Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs

0
📊
Sign in to get full access
Overview
- Humans naturally use more efficient language as conversations progress, creating ad-hoc conventions.
- It's unclear if multimodal large language models (MLLMs) can also adapt their language to be more efficient during interactions.
- Researchers introduce ICCA, a framework to evaluate conversational adaptation in MLLMs.
- Experiments show that while MLLMs can understand efficient language, they do not spontaneously make their own language more efficient over time.
Plain English Explanation
As people talk to each other, they often develop their own shortcuts and conventions to communicate more efficiently. For example, if you're discussing a complex topic with a friend, you might start using shorthand or jargon that you both understand, rather than explaining everything in detail each time. This type of linguistic adaptation is a natural part of human conversation.
Researchers wanted to see if large language models that can process and generate text and images (called multimodal large language models or MLLMs) could also adapt their language in a similar way during interactions. They created a framework called ICCA to test this.
The experiments revealed that while these language models can understand when their conversation partner is using more efficient language, the models themselves don't spontaneously make their own language more efficient over the course of a conversation. This ability to adapt your own language use can only be elicited in some models, like GPT-4, and requires very specific instructions.
This shows that the natural language adaptation seen in human conversations is not something that current training approaches for large language models have been able to capture. Even though it's a common feature of how people communicate, this property hasn't emerged in the models tested so far.
Technical Explanation
The researchers introduced the ICCA (Interaction-based Conversational Adaptation) framework to evaluate whether multimodal large language models (MLLMs) can adapt their language to be more efficient during interactions, similar to how humans do.
They conducted experiments using several state-of-the-art MLLMs, including GPT-4. The models were tasked with participating in a series of reference games, where they had to identify images based on a partner's descriptions. As the games progressed, the partner's descriptions became more concise and efficient.
The results showed that the MLLMs were able to understand the increasingly efficient language used by their partners. However, the models did not spontaneously make their own language more efficient over the course of the interactions. This ability to adapt one's own language use could only be elicited in some models, like GPT-4, and required very specific prompting instructions.
This suggests that the natural linguistic adaptation observed in human conversations is not something that current training approaches for large language models have been able to capture. Even though it's a common feature of how people communicate, this property has not yet emerged in the models tested.
Critical Analysis
The researchers acknowledge that the inability of MLLMs to spontaneously adapt their language during interactions is a limitation of current training approaches. They suggest that future research should explore ways to instill this capability in large language models, perhaps by incorporating more interactive learning environments or socially-aware training signals.
One potential concern is that the reference game used in the experiments may not fully capture the nuances of real-world conversational dynamics. It's possible that more complex, open-ended dialogue scenarios could reveal different patterns of language adaptation in MLLMs.
Additionally, the researchers only tested a limited set of state-of-the-art models. It's possible that future advancements in language model architecture or training techniques could lead to more natural language adaptation abilities, which the ICCA framework could help to identify.
Overall, the findings highlight an important gap between human and machine communication, and suggest that further research is needed to understand how to develop language models that can engage in truly adaptable and efficient dialogues.
Conclusion
This research reveals that while multimodal large language models can understand and respond to increasingly efficient language, they do not spontaneously adapt their own language use in the same way that humans do during conversations.
The introduction of the ICCA framework provides a valuable tool for evaluating this specific aspect of conversational ability in language models. The results suggest that current training approaches have not yet captured the natural linguistic adaptation seen in human interactions, pointing to an important area for future research and development in the field of conversational AI.
By understanding the limitations of existing language models in this regard, researchers can work to build more socially and linguistically aware conversational agents that can engage in truly adaptive and efficient dialogue.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs
Yilun Hua, Yoav Artzi
Humans spontaneously use increasingly efficient language as interactions progress, by adapting and forming ad-hoc conventions. This phenomenon has been studied extensively using reference games, showing properties of human language that go beyond relaying intents. It remains unexplored whether multimodal large language models (MLLMs) similarly increase communication efficiency during interactions, and what mechanisms they may adopt for this purpose. We introduce ICCA, an automated framework to evaluate such conversational adaptation as an in-context behavior in MLLMs. We evaluate several state-of-the-art MLLMs, and observe that while they may understand the increasingly efficient language of their interlocutor, they do not spontaneously make their own language more efficient over time. This latter ability can only be elicited in some models (e.g., GPT-4) with heavy-handed prompting. This shows that this property of linguistic interaction does not arise from current training regimes, even though it is a common hallmark of human language. ICCA is available at https://github.com/lil-lab/ICCA.
Read more8/6/2024
🔎
0
Conversational Assistants in Knowledge-Intensive Contexts: An Evaluation of LLM- versus Intent-based Systems
Samuel Kernan Freire, Chaofan Wang, Evangelos Niforatos
Conversational Assistants (CA) are increasingly supporting human workers in knowledge management. Traditionally, CAs respond in specific ways to predefined user intents and conversation patterns. However, this rigidness does not handle the diversity of natural language well. Recent advances in natural language processing, namely Large Language Models (LLMs), enable CAs to converse in a more flexible, human-like manner, extracting relevant information from texts and capturing information from expert humans but introducing new challenges such as ``hallucinations''. To assess the potential of using LLMs for knowledge management tasks, we conducted a user study comparing an LLM-based CA to an intent-based system regarding interaction efficiency, user experience, workload, and usability. This revealed that LLM-based CAs exhibited better user experience, task completion rate, usability, and perceived performance than intent-based systems, suggesting that switching NLP techniques can be beneficial in the context of knowledge management.
Read more7/15/2024
0
Multimodal Contrastive In-Context Learning
Yosuke Miyanishi, Minh Le Nguyen
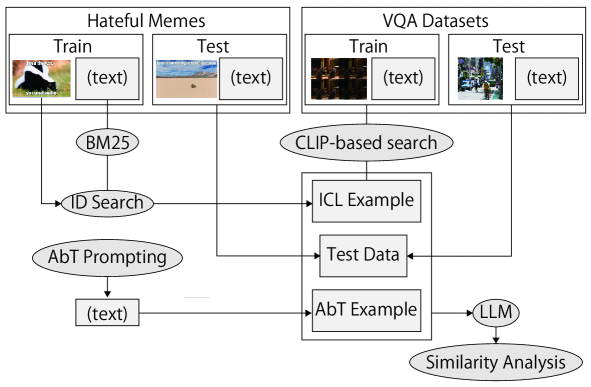
The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.
Read more8/26/2024
0
Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning
Mustafa Dogan, Ilker Kesen, Iacer Calixto, Aykut Erdem, Erkut Erdem
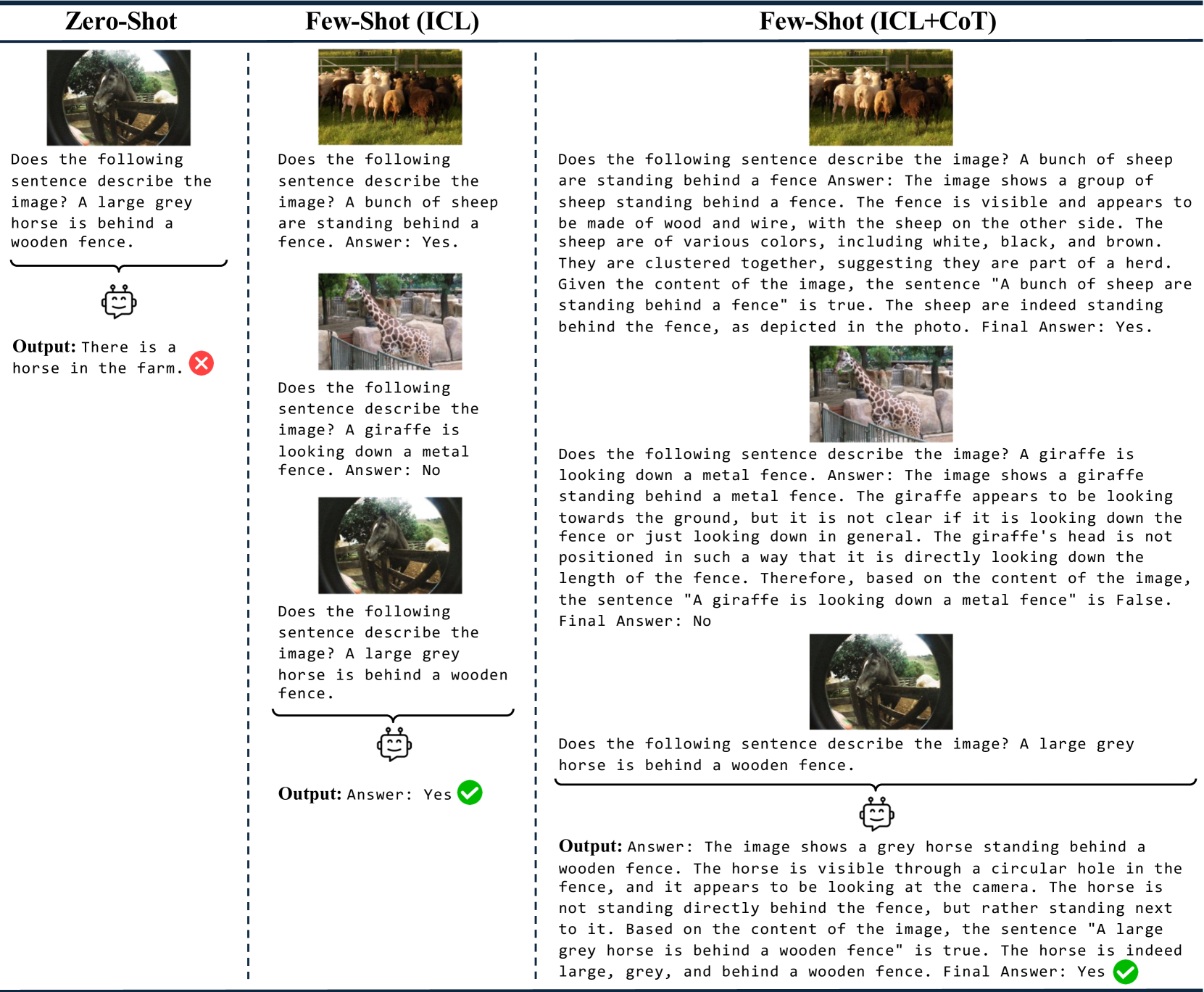
The linguistic capabilities of Multimodal Large Language Models (MLLMs) are critical for their effective application across diverse tasks. This study aims to evaluate the performance of MLLMs on the VALSE benchmark, focusing on the efficacy of few-shot In-Context Learning (ICL), and Chain-of-Thought (CoT) prompting. We conducted a comprehensive assessment of state-of-the-art MLLMs, varying in model size and pretraining datasets. The experimental results reveal that ICL and CoT prompting significantly boost model performance, particularly in tasks requiring complex reasoning and contextual understanding. Models pretrained on captioning datasets show superior zero-shot performance, while those trained on interleaved image-text data benefit from few-shot learning. Our findings provide valuable insights into optimizing MLLMs for better grounding of language in visual contexts, highlighting the importance of the composition of pretraining data and the potential of few-shot learning strategies to improve the reasoning abilities of MLLMs.
Read more7/18/2024