Holistic Visual-Textual Sentiment Analysis with Prior Models

0
🗣️
Sign in to get full access
Overview
- This paper proposes a novel approach to visual-textual sentiment analysis, which aims to predict the sentiment of an input image and text.
- The method involves four key components: a visual-textual branch, a visual expert branch, a CLIP branch, and a multimodal feature fusion network.
- The researchers claim this holistic approach leads to better performance on visual-textual sentiment analysis tasks compared to existing methods.
Plain English Explanation
The paper describes a new way to analyze the sentiment, or emotional tone, of a combination of an image and some accompanying text. This can be a challenging task, as the researchers need to find effective ways to extract meaningful features from both the visual and textual inputs.
To address this, the researchers developed a multi-part system. The first part directly learns features from the input data to predict sentiment. The second part uses a set of pre-trained "expert" encoders to extract specific types of visual features that are relevant for sentiment analysis. The third part, called CLIP, learns to implicitly understand the relationship between the visual and textual information. Finally, the fourth part is a neural network that combines all of these different features to make the final sentiment prediction.
The researchers tested this approach on several different datasets and found that it outperformed other existing methods for visual-textual sentiment analysis. This suggests their holistic approach of leveraging various pre-trained models and fusion techniques is an effective way to tackle this challenge.
Technical Explanation
The proposed method for visual-textual sentiment analysis consists of four key components:
-
Visual-Textual Branch: This branch directly learns features from the input image-text pairs to predict sentiment. It allows the model to discover relevant patterns in the data through end-to-end training.
-
Visual Expert Branch: This branch uses a set of pre-trained "expert" encoders to extract specific types of semantic visual features, such as object detection, scene recognition, and attribute prediction. These features are selected to be especially useful for sentiment analysis.
-
CLIP Branch: The CLIP branch leverages a pre-trained model that can learn the relationship between visual and textual information. This allows the system to implicitly capture the correspondence between the image and text.
-
Multimodal Feature Fusion Network: This component, based on the BERT architecture, fuses the features from the previous three branches and makes the final sentiment prediction.
The researchers evaluate their method on three different visual-textual sentiment analysis datasets and show that it outperforms existing state-of-the-art approaches. This demonstrates the effectiveness of their holistic approach in leveraging a diverse set of powerful pre-trained models to tackle this multimodal sentiment analysis task.
Critical Analysis
The paper provides a thoughtful and comprehensive solution to the challenge of visual-textual sentiment analysis. The researchers' decision to incorporate multiple pre-trained models, each focusing on different aspects of the problem, is a notable strength of the approach.
However, the paper does not address certain limitations or potential issues. For example, it is unclear how the method would scale to larger, more diverse datasets or how it would handle cases where the visual and textual information are not strongly correlated. Additionally, the computational cost and inference time of the full system are not discussed, which could be an important consideration for real-world applications.
Further research could explore ways to make the model more efficient or to better handle cases where the visual and textual modalities provide conflicting or ambiguous sentiment information. Investigating the model's robustness to noisy or adversarial inputs could also be a fruitful area of study.
Overall, the proposed method represents a significant advance in the field of visual-textual sentiment analysis, but there are still opportunities to refine and expand upon this research to address its current limitations.
Conclusion
This paper presents a novel approach to visual-textual sentiment analysis that leverages a diverse set of powerful pre-trained models to learn effective multimodal features. By combining a visual-textual branch, a visual expert branch, a CLIP branch, and a multimodal feature fusion network, the researchers have developed a holistic system that outperforms existing methods on several benchmark datasets.
The key innovation of this work is the way it harnesses a rich set of pre-trained models to tackle the challenge of sentiment analysis on image-text pairs. This demonstrates the potential of transfer learning and feature reuse to solve complex multimodal tasks. While the paper does not address all possible limitations, it represents an important step forward in the field of visual-textual sentiment analysis and could inspire further research to improve the robustness and efficiency of such systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Holistic Visual-Textual Sentiment Analysis with Prior Models
Junyu Chen, Jie An, Hanjia Lyu, Christopher Kanan, Jiebo Luo
Visual-textual sentiment analysis aims to predict sentiment with the input of a pair of image and text, which poses a challenge in learning effective features for diverse input images. To address this, we propose a holistic method that achieves robust visual-textual sentiment analysis by exploiting a rich set of powerful pre-trained visual and textual prior models. The proposed method consists of four parts: (1) a visual-textual branch to learn features directly from data for sentiment analysis, (2) a visual expert branch with a set of pre-trained expert encoders to extract selected semantic visual features, (3) a CLIP branch to implicitly model visual-textual correspondence, and (4) a multimodal feature fusion network based on BERT to fuse multimodal features and make sentiment predictions. Extensive experiments on three datasets show that our method produces better visual-textual sentiment analysis performance than existing methods.
Read more6/11/2024

0
Dual Modalities of Text: Visual and Textual Generative Pre-training
Yekun Chai, Qingyi Liu, Jingwu Xiao, Shuohuan Wang, Yu Sun, Hua Wu
The integration of visual and textual information represents a promising direction in the advancement of language models. In this paper, we explore the dual modality of language--both visual and textual--within an autoregressive framework, pre-trained on both document images and texts. Our method employs a multimodal training strategy, utilizing visual data through next patch prediction with a regression head and/or textual data through next token prediction with a classification head. We focus on understanding the interaction between these two modalities and their combined impact on model performance. Our extensive evaluation across a wide range of benchmarks shows that incorporating both visual and textual data significantly improves the performance of pixel-based language models. Remarkably, we find that a unidirectional pixel-based model trained solely on visual data can achieve comparable results to state-of-the-art bidirectional models on several language understanding tasks. This work uncovers the untapped potential of integrating visual and textual modalities for more effective language modeling. We release our code, data, and model checkpoints at url{https://github.com/ernie-research/pixelgpt}.
Read more10/4/2024
0
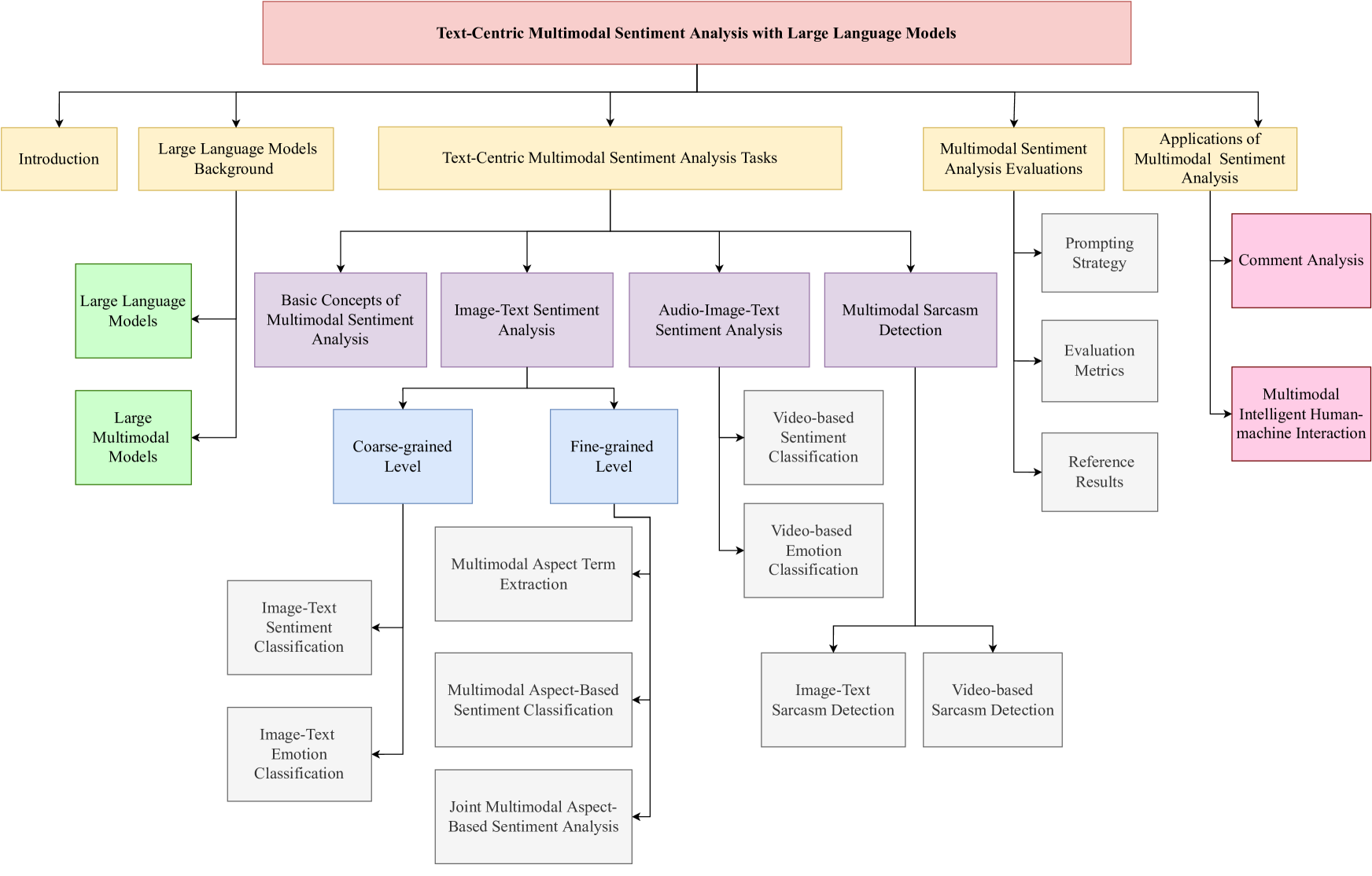
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
Hao Yang, Yanyan Zhao, Yang Wu, Shilong Wang, Tian Zheng, Hongbo Zhang, Zongyang Ma, Wanxiang Che, Bing Qin
Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
Read more8/19/2024
👀
0
Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
Adithya TG, Adithya SK, Abhinav R Bharadwaj, Abhiram HA, Dr. Surabhi Narayan
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
Read more6/3/2024