Tackling GenAI Copyright Issues: Originality Estimation and Genericization

0
🌀
Sign in to get full access
Overview
- This paper explores the complex and evolving landscape of copyright law in the era of generative AI models.
- It examines the multifaceted challenges and nuances involved in determining what constitutes copyright infringement when using AI-generated content.
- The research covers a range of relevant topics, including the economic implications of copyright issues with generative AI, the rethinking of artistic copyright infringement, and the uncertain boundaries and multidisciplinary approaches to these copyright issues.
Plain English Explanation
The paper discusses the complex relationship between generative AI models and copyright law. As these advanced AI systems become more capable of creating content that resembles human-made work, it raises challenging questions about what constitutes copyright infringement. The research explores the nuances involved, such as the notion that not all similarities are created equal when it comes to leveraging AI-generated content. It also examines the potential economic impact of these copyright issues and the need for a rethinking of how we approach artistic copyright infringement in the era of text-to-image and other generative AI models. The paper highlights the uncertain boundaries and the importance of multidisciplinary approaches to address these complex and evolving copyright challenges.
Technical Explanation
The paper delves into the technical aspects of how generative AI models can potentially infringe on copyrights. It explores the concept of "disguised copyright infringement" where the AI-generated content may not be a direct copy but still bear significant similarities to the original work. The research examines the nuances of these similarities and how they can be leveraged in various applications.
The paper also discusses the economic implications of these copyright issues, exploring potential solutions and the need for a balanced approach that considers the interests of both creators and AI developers. Furthermore, it examines the challenges of rethinking artistic copyright infringement in the context of text-to-image and other generative AI models, which can blur the lines between original and derivative work.
Critical Analysis
The paper acknowledges the inherent complexities and uncertainties surrounding the intersection of generative AI and copyright law. It highlights the need for a multidisciplinary approach that considers legal, technological, and societal perspectives to address these evolving challenges.
While the paper provides a comprehensive overview of the key issues, it could benefit from a more in-depth discussion of the potential long-term implications and the ethical considerations involved. The research could also explore more specific case studies or examples to illustrate the practical difficulties in differentiating between legitimate and infringing uses of AI-generated content.
Additionally, the paper could delve deeper into the potential unintended consequences of overly restrictive copyright policies, and the need to strike a balance between protecting the rights of creators and fostering innovation in the field of generative AI.
Conclusion
This paper offers a timely and insightful exploration of the complex relationship between generative AI and copyright law. It highlights the nuances and uncertainties involved in determining what constitutes copyright infringement, the economic implications, and the need for a multidisciplinary approach to address these evolving challenges.
As generative AI models continue to advance, the issues raised in this research will become increasingly important for policymakers, legal experts, and the broader public to understand and address. The paper serves as a valuable starting point for further discussions and research in this critical domain, which will have significant implications for the future of creativity, innovation, and the protection of intellectual property.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Tackling GenAI Copyright Issues: Originality Estimation and Genericization
Hiroaki Chiba-Okabe, Weijie J. Su
The rapid progress of generative AI technology has sparked significant copyright concerns, leading to numerous lawsuits filed against AI developers. While various techniques for mitigating copyright issues have been studied, significant risks remain. Here, we propose a genericization method that modifies the outputs of a generative model to make them more generic and less likely to infringe copyright. To achieve this, we introduce a metric for quantifying the level of originality of data in a manner that is consistent with the legal framework. This metric can be practically estimated by drawing samples from a generative model, which is then used for the genericization process. As a practical implementation, we introduce PREGen, which combines our genericization method with an existing mitigation technique. Experiments demonstrate that our genericization method successfully modifies the output of a text-to-image generative model so that it produces more generic, copyright-compliant images. Compared to the existing method, PREGen reduces the likelihood of generating copyrighted characters by more than half when the names of copyrighted characters are used as the prompt, dramatically improving the performance. Additionally, while generative models can produce copyrighted characters even when their names are not directly mentioned in the prompt, PREGen almost entirely prevents the generation of such characters in these cases.
Read more8/27/2024

0
Not All Similarities Are Created Equal: Leveraging Data-Driven Biases to Inform GenAI Copyright Disputes
Uri Hacohen, Adi Haviv, Shahar Sarfaty, Bruria Friedman, Niva Elkin-Koren, Roi Livni, Amit H Bermano
The advent of Generative Artificial Intelligence (GenAI) models, including GitHub Copilot, OpenAI GPT, and Stable Diffusion, has revolutionized content creation, enabling non-professionals to produce high-quality content across various domains. This transformative technology has led to a surge of synthetic content and sparked legal disputes over copyright infringement. To address these challenges, this paper introduces a novel approach that leverages the learning capacity of GenAI models for copyright legal analysis, demonstrated with GPT2 and Stable Diffusion models. Copyright law distinguishes between original expressions and generic ones (Sc`enes `a faire), protecting the former and permitting reproduction of the latter. However, this distinction has historically been challenging to make consistently, leading to over-protection of copyrighted works. GenAI offers an unprecedented opportunity to enhance this legal analysis by revealing shared patterns in preexisting works. We propose a data-driven approach to identify the genericity of works created by GenAI, employing data-driven bias to assess the genericity of expressive compositions. This approach aids in copyright scope determination by utilizing the capabilities of GenAI to identify and prioritize expressive elements and rank them according to their frequency in the model's dataset. The potential implications of measuring expressive genericity for copyright law are profound. Such scoring could assist courts in determining copyright scope during litigation, inform the registration practices of Copyright Offices, allowing registration of only highly original synthetic works, and help copyright owners signal the value of their works and facilitate fairer licensing deals. More generally, this approach offers valuable insights to policymakers grappling with adapting copyright law to the challenges posed by the era of GenAI.
Read more5/8/2024
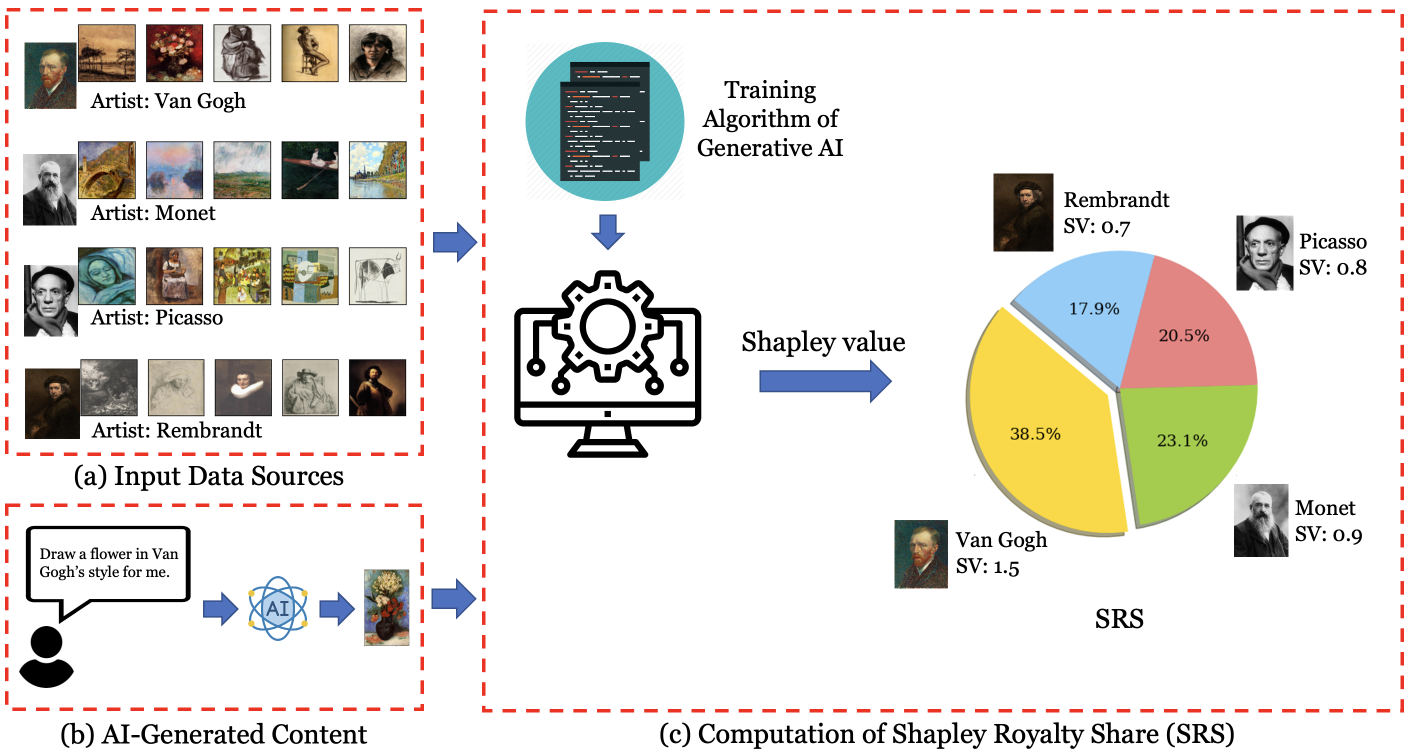
0
An Economic Solution to Copyright Challenges of Generative AI
Jiachen T. Wang, Zhun Deng, Hiroaki Chiba-Okabe, Boaz Barak, Weijie J. Su
Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
Read more9/10/2024
✅
0
Copyright Protection in Generative AI: A Technical Perspective
Jie Ren, Han Xu, Pengfei He, Yingqian Cui, Shenglai Zeng, Jiankun Zhang, Hongzhi Wen, Jiayuan Ding, Pei Huang, Lingjuan Lyu, Hui Liu, Yi Chang, Jiliang Tang
Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
Read more7/25/2024