Tackling Structural Hallucination in Image Translation with Local Diffusion

0

Sign in to get full access
Overview
• This paper introduces a novel approach called "Local Diffusion" to address the issue of structural hallucination in image translation tasks.
• Structural hallucination refers to the tendency of image translation models to generate unrealistic or distorted structural elements, leading to poor quality outputs.
• The proposed Local Diffusion method aims to improve the performance of image translation models by incorporating local information and constraints during the diffusion process.
Plain English Explanation
Image translation is the task of transforming an input image from one domain to another, such as converting a sketch into a realistic rendering or transforming a grayscale image into a colorized version. However, existing image translation models often struggle with "structural hallucination," where they generate unrealistic or distorted structural elements in the output image, leading to lower quality results.
The researchers behind this paper developed a new approach called "Local Diffusion" to address this issue. Diffusion models are a type of machine learning model that can generate new images by gradually adding noise to an input image and then reversing the process to generate a new, realistic-looking image. The key innovation of Local Diffusion is that it incorporates local information and constraints during this diffusion process, helping the model better preserve the structure and integrity of the translated image.
By focusing on local regions rather than the entire image, the Local Diffusion approach can better capture and maintain the important structural details that are often lost in traditional image translation models. This results in higher-quality, more realistic output images that better match the desired target domain.
Technical Explanation
The core of the Local Diffusion method is the incorporation of local information and constraints during the diffusion process. Traditionally, diffusion models operate on the entire image, which can lead to the generation of unrealistic structural elements due to the lack of localized context and information.
In contrast, the Local Diffusion approach divides the input image into smaller, overlapping patches, and applies the diffusion process independently to each patch. This allows the model to better capture and maintain the local structural details of the image, preventing the generation of distorted or hallucinated elements.
Additionally, the researchers introduce a set of local constraints, such as preserving edges and local intensity distributions, to further guide the diffusion process and ensure the translated output closely matches the desired target domain.
The authors evaluate the performance of Local Diffusion on a range of image translation tasks, including sketch-to-photo, grayscale-to-color, and others. The results demonstrate that the proposed method outperforms previous state-of-the-art approaches in terms of preserving structural integrity and generating more realistic, high-quality translated images.
Critical Analysis
The paper presents a compelling solution to the problem of structural hallucination in image translation, which is a common issue faced by many existing models. The Local Diffusion approach is a well-designed and thoughtful innovation that leverages the strengths of diffusion models while addressing their limitations.
One potential limitation of the study is the focus on a relatively narrow set of image translation tasks. While the authors demonstrate the effectiveness of Local Diffusion on several common benchmarks, it would be valuable to see how the method performs on a wider range of image translation problems, including more complex or domain-specific tasks.
Additionally, the paper does not provide a deep dive into the computational cost or inference time of the Local Diffusion approach compared to other methods. As real-world deployments often require efficient models, understanding the trade-offs between performance and computational requirements would be a useful addition to the analysis.
Overall, the Local Diffusion method represents a significant step forward in addressing the issue of structural hallucination in image translation, and the paper's findings suggest it could have a meaningful impact on the field. Further research exploring the broader applicability and efficiency of the approach would be a valuable contribution.
Conclusion
This paper presents a novel image translation approach called "Local Diffusion" that effectively addresses the problem of structural hallucination. By incorporating local information and constraints into the diffusion process, the proposed method is able to generate more realistic and high-quality translated images compared to previous state-of-the-art techniques.
The key innovation of Local Diffusion lies in its ability to preserve the structural integrity of the input image during the translation process, preventing the generation of distorted or unrealistic elements. This represents an important advancement in the field of image translation, with potential applications in a wide range of domains, from digital art and content creation to medical imaging and urban planning.
While the paper focuses on a select set of image translation tasks, the underlying principles of Local Diffusion could be further explored and extended to tackle an even broader range of translation problems. As such, this research lays the groundwork for continued progress in addressing the challenges of structural hallucination and improving the overall quality and realism of translated images.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tackling Structural Hallucination in Image Translation with Local Diffusion
Seunghoi Kim, Chen Jin, Tom Diethe, Matteo Figini, Henry F. J. Tregidgo, Asher Mullokandov, Philip Teare, Daniel C. Alexander
Recent developments in diffusion models have advanced conditioned image generation, yet they struggle with reconstructing out-of-distribution (OOD) images, such as unseen tumors in medical images, causing image hallucination and risking misdiagnosis. We hypothesize such hallucinations result from local OOD regions in the conditional images. We verify that partitioning the OOD region and conducting separate image generations alleviates hallucinations in several applications. From this, we propose a training-free diffusion framework that reduces hallucination with multiple Local Diffusion processes. Our approach involves OOD estimation followed by two modules: a branching module generates locally both within and outside OOD regions, and a fusion module integrates these predictions into one. Our evaluation shows our method mitigates hallucination over baseline models quantitatively and qualitatively, reducing misdiagnosis by 40% and 25% in the real-world medical and natural image datasets, respectively. It also demonstrates compatibility with various pre-trained diffusion models.
Read more7/18/2024
2
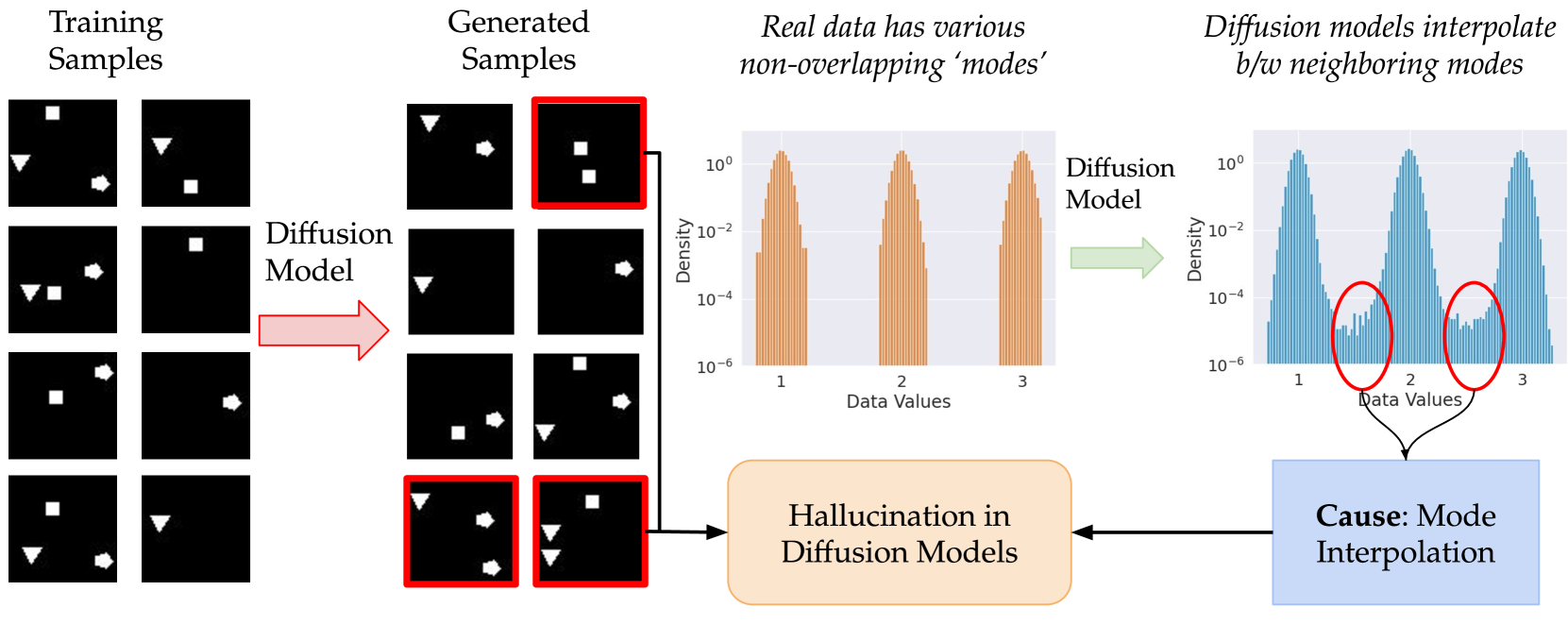
Understanding Hallucinations in Diffusion Models through Mode Interpolation
Sumukh K Aithal, Pratyush Maini, Zachary C. Lipton, J. Zico Kolter
Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit hallucinations, samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term mode interpolation. Specifically, we find that diffusion models smoothly interpolate between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations). We systematically study the reasons for, and the manifestation of this phenomenon. Through experiments on 1D and 2D Gaussians, we show how a discontinuous loss landscape in the diffusion model's decoder leads to a region where any smooth approximation will cause such hallucinations. Through experiments on artificial datasets with various shapes, we show how hallucination leads to the generation of combinations of shapes that never existed. Finally, we show that diffusion models in fact know when they go out of support and hallucinate. This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling process. Using a simple metric to capture this variance, we can remove over 95% of hallucinations at generation time while retaining 96% of in-support samples. We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on MNIST and 2D Gaussians dataset. We release our code at https://github.com/locuslab/diffusion-model-hallucination.
Read more8/27/2024
0
Exploiting Diffusion Prior for Out-of-Distribution Detection
Armando Zhu, Jiabei Liu, Keqin Li, Shuying Dai, Bo Hong, Peng Zhao, Changsong Wei
Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models, especially in areas where security is critical. However, traditional OOD detection methods often fail to capture complex data distributions from large scale date. In this paper, we present a novel approach for OOD detection that leverages the generative ability of diffusion models and the powerful feature extraction capabilities of CLIP. By using these features as conditional inputs to a diffusion model, we can reconstruct the images after encoding them with CLIP. The difference between the original and reconstructed images is used as a signal for OOD identification. The practicality and scalability of our method is increased by the fact that it does not require class-specific labeled ID data, as is the case with many other methods. Extensive experiments on several benchmark datasets demonstrates the robustness and effectiveness of our method, which have significantly improved the detection accuracy.
Read more8/22/2024

0
Optimizing Resource Consumption in Diffusion Models through Hallucination Early Detection
Federico Betti, Lorenzo Baraldi, Lorenzo Baraldi, Rita Cucchiara, Nicu Sebe
Diffusion models have significantly advanced generative AI, but they encounter difficulties when generating complex combinations of multiple objects. As the final result heavily depends on the initial seed, accurately ensuring the desired output can require multiple iterations of the generation process. This repetition not only leads to a waste of time but also increases energy consumption, echoing the challenges of efficiency and accuracy in complex generative tasks. To tackle this issue, we introduce HEaD (Hallucination Early Detection), a new paradigm designed to swiftly detect incorrect generations at the beginning of the diffusion process. The HEaD pipeline combines cross-attention maps with a new indicator, the Predicted Final Image, to forecast the final outcome by leveraging the information available at early stages of the generation process. We demonstrate that using HEaD saves computational resources and accelerates the generation process to get a complete image, i.e. an image where all requested objects are accurately depicted. Our findings reveal that HEaD can save up to 12% of the generation time on a two objects scenario and underscore the importance of early detection mechanisms in generative models.
Read more9/18/2024