Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning

0
Sign in to get full access
Overview
• This paper evaluates the linguistic capabilities of multimodal large language models (LLMs) in the context of few-shot learning, which refers to the ability to learn new tasks or skills from a small amount of training data.
• The researchers investigate how well multimodal LLMs, which are trained on both text and visual data, can perform on language-based tasks, particularly in few-shot scenarios where limited training data is available.
Plain English Explanation
• Multimodal LLMs are a type of artificial intelligence that can understand and process both text and images. This paper looks at how well these models can perform on language tasks, even when they only have a small amount of training data to learn from.
• The researchers wanted to see if multimodal LLMs could still be effective at language tasks, like answering questions or completing sentences, even if they were only given a few examples to learn from. This is important because in the real world, we often don't have a lot of training data available, but we still want AI systems to be able to learn and perform well.
• By testing the multimodal LLMs in these few-shot learning scenarios, the researchers can better understand the limitations and capabilities of these models when it comes to language-based tasks. This can help guide the development of more capable and versatile AI systems in the future.
Technical Explanation
• The researchers used several well-known multimodal LLMs, including Multimodal Task Vectors, Can MLLMs Perform Text-to-Image Context, and Towards Multimodal Context Learning, to evaluate their performance on a range of language-based tasks.
• They tested the models in few-shot learning scenarios, where the models were only given a small number of examples to learn from, and then asked to perform tasks like question answering, sentence completion, and natural language inference.
• The researchers also investigated the impact of different types of visual information, such as images or diagrams, on the models' language understanding capabilities in these few-shot learning settings.
Critical Analysis
• The paper acknowledges that while the multimodal LLMs generally performed well on the language tasks, there are still limitations and areas for improvement.
• For example, the models may struggle with tasks that require deeper reasoning or commonsense understanding, which are challenging even for humans in few-shot scenarios.
• Additionally, the researchers note that the performance of the models can be heavily dependent on the specific training data and task design, and more research is needed to fully understand the strengths and weaknesses of these multimodal systems.
• Further work is also needed to explore how these models can be adapted and fine-tuned for specific domains or applications, as their general-purpose capabilities may not always translate directly to real-world use cases.
Conclusion
• This paper provides valuable insights into the linguistic capabilities of multimodal LLMs, particularly in the context of few-shot learning.
• The findings suggest that these models can be effective at language-based tasks, even with limited training data, but also highlight the need for continued research and development to address their current limitations.
• As the field of AI continues to advance, understanding the strengths and weaknesses of multimodal LLMs will be crucial in designing more capable and versatile systems that can adapt to a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning
Mustafa Dogan, Ilker Kesen, Iacer Calixto, Aykut Erdem, Erkut Erdem
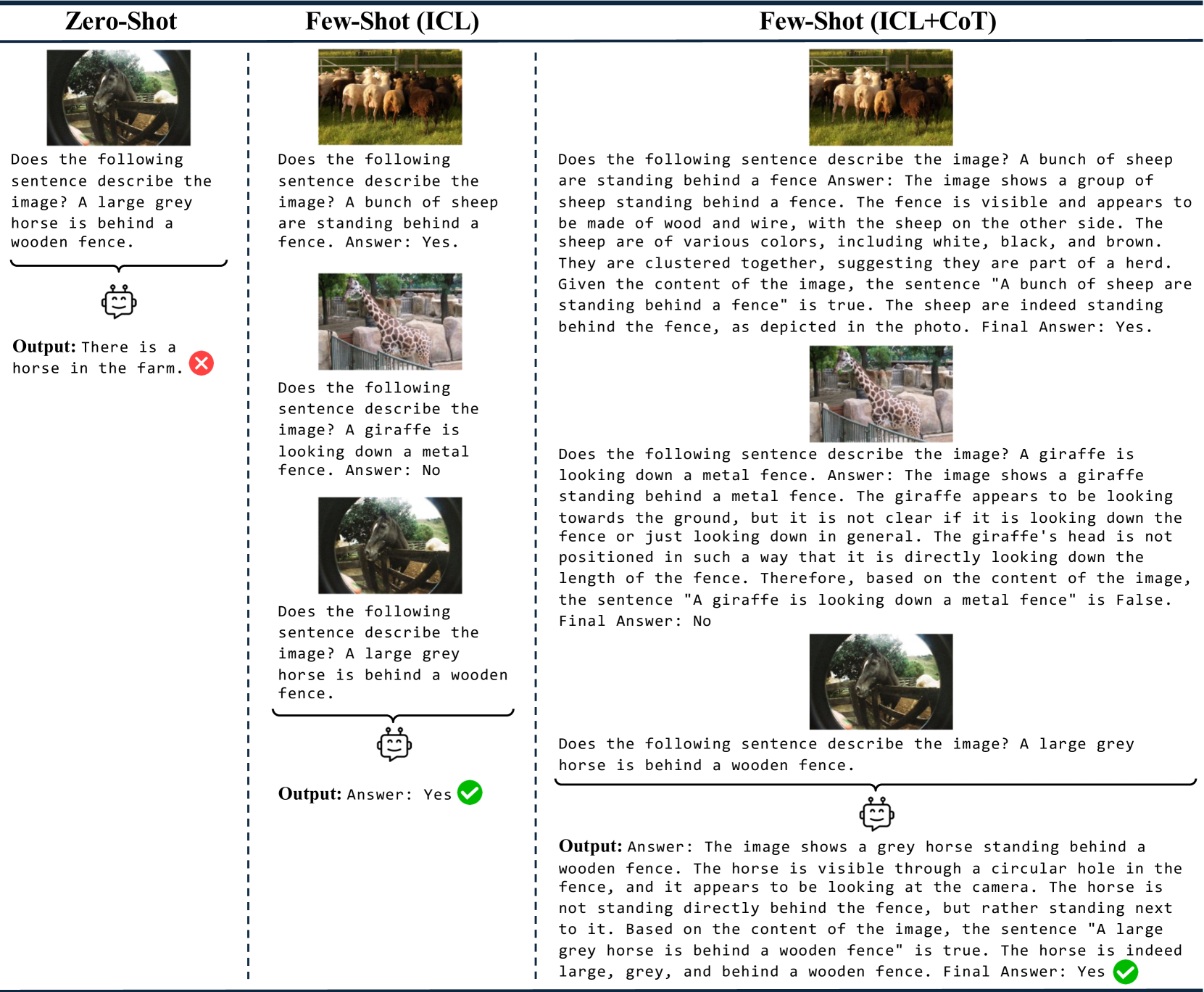
The linguistic capabilities of Multimodal Large Language Models (MLLMs) are critical for their effective application across diverse tasks. This study aims to evaluate the performance of MLLMs on the VALSE benchmark, focusing on the efficacy of few-shot In-Context Learning (ICL), and Chain-of-Thought (CoT) prompting. We conducted a comprehensive assessment of state-of-the-art MLLMs, varying in model size and pretraining datasets. The experimental results reveal that ICL and CoT prompting significantly boost model performance, particularly in tasks requiring complex reasoning and contextual understanding. Models pretrained on captioning datasets show superior zero-shot performance, while those trained on interleaved image-text data benefit from few-shot learning. Our findings provide valuable insights into optimizing MLLMs for better grounding of language in visual contexts, highlighting the importance of the composition of pretraining data and the potential of few-shot learning strategies to improve the reasoning abilities of MLLMs.
Read more7/18/2024
👀
0
Towards Multimodal In-Context Learning for Vision & Language Models
Sivan Doveh, Shaked Perek, M. Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shimon Ullman, Leonid Karlinsky
State-of-the-art Vision-Language Models (VLMs) ground the vision and the language modality primarily via projecting the vision tokens from the encoder to language-like tokens, which are directly fed to the Large Language Model (LLM) decoder. While these models have shown unprecedented performance in many downstream zero-shot tasks (eg image captioning, question answers, etc), still little emphasis has been put on transferring one of the core LLM capability of In-Context Learning (ICL). ICL is the ability of a model to reason about a downstream task with a few examples demonstrations embedded in the prompt. In this work, through extensive evaluations, we find that the state-of-the-art VLMs somewhat lack the ability to follow ICL instructions. In particular, we discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot demonstrations (in an ICL way), likely due to their lack of direct ICL instruction tuning. To enhance the ICL abilities of the present VLM, we propose a simple yet surprisingly effective multi-turn curriculum-based learning methodology with effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. Furthermore, we also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Read more7/18/2024
43
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Read more5/24/2024
❗
0
Can MLLMs Perform Text-to-Image In-Context Learning?
Yuchen Zeng, Wonjun Kang, Yicong Chen, Hyung Il Koo, Kangwook Lee
The evolution from Large Language Models (LLMs) to Multimodal Large Language Models (MLLMs) has spurred research into extending In-Context Learning (ICL) to its multimodal counterpart. Existing such studies have primarily concentrated on image-to-text ICL. However, the Text-to-Image ICL (T2I-ICL), with its unique characteristics and potential applications, remains underexplored. To address this gap, we formally define the task of T2I-ICL and present CoBSAT, the first T2I-ICL benchmark dataset, encompassing ten tasks. Utilizing our dataset to benchmark six state-of-the-art MLLMs, we uncover considerable difficulties MLLMs encounter in solving T2I-ICL. We identify the primary challenges as the inherent complexity of multimodality and image generation, and show that strategies such as fine-tuning and Chain-of-Thought prompting help to mitigate these difficulties, leading to notable improvements in performance. Our code and dataset are available at https://github.com/UW-Madison-Lee-Lab/CoBSAT.
Read more7/23/2024