Tapping in a Remote Vehicle's onboard LLM to Complement the Ego Vehicle's Field-of-View

0

Sign in to get full access
Overview
- Proposes a novel approach to enhance an ego vehicle's field-of-view using the large language model (LLM) of a remote vehicle
- Leverages cooperative intelligent transportation systems (C-ITS) and vehicle-to-vehicle (V2V) communication to access the remote vehicle's LLM
- Aims to improve pedestrian detection capabilities by combining the ego vehicle's sensors with the remote vehicle's LLM-based perception
Plain English Explanation
The paper discusses a way to improve the safety and performance of self-driving cars by tapping into the artificial intelligence (AI) capabilities of other nearby vehicles.
Self-driving cars, also known as autonomous vehicles, rely on a variety of sensors like cameras, radar, and lidar to perceive their surroundings. However, these sensors have limitations, and there may be blind spots or areas that the car's own sensors cannot adequately detect.
The researchers propose a solution where the self-driving car (the "ego vehicle") can wirelessly connect to the AI system of another nearby vehicle (the "remote vehicle"). This remote vehicle's AI, specifically its large language model, can then be used to supplement the ego vehicle's own perception, helping it to better identify objects like pedestrians that may be outside of its direct line of sight.
This approach leverages the emerging technologies of cooperative intelligent transportation systems (C-ITS) and vehicle-to-vehicle (V2V) communication, which allow vehicles to share information and collaborate with each other. By tapping into the remote vehicle's AI, the ego vehicle can effectively "see" more of its surroundings, enhancing its overall perception and safety.
Technical Explanation
The paper proposes a system that allows an ego vehicle to leverage the large language model (LLM) of a remote vehicle to complement its own field-of-view and improve pedestrian detection capabilities.
The system architecture consists of the following key components:
- Ego Vehicle: This is the self-driving vehicle that aims to enhance its perception using the remote vehicle's LLM.
- Remote Vehicle: Another nearby vehicle that has an onboard LLM, which the ego vehicle can access via cooperative intelligent transportation systems (C-ITS) and vehicle-to-vehicle (V2V) communication.
- V2V Communication Module: Facilitates the wireless exchange of data between the ego and remote vehicles.
- LLM Inference Module: Processes the remote vehicle's LLM outputs to generate enhanced perception results for the ego vehicle.
The key steps of the proposed approach are:
- The ego vehicle detects pedestrians and other objects using its own onboard sensors.
- The ego vehicle sends a request to the remote vehicle, asking it to use its LLM to analyze the surrounding environment.
- The remote vehicle's LLM processes the sensor data and generates a detailed understanding of the scene, including the detection and classification of pedestrians.
- The remote vehicle transmits the LLM-based perception results back to the ego vehicle over the V2V communication link.
- The ego vehicle's LLM Inference Module combines the local sensor data with the remote LLM outputs to enhance its overall perception of the environment, particularly in areas that may have been occluded or difficult for its own sensors to detect.
By leveraging the remote vehicle's powerful LLM, the ego vehicle can significantly improve its pedestrian detection capabilities, leading to enhanced safety and performance in autonomous driving scenarios.
Critical Analysis
The proposed approach presents several potential benefits, but also has some limitations that should be considered:
Benefits:
- Enhances the ego vehicle's perception by leveraging the remote vehicle's LLM, which may have superior object detection and classification capabilities.
- Addresses the field-of-view limitations of the ego vehicle's own sensors by combining local and remote perception data.
- Utilizes emerging C-ITS and V2V technologies to enable cooperative perception between vehicles, fostering a more connected and collaborative autonomous driving ecosystem.
Limitations:
- Relies on the availability and quality of the remote vehicle's LLM, which may vary across different vehicle models and manufacturers.
- Requires robust and reliable V2V communication to ensure timely and accurate exchange of perception data between vehicles.
- Potential privacy and security concerns related to sharing sensor data and LLM outputs between vehicles, which must be addressed.
- The system's performance may be affected by latency in the communication and processing of remote LLM outputs.
- The paper does not provide detailed experimental results or a comprehensive evaluation of the approach's effectiveness in real-world driving scenarios.
Overall, the proposed system presents an interesting and promising approach to enhancing autonomous vehicle perception by leveraging the capabilities of other nearby vehicles. However, the practical implementation and deployment of such a system would require addressing the noted limitations and potential challenges to ensure its reliability and widespread adoption in the autonomous driving domain.
Conclusion
The paper introduces a novel approach to improve an ego vehicle's field-of-view and pedestrian detection capabilities by tapping into the large language model (LLM) of a remote vehicle. By utilizing cooperative intelligent transportation systems (C-ITS) and vehicle-to-vehicle (V2V) communication, the ego vehicle can access and leverage the remote vehicle's superior LLM-based perception to complement its own sensor data.
This cooperative perception strategy has the potential to enhance the safety and performance of autonomous driving systems by addressing the limitations of individual vehicle sensors and leveraging the collective intelligence of connected vehicles. As the autonomous driving ecosystem continues to evolve, such collaborative approaches that harness the power of emerging technologies, like LLMs and V2V communication, may play a crucial role in realizing the full potential of self-driving cars and improving their ability to navigate complex urban environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tapping in a Remote Vehicle's onboard LLM to Complement the Ego Vehicle's Field-of-View
Malsha Ashani Mahawatta Dona, Beatriz Cabrero-Daniel, Yinan Yu, Christian Berger
Today's advanced automotive systems are turning into intelligent Cyber-Physical Systems (CPS), bringing computational intelligence to their cyber-physical context. Such systems power advanced driver assistance systems (ADAS) that observe a vehicle's surroundings for their functionality. However, such ADAS have clear limitations in scenarios when the direct line-of-sight to surrounding objects is occluded, like in urban areas. Imagine now automated driving (AD) systems that ideally could benefit from other vehicles' field-of-view in such occluded situations to increase traffic safety if, for example, locations about pedestrians can be shared across vehicles. Current literature suggests vehicle-to-infrastructure (V2I) via roadside units (RSUs) or vehicle-to-vehicle (V2V) communication to address such issues that stream sensor or object data between vehicles. When considering the ongoing revolution in vehicle system architectures towards powerful, centralized processing units with hardware accelerators, foreseeing the onboard presence of large language models (LLMs) to improve the passengers' comfort when using voice assistants becomes a reality. We are suggesting and evaluating a concept to complement the ego vehicle's field-of-view (FOV) with another vehicle's FOV by tapping into their onboard LLM to let the machines have a dialogue about what the other vehicle ``sees''. Our results show that very recent versions of LLMs, such as GPT-4V and GPT-4o, understand a traffic situation to an impressive level of detail, and hence, they can be used even to spot traffic participants. However, better prompts are needed to improve the detection quality and future work is needed towards a standardised message interchange format between vehicles.
Read more8/21/2024
0
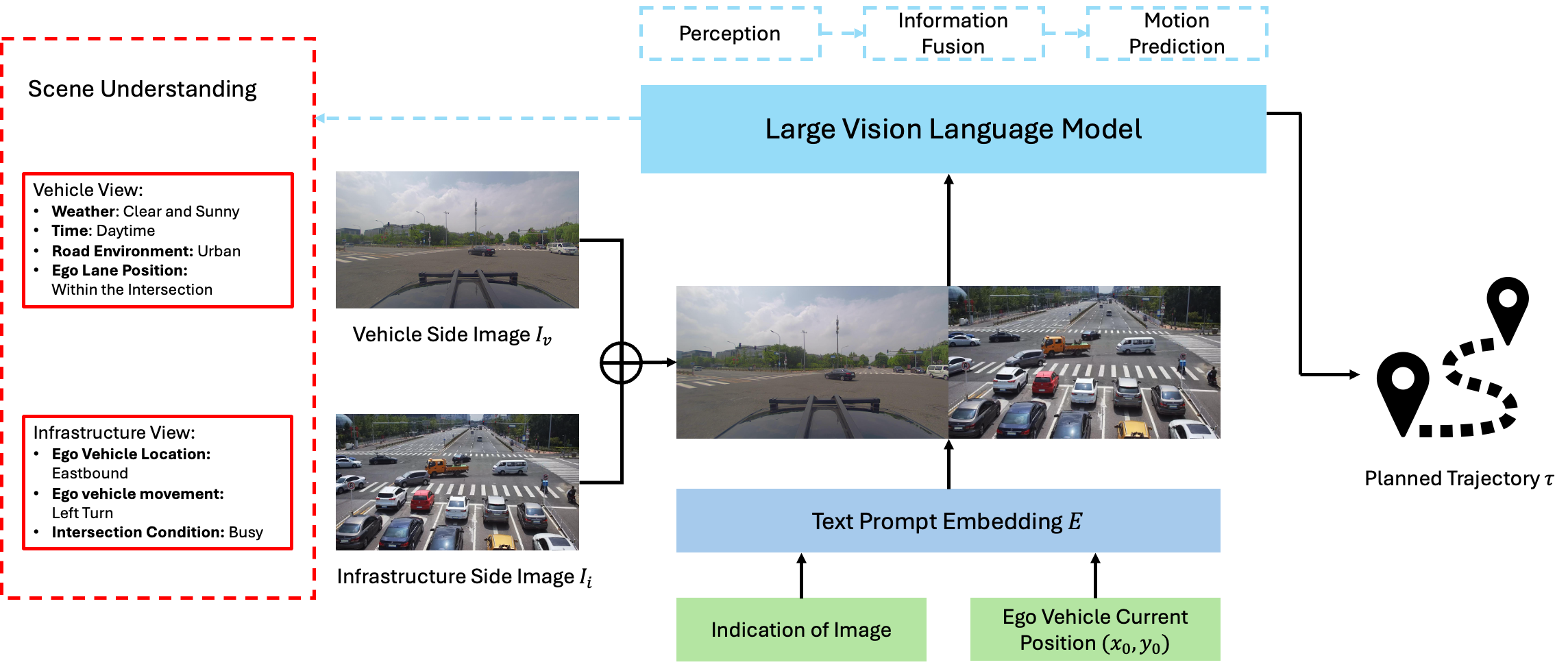
V2X-VLM: End-to-End V2X Cooperative Autonomous Driving Through Large Vision-Language Models
Junwei You, Haotian Shi, Zhuoyu Jiang, Zilin Huang, Rui Gan, Keshu Wu, Xi Cheng, Xiaopeng Li, Bin Ran
Advancements in autonomous driving have increasingly focused on end-to-end (E2E) systems that manage the full spectrum of driving tasks, from environmental perception to vehicle navigation and control. This paper introduces V2X-VLM, an innovative E2E vehicle-infrastructure cooperative autonomous driving (VICAD) framework with large vision-language models (VLMs). V2X-VLM is designed to enhance situational awareness, decision-making, and ultimate trajectory planning by integrating data from vehicle-mounted cameras, infrastructure sensors, and textual information. The strength of the comprehensive multimodel data fusion of the VLM enables precise and safe E2E trajectory planning in complex and dynamic driving scenarios. Validation on the DAIR-V2X dataset demonstrates that V2X-VLM outperforms existing state-of-the-art methods in cooperative autonomous driving.
Read more8/20/2024

0
Enhanced Cooperative Perception for Autonomous Vehicles Using Imperfect Communication
Ahmad Sarlak, Hazim Alzorgan, Sayed Pedram Haeri Boroujeni, Abolfazl Razi, Rahul Amin
Sharing and joint processing of camera feeds and sensor measurements, known as Cooperative Perception (CP), has emerged as a new technique to achieve higher perception qualities. CP can enhance the safety of Autonomous Vehicles (AVs) where their individual visual perception quality is compromised by adverse weather conditions (haze as foggy weather), low illumination, winding roads, and crowded traffic. To cover the limitations of former methods, in this paper, we propose a novel approach to realize an optimized CP under constrained communications. At the core of our approach is recruiting the best helper from the available list of front vehicles to augment the visual range and enhance the Object Detection (OD) accuracy of the ego vehicle. In this two-step process, we first select the helper vehicles that contribute the most to CP based on their visual range and lowest motion blur. Next, we implement a radio block optimization among the candidate vehicles to further improve communication efficiency. We specifically focus on pedestrian detection as an exemplary scenario. To validate our approach, we used the CARLA simulator to create a dataset of annotated videos for different driving scenarios where pedestrian detection is challenging for an AV with compromised vision. Our results demonstrate the efficacy of our two-step optimization process in improving the overall performance of cooperative perception in challenging scenarios, substantially improving driving safety under adverse conditions. Finally, we note that the networking assumptions are adopted from LTE Release 14 Mode 4 side-link communication, commonly used for Vehicle-to-Vehicle (V2V) communication. Nonetheless, our method is flexible and applicable to arbitrary V2V communications.
Read more4/15/2024
👀
0
Vision Language Models in Autonomous Driving: A Survey and Outlook
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Zagar, Walter Zimmer, Hu Cao, Alois C. Knoll
The applications of Vision-Language Models (VLMs) in the field of Autonomous Driving (AD) have attracted widespread attention due to their outstanding performance and the ability to leverage Large Language Models (LLMs). By incorporating language data, driving systems can gain a better understanding of real-world environments, thereby enhancing driving safety and efficiency. In this work, we present a comprehensive and systematic survey of the advances in vision language models in this domain, encompassing perception and understanding, navigation and planning, decision-making and control, end-to-end autonomous driving, and data generation. We introduce the mainstream VLM tasks in AD and the commonly utilized metrics. Additionally, we review current studies and applications in various areas and summarize the existing language-enhanced autonomous driving datasets thoroughly. Lastly, we discuss the benefits and challenges of VLMs in AD and provide researchers with the current research gaps and future trends.
Read more6/26/2024