TACE: Tumor-Aware Counterfactual Explanations

0
🔗
Sign in to get full access
Overview
- Proposes a new approach called TACE (Tumor-Aware Counterfactual Explanations) for generating counterfactual explanations for AI models, with a focus on medical imaging applications.
- Aims to generate counterfactual explanations that are tailored to the specific characteristics of a tumor, rather than relying on generic counterfactuals.
- Leverages information about the tumor's location, size, and other attributes to guide the counterfactual generation process.
Plain English Explanation
TACE: Tumor-Aware Counterfactual Explanations presents a new approach to help explain the decisions of AI models, particularly in the context of medical imaging. The key idea is to generate "counterfactual explanations" that are specifically tailored to the characteristics of a tumor or other medical condition.
Counterfactual explanations are a type of explanation that show how the model's output would change if certain input features were different. For example, a counterfactual explanation for a cancer diagnosis might say "If the tumor was 20% smaller, the model would have predicted a lower risk of cancer."
The TACE method aims to make these counterfactual explanations more relevant and useful by incorporating specific information about the tumor, such as its location, size, and other attributes. This helps ensure the counterfactuals are meaningful and aligned with the medical context, rather than being generic or potentially misleading.
By generating tumor-aware counterfactual explanations, the researchers hope to provide doctors and patients with more targeted and actionable insights into how an AI model is making its predictions. This could improve trust in the model and help guide treatment decisions.
Technical Explanation
TACE: Tumor-Aware Counterfactual Explanations proposes a new framework for generating counterfactual explanations that are tailored to the specific characteristics of a tumor or other medical condition.
The core of the TACE approach is to leverage information about the tumor, such as its location, size, and other attributes, to guide the counterfactual generation process. This is in contrast to more generic counterfactual explanations that do not take the medical context into account.
The researchers developed a two-stage process for generating the tumor-aware counterfactuals. First, they train a neural network to predict the tumor's attributes from the medical image. Then, they use an optimization-based approach to find counterfactual images that change the model's prediction while respecting the constraints imposed by the tumor's characteristics.
The authors evaluated TACE on a dataset of brain MRI scans and showed that the tumor-aware counterfactuals were more informative and relevant compared to standard counterfactual explanations. The counterfactuals generated by TACE highlighted changes to the tumor's size, location, and other properties that would lead to different model predictions.
Critical Analysis
The TACE: Tumor-Aware Counterfactual Explanations paper presents a promising approach for generating more meaningful counterfactual explanations in medical imaging applications. By incorporating tumor-specific information, the method aims to provide more targeted and actionable insights compared to generic counterfactuals.
However, the authors acknowledge several limitations and areas for future research. For example, the current implementation relies on a pre-trained model for predicting tumor attributes, which may not always be available. Additionally, the optimization-based counterfactual generation can be computationally intensive and may not scale well to larger or more complex medical datasets.
Another potential concern is the extent to which the tumor-aware counterfactuals truly reflect clinically meaningful changes. While the authors demonstrate the relevance of the counterfactuals, further validation from domain experts would be valuable to ensure the explanations align with medical best practices and decision-making processes.
Overall, the TACE approach represents an important step towards more contextual and interpretable AI systems in medical imaging. However, continued research and collaboration with healthcare professionals will be crucial to address the remaining challenges and fully realize the potential of this technology.
Conclusion
TACE: Tumor-Aware Counterfactual Explanations introduces a novel framework for generating counterfactual explanations that are tailored to the specific characteristics of a tumor or other medical condition. By incorporating information about the tumor's location, size, and other attributes, the TACE method aims to provide more relevant and actionable insights into how an AI model is making its predictions.
The authors demonstrate the effectiveness of TACE on a brain MRI dataset, showing that the tumor-aware counterfactuals are more informative and aligned with the medical context compared to standard counterfactual explanations. This work represents an important step towards improving the interpretability and trust in AI-powered medical imaging systems, which could ultimately help guide treatment decisions and improve patient outcomes.
While TACE shows promise, the authors acknowledge several limitations and areas for future research, such as the dependence on pre-trained tumor attribute models and the computational complexity of the counterfactual generation process. Continued collaboration with domain experts will be crucial to further refine the method and ensure the generated explanations are clinically meaningful and aligned with best practices in healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
0
TACE: Tumor-Aware Counterfactual Explanations
Eleonora Beatrice Rossi, Eleonora Lopez, Danilo Comminiello
The application of deep learning in medical imaging has significantly advanced diagnostic capabilities, enhancing both accuracy and efficiency. Despite these benefits, the lack of transparency in these AI models, often termed black boxes, raises concerns about their reliability in clinical settings. Explainable AI (XAI) aims to mitigate these concerns by developing methods that make AI decisions understandable and trustworthy. In this study, we propose Tumor Aware Counterfactual Explanations (TACE), a framework designed to generate reliable counterfactual explanations for medical images. Unlike existing methods, TACE focuses on modifying tumor-specific features without altering the overall organ structure, ensuring the faithfulness of the counterfactuals. We achieve this by including an additional step in the generation process which allows to modify only the region of interest (ROI), thus yielding more reliable counterfactuals as the rest of the organ remains unchanged. We evaluate our method on mammography images and brain MRI. We find that our method far exceeds existing state-of-the-art techniques in quality, faithfulness, and generation speed of counterfactuals. Indeed, more faithful explanations lead to a significant improvement in classification success rates, with a 10.69% increase for breast cancer and a 98.02% increase for brain tumors. The code of our work is available at https://github.com/ispamm/TACE.
Read more9/23/2024
0
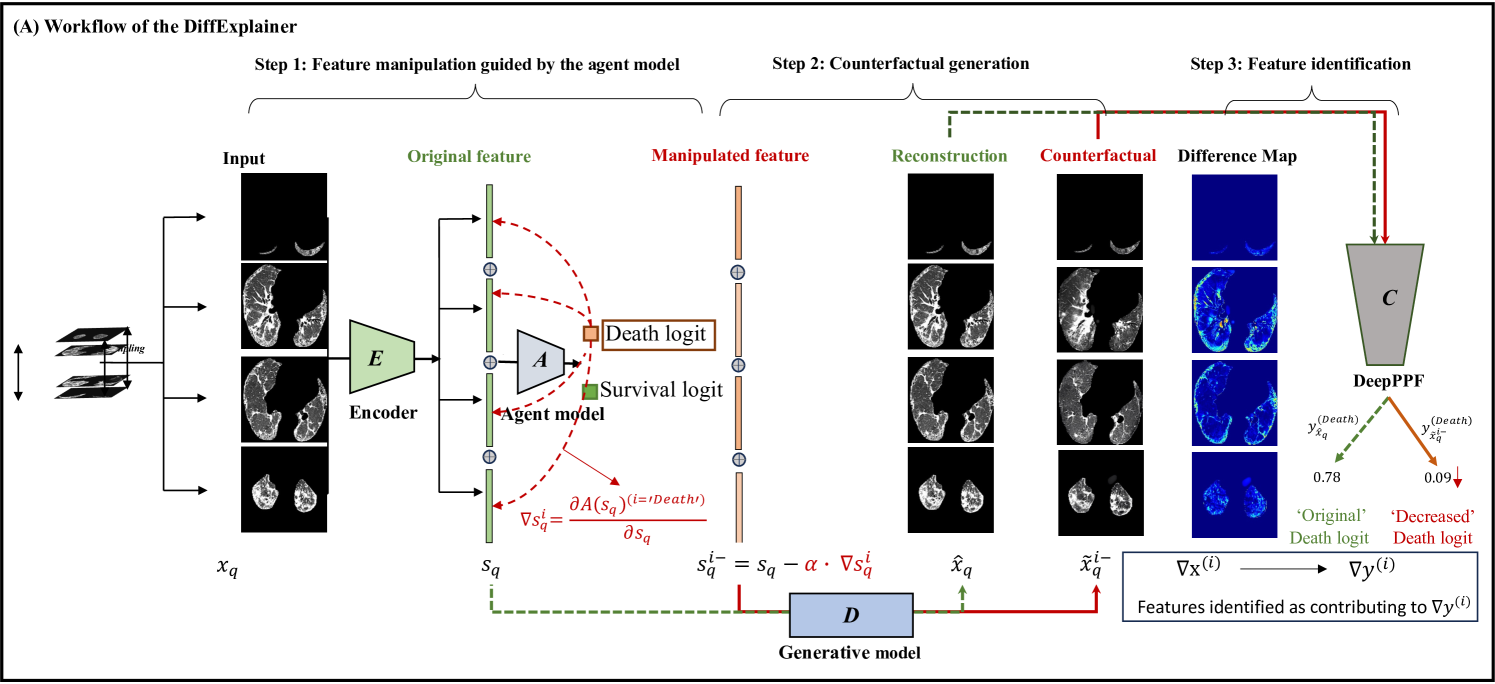
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
Yingying Fang, Shuang Wu, Zihao Jin, Caiwen Xu, Shiyi Wang, Simon Walsh, Guang Yang
In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.
Read more6/28/2024

0
Contrastive Learning with Counterfactual Explanations for Radiology Report Generation
Mingjie Li, Haokun Lin, Liang Qiu, Xiaodan Liang, Ling Chen, Abdulmotaleb Elsaddik, Xiaojun Chang
Due to the common content of anatomy, radiology images with their corresponding reports exhibit high similarity. Such inherent data bias can predispose automatic report generation models to learn entangled and spurious representations resulting in misdiagnostic reports. To tackle these, we propose a novel textbf{Co}untertextbf{F}actual textbf{E}xplanations-based framework (CoFE) for radiology report generation. Counterfactual explanations serve as a potent tool for understanding how decisions made by algorithms can be changed by asking ``what if'' scenarios. By leveraging this concept, CoFE can learn non-spurious visual representations by contrasting the representations between factual and counterfactual images. Specifically, we derive counterfactual images by swapping a patch between positive and negative samples until a predicted diagnosis shift occurs. Here, positive and negative samples are the most semantically similar but have different diagnosis labels. Additionally, CoFE employs a learnable prompt to efficiently fine-tune the pre-trained large language model, encapsulating both factual and counterfactual content to provide a more generalizable prompt representation. Extensive experiments on two benchmarks demonstrate that leveraging the counterfactual explanations enables CoFE to generate semantically coherent and factually complete reports and outperform in terms of language generation and clinical efficacy metrics.
Read more7/22/2024
🎯
0
Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
Catarina Moreira, Yu-Liang Chou, Chihcheng Hsieh, Chun Ouyang, Joaquim Jorge, Jo~ao Madeiras Pereira
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
Read more6/12/2024