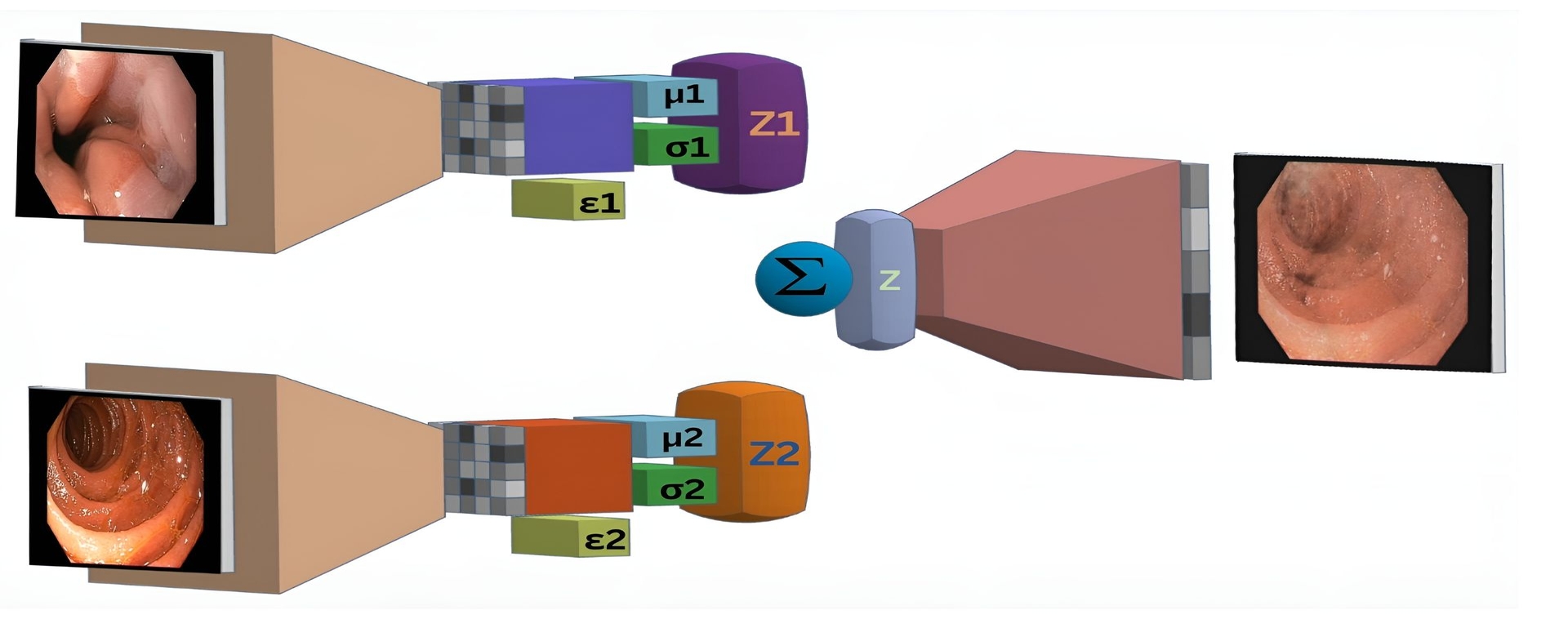
0
New!Enhancing Image Classification in Small and Unbalanced Datasets through Synthetic Data Augmentation
Neil De La Fuente, Mireia Maj'o, Irina Luzko, Henry C'ordova, Gloria Fern'andez-Esparrach, Jorge Bernal
Accurate and robust medical image classification is a challenging task, especially in application domains where available annotated datasets are small and present high imbalance between target classes. Considering that data acquisition is not always feasible, especially for underrepresented classes, our approach introduces a novel synthetic augmentation strategy using class-specific Variational Autoencoders (VAEs) and latent space interpolation to improve discrimination capabilities. By generating realistic, varied synthetic data that fills feature space gaps, we address issues of data scarcity and class imbalance. The method presented in this paper relies on the interpolation of latent representations within each class, thus enriching the training set and improving the model's generalizability and diagnostic accuracy. The proposed strategy was tested in a small dataset of 321 images created to train and validate an automatic method for assessing the quality of cleanliness of esophagogastroduodenoscopy images. By combining real and synthetic data, an increase of over 18% in the accuracy of the most challenging underrepresented class was observed. The proposed strategy not only benefited the underrepresented class but also led to a general improvement in other metrics, including a 6% increase in global accuracy and precision.
Read more9/17/2024