Target-Dependent Multimodal Sentiment Analysis Via Employing Visual-to Emotional-Caption Translation Network using Visual-Caption Pairs

0
🌐
Sign in to get full access
Overview
- The paper focuses on Target-Dependent Multimodal Sentiment Analysis (TDMSA) to identify the sentiment associated with every target (aspect) in a multimodal post (visual-caption pair).
- The key challenge is to effectively obtain visual and emotional clues and synchronize them with the textual content.
- The proposed approach, called the Visual-to-Emotional-Caption Translation Network (VECTN), aims to acquire visual sentiment clues by analyzing facial expressions and align them with the target attribute of the caption.
Plain English Explanation
The researchers were interested in understanding the sentiment (positive, negative, or neutral) associated with specific aspects or targets mentioned in social media posts that contain both text and images. For example, a post might talk about a newly released product and include a photo of the product. The goal was to determine the sentiment towards the product itself, as well as any other relevant aspects like the design, price, or performance.
The main challenge is that sentiment can be conveyed through both the text and the visual elements of the post. The researchers wanted to find a way to effectively extract and combine these different sources of sentiment information.
To address this, the researchers developed a new technique called the Visual-to-Emotional-Caption Translation Network (VECTN). This approach first analyzes the facial expressions in the image to understand the emotional state it conveys. It then aligns this emotional information with the relevant targets or aspects mentioned in the text of the post.
By combining the sentiment signals from both the text and the visual elements, the researchers were able to improve the accuracy of identifying the sentiment towards specific targets within the multimodal social media posts.
Technical Explanation
The VECTN technique proposed in the paper aims to effectively capture visual sentiment clues by analyzing facial expressions and synchronize them with the textual content.
The architecture of VECTN consists of several key components:
-
Visual Feature Extractor: This module extracts visual features from the image, including facial expressions, using pre-trained computer vision models.
-
Emotional Feature Translator: The visual features are then passed through a neural network that translates them into emotional features, such as happiness, sadness, anger, etc.
-
Textual Feature Extractor: The text of the post is processed to extract relevant linguistic features, such as the targets (aspects) mentioned and their associated sentiment.
-
Multimodal Fusion: The emotional features from the visual modality and the textual features are then combined using a multimodal fusion module to produce the final target-level sentiment predictions.
The researchers evaluated the VECTN model on two publicly available multimodal Twitter datasets, Twitter-2015 and Twitter-2017. The results showed that the proposed approach outperformed other state-of-the-art methods, achieving an accuracy of 81.23% and a macro-F1 score of 80.61% on the Twitter-15 dataset, and 77.42% and 75.19% on the Twitter-17 dataset, respectively.
Critical Analysis
The paper presents a novel and promising approach to multimodal sentiment analysis, particularly in the context of social media posts. The incorporation of visual sentiment clues, specifically facial expressions, is a valuable addition to the traditional text-based sentiment analysis methods.
However, the paper does not address several potential limitations and areas for further research:
-
Dataset Bias: The evaluation was conducted on two Twitter datasets, which may not be representative of the broader multimodal sentiment analysis landscape. The performance of the VECTN model on other types of multimodal data, such as reviews or news articles, is not explored.
-
Real-Time Sentiment Analysis: The paper does not discuss the computational efficiency of the VECTN model, which is an important consideration for real-time sentiment analysis applications on social media.
-
Interpretability: The paper does not provide much insight into the interpretability of the model's predictions, i.e., how the visual and textual features contribute to the final sentiment assessments for each target.
-
Ethical Considerations: The use of facial expressions for sentiment analysis raises potential ethical concerns, such as privacy, bias, and the implications of automating emotional judgments. These issues are not addressed in the paper.
Future research could explore these areas to further enhance the capabilities and robustness of multimodal sentiment analysis techniques like VECTN.
Conclusion
The VECTN technique presented in this paper represents a significant advancement in the field of multimodal sentiment analysis. By effectively integrating visual sentiment cues, such as facial expressions, with textual information, the proposed approach demonstrates improved accuracy in identifying the sentiment towards specific targets or aspects within multimodal social media posts.
The findings of this study have the potential to enhance various applications, such as social media monitoring, customer feedback analysis, and opinion mining. As the use of multimodal data continues to grow, techniques like VECTN will become increasingly valuable in understanding the nuanced sentiments expressed across different communication channels.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Target-Dependent Multimodal Sentiment Analysis Via Employing Visual-to Emotional-Caption Translation Network using Visual-Caption Pairs
Ananya Pandey, Dinesh Kumar Vishwakarma
The natural language processing and multimedia field has seen a notable surge in interest in multimodal sentiment recognition. Hence, this study aims to employ Target-Dependent Multimodal Sentiment Analysis (TDMSA) to identify the level of sentiment associated with every target (aspect) stated within a multimodal post consisting of a visual-caption pair. Despite the recent advancements in multimodal sentiment recognition, there has been a lack of explicit incorporation of emotional clues from the visual modality, specifically those pertaining to facial expressions. The challenge at hand is to proficiently obtain visual and emotional clues and subsequently synchronise them with the textual content. In light of this fact, this study presents a novel approach called the Visual-to-Emotional-Caption Translation Network (VECTN) technique. The primary objective of this strategy is to effectively acquire visual sentiment clues by analysing facial expressions. Additionally, it effectively aligns and blends the obtained emotional clues with the target attribute of the caption mode. The experimental findings demonstrate that our methodology is capable of producing ground-breaking outcomes when applied to two publicly accessible multimodal Twitter datasets, namely, Twitter-2015 and Twitter-2017. The experimental results show that the suggested model achieves an accuracy of 81.23% and a macro-F1 of 80.61% on the Twitter-15 dataset, while 77.42% and 75.19% on the Twitter-17 dataset, respectively. The observed improvement in performance reveals that our model is better than others when it comes to collecting target-level sentiment in multimodal data using the expressions of the face.
Read more8/21/2024
0
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Gaurish Thakkar, Sherzod Hakimov, Marko Tadi'c
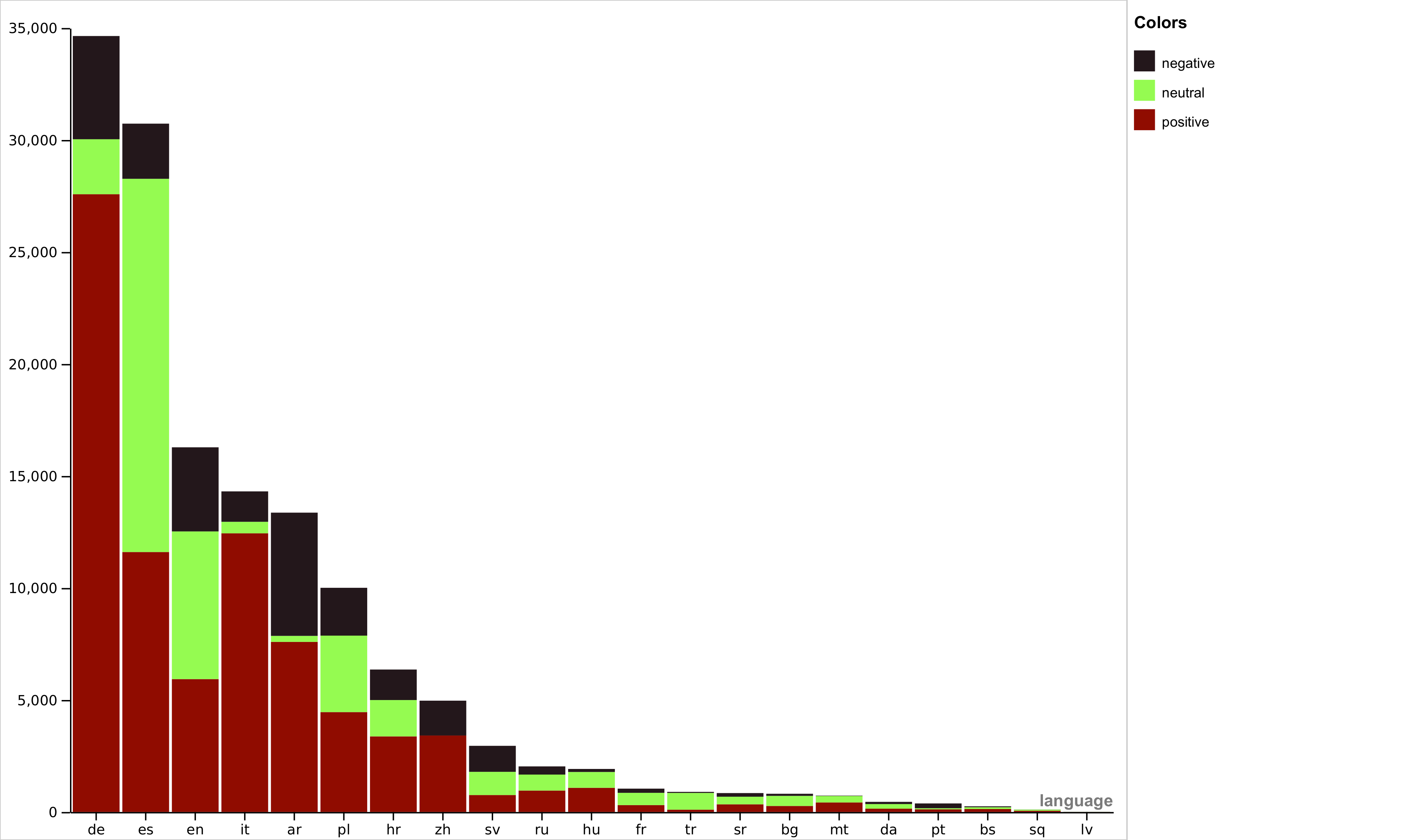
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
Read more6/13/2024
🗣️
0
Holistic Visual-Textual Sentiment Analysis with Prior Models
Junyu Chen, Jie An, Hanjia Lyu, Christopher Kanan, Jiebo Luo
Visual-textual sentiment analysis aims to predict sentiment with the input of a pair of image and text, which poses a challenge in learning effective features for diverse input images. To address this, we propose a holistic method that achieves robust visual-textual sentiment analysis by exploiting a rich set of powerful pre-trained visual and textual prior models. The proposed method consists of four parts: (1) a visual-textual branch to learn features directly from data for sentiment analysis, (2) a visual expert branch with a set of pre-trained expert encoders to extract selected semantic visual features, (3) a CLIP branch to implicitly model visual-textual correspondence, and (4) a multimodal feature fusion network based on BERT to fuse multimodal features and make sentiment predictions. Extensive experiments on three datasets show that our method produces better visual-textual sentiment analysis performance than existing methods.
Read more6/11/2024
0
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
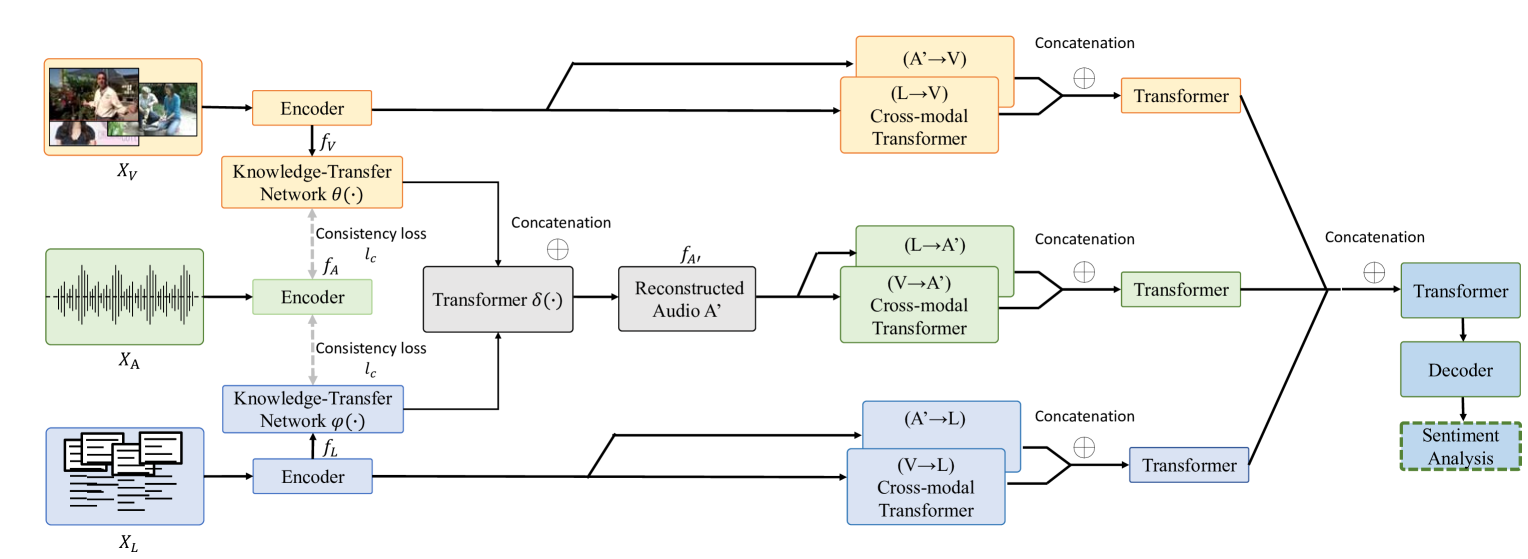
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
Read more7/12/2024