Tabular Data Augmentation for Machine Learning: Progress and Prospects of Embracing Generative AI

0
📊
Sign in to get full access
Overview
- Machine learning on tabular data is common, but getting high-quality tabular data for training models remains a significant challenge.
- Many works have focused on tabular data augmentation (TDA) to enhance the original table with additional data, improving downstream machine learning tasks.
- There is growing interest in using generative AI for TDA, so a comprehensive review of the progress and future prospects of TDA, especially with generative AI, is timely.
Plain English Explanation
Tabular data, like spreadsheets or database tables, is widely used in machine learning. However, getting enough high-quality tabular data to train models can be difficult. To address this, researchers have developed tabular data augmentation (TDA) - techniques to add new, synthetic data to the original table. This can improve the performance of machine learning models.
Recently, there has been increasing interest in using generative AI to generate this new data, rather than just retrieving it from external sources. The authors believe it is now time to provide a comprehensive review of the current state of TDA, with a focus on the emerging use of generative AI.
Technical Explanation
The paper presents an architectural view of the TDA pipeline, which consists of three main procedures:
-
Pre-augmentation: Preparation tasks that facilitate subsequent TDA, including error handling, table annotation, table simplification, table representation, table indexing, table navigation, schema matching, and entity matching.
-
Augmentation: Current TDA methods, categorized into retrieval-based (retrieving external data) and generation-based (generating synthetic data). These methods operate at different granularities: row, column, cell, and table levels.
-
Post-augmentation: Aspects related to the augmented datasets, evaluation, and optimization of TDA.
The paper also summarizes current trends and future directions for TDA, highlighting promising opportunities in the era of generative AI.
Critical Analysis
The paper provides a thorough overview of the TDA landscape, including the various pre-processing, augmentation, and post-processing steps involved. It highlights the growing importance of generative AI in the field of TDA, which could lead to more effective data augmentation techniques.
However, the paper does not delve deeply into the specific limitations or potential issues with the current TDA methods, especially when using generative AI. It would be helpful to have a more critical analysis of the strengths, weaknesses, and potential biases or risks associated with these approaches.
Additionally, the paper could have provided more concrete examples or case studies to illustrate the practical applications and benefits of TDA, particularly when leveraging generative AI.
Conclusion
This paper provides a comprehensive overview of the current state of tabular data augmentation (TDA), with a focus on the emerging use of generative AI. It outlines the key steps in the TDA pipeline, including pre-augmentation, augmentation, and post-augmentation, and summarizes the various methods and techniques within each step.
The growing importance of generative AI in the field of TDA is highlighted, suggesting that this area will continue to be an active area of research and development. While the paper does not delve deeply into the specific limitations or issues with current TDA approaches, it serves as a valuable resource for understanding the current landscape and future prospects of this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Tabular Data Augmentation for Machine Learning: Progress and Prospects of Embracing Generative AI
Lingxi Cui, Huan Li, Ke Chen, Lidan Shou, Gang Chen
Machine learning (ML) on tabular data is ubiquitous, yet obtaining abundant high-quality tabular data for model training remains a significant obstacle. Numerous works have focused on tabular data augmentation (TDA) to enhance the original table with additional data, thereby improving downstream ML tasks. Recently, there has been a growing interest in leveraging the capabilities of generative AI for TDA. Therefore, we believe it is time to provide a comprehensive review of the progress and future prospects of TDA, with a particular emphasis on the trending generative AI. Specifically, we present an architectural view of the TDA pipeline, comprising three main procedures: pre-augmentation, augmentation, and post-augmentation. Pre-augmentation encompasses preparation tasks that facilitate subsequent TDA, including error handling, table annotation, table simplification, table representation, table indexing, table navigation, schema matching, and entity matching. Augmentation systematically analyzes current TDA methods, categorized into retrieval-based methods, which retrieve external data, and generation-based methods, which generate synthetic data. We further subdivide these methods based on the granularity of the augmentation process at the row, column, cell, and table levels. Post-augmentation focuses on the datasets, evaluation and optimization aspects of TDA. We also summarize current trends and future directions for TDA, highlighting promising opportunities in the era of generative AI. In addition, the accompanying papers and related resources are continuously updated and maintained in the GitHub repository at https://github.com/SuDIS-ZJU/awesome-tabular-data-augmentation to reflect ongoing advancements in the field.
Read more8/1/2024
📊
0
A Unified Framework for Generative Data Augmentation: A Comprehensive Survey
Yunhao Chen, Zihui Yan, Yunjie Zhu
Generative data augmentation (GDA) has emerged as a promising technique to alleviate data scarcity in machine learning applications. This thesis presents a comprehensive survey and unified framework of the GDA landscape. We first provide an overview of GDA, discussing its motivation, taxonomy, and key distinctions from synthetic data generation. We then systematically analyze the critical aspects of GDA - selection of generative models, techniques to utilize them, data selection methodologies, validation approaches, and diverse applications. Our proposed unified framework categorizes the extensive GDA literature, revealing gaps such as the lack of universal benchmarks. The thesis summarises promising research directions, including , effective data selection, theoretical development for large-scale models' application in GDA and establishing a benchmark for GDA. By laying a structured foundation, this thesis aims to nurture more cohesive development and accelerate progress in the vital arena of generative data augmentation.
Read more4/23/2024
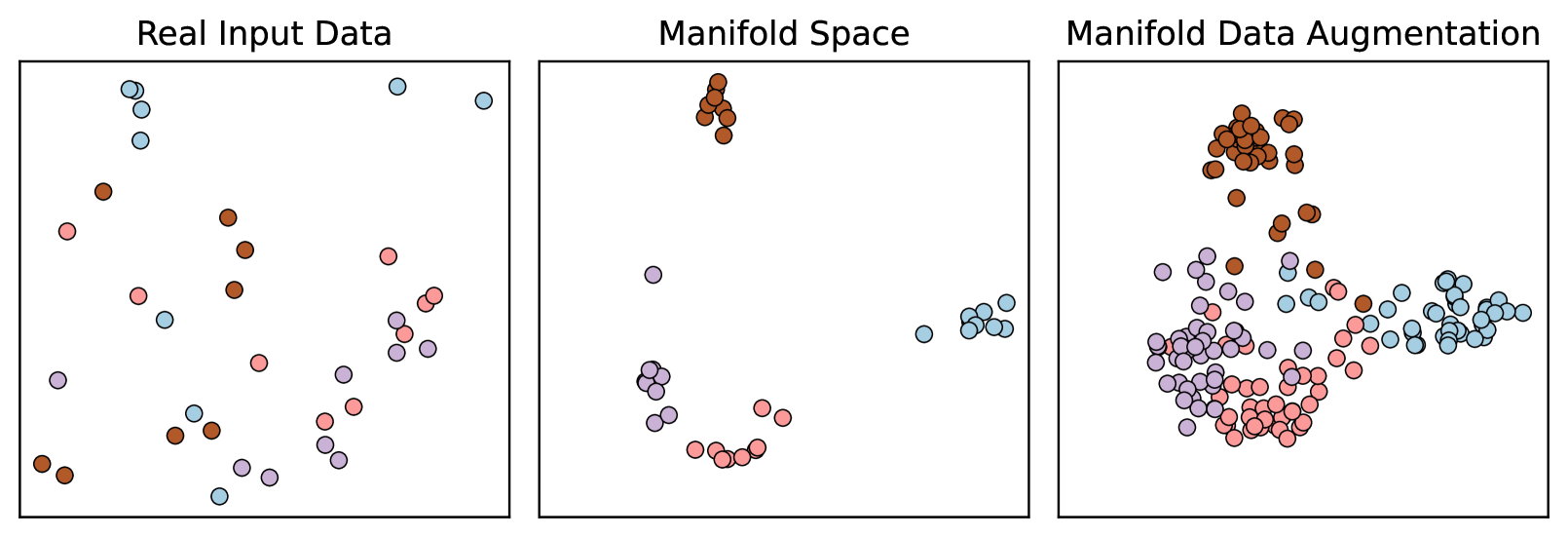
0
TabMDA: Tabular Manifold Data Augmentation for Any Classifier using Transformers with In-context Subsetting
Andrei Margeloiu, Adri'an Bazaga, Nikola Simidjievski, Pietro Li`o, Mateja Jamnik
Tabular data is prevalent in many critical domains, yet it is often challenging to acquire in large quantities. This scarcity usually results in poor performance of machine learning models on such data. Data augmentation, a common strategy for performance improvement in vision and language tasks, typically underperforms for tabular data due to the lack of explicit symmetries in the input space. To overcome this challenge, we introduce TabMDA, a novel method for manifold data augmentation on tabular data. This method utilises a pre-trained in-context model, such as TabPFN, to map the data into an embedding space. TabMDA performs label-invariant transformations by encoding the data multiple times with varied contexts. This process explores the learned embedding space of the underlying in-context models, thereby enlarging the training dataset. TabMDA is a training-free method, making it applicable to any classifier. We evaluate TabMDA on five standard classifiers and observe significant performance improvements across various tabular datasets. Our results demonstrate that TabMDA provides an effective way to leverage information from pre-trained in-context models to enhance the performance of downstream classifiers. Code is available at https://github.com/AdrianBZG/TabMDA.
Read more7/30/2024
📊
0
Data Augmentation for Time-Series Classification: An Extensive Empirical Study and Comprehensive Survey
Zijun Gao, Haibao Liu, Lingbo Li
Data Augmentation (DA) has become a critical approach in Time Series Classification (TSC), primarily for its capacity to expand training datasets, enhance model robustness, introduce diversity, and reduce overfitting. However, the current landscape of DA in TSC is plagued with fragmented literature reviews, nebulous methodological taxonomies, inadequate evaluative measures, and a dearth of accessible and user-oriented tools. This study addresses these challenges through a comprehensive examination of DA methodologies within the TSC domain.Our research began with an extensive literature review spanning a decade, revealing significant gaps in existing surveys and necessitating a detailed analysis of over 100 scholarly articles to identify more than 60 distinct DA techniques. This rigorous review led to the development of a novel taxonomy tailored to the specific needs of DA in TSC, categorizing techniques into five primary categories: Transformation-Based, Pattern-Based, Generative, Decomposition-Based, and Automated Data Augmentation. This taxonomy is intended to guide researchers in selecting appropriate methods with greater clarity. In response to the lack of comprehensive evaluations of foundational DA techniques, we conducted a thorough empirical study, testing nearly 20 DA strategies across 15 diverse datasets representing all types within the UCR time-series repository. Using ResNet and LSTM architectures, we employed a multifaceted evaluation approach, including metrics such as Accuracy, Method Ranking, and Residual Analysis, resulting in a benchmark accuracy of 84.98 +- 16.41% in ResNet and 82.41 +- 18.71% in LSTM. Our investigation underscored the inconsistent efficacies of DA techniques, for instance, methods like RGWs and Random Permutation significantly improved model performance, whereas others, like EMD, were less effective.
Read more8/27/2024