Task Oriented In-Domain Data Augmentation

0
Sign in to get full access
Overview
- The paper introduces a novel data augmentation approach called "Task Oriented In-Domain Data Augmentation" (TOID) that aims to improve model performance on specific tasks by generating additional training data tailored to the task and domain.
- TOID leverages large language models (LLMs) to generate synthetic data that aligns with the target task and domain, rather than relying on generic data augmentation techniques.
- The authors demonstrate the effectiveness of TOID on various natural language processing tasks, showing significant performance improvements over traditional data augmentation methods.
Plain English Explanation
The paper proposes a new way to improve the performance of machine learning models on specific tasks and domains. Traditional data augmentation techniques often rely on generic transformations, such as paraphrasing or text shuffling, to create additional training data. However, these approaches may not always be well-suited for the task at hand.
The researchers introduce Task Oriented In-Domain Data Augmentation (TOID), which uses large language models (LLMs) to generate synthetic data that is tailored to the specific task and domain. By leveraging the knowledge and language understanding of LLMs, TOID can create additional training examples that closely match the characteristics of the target task and domain, ultimately leading to better model performance.
The key idea behind TOID is to use the LLM to generate new text that is relevant and appropriate for the specific task, rather than relying on generic transformations. This allows the model to learn more effectively from the augmented data, as it is closely aligned with the task it needs to perform.
The authors demonstrate the effectiveness of TOID on various natural language processing tasks, such as text classification and question answering. By comparing TOID to traditional data augmentation methods, they show that their approach can significantly improve model performance, highlighting the benefits of tailoring the augmented data to the specific task and domain.
Technical Explanation
The paper introduces Task Oriented In-Domain Data Augmentation (TOID), a novel data augmentation technique that leverages large language models (LLMs) to generate synthetic data tailored to the target task and domain.
Unlike traditional data augmentation methods that rely on generic transformations, such as paraphrasing or text shuffling, TOID utilizes the rich knowledge and language understanding of LLMs to create additional training examples that closely match the characteristics of the task and domain.
The TOID approach involves the following key steps:
- Task and Domain Specification: The researchers define the target task and domain, which serves as the basis for guiding the data generation process.
- Prompt Engineering: The researchers carefully design prompts that instruct the LLM to generate new text that is relevant and appropriate for the specified task and domain.
- Synthetic Data Generation: The LLM is used to generate the synthetic data, which is then added to the original training dataset to enhance the model's learning.
The authors evaluate the effectiveness of TOID on various natural language processing tasks, such as text classification and question answering. The results demonstrate that TOID outperforms traditional data augmentation methods, highlighting the benefits of tailoring the augmented data to the specific task and domain.
Critical Analysis
The paper presents a compelling approach to data augmentation, but there are a few aspects that could be further explored or addressed:
-
Prompt Engineering Complexity: The effectiveness of TOID is heavily dependent on the quality of the prompts used to guide the LLM's data generation. Designing effective prompts can be a complex and time-consuming task, which may limit the practical applicability of the method, especially for non-expert users.
-
Generalization Ability: While TOID demonstrates strong performance on the specific tasks and domains evaluated in the paper, it is unclear how well the approach would generalize to other tasks or domains. Further research is needed to understand the broader applicability of TOID.
-
Potential Biases: The use of LLMs in the data generation process may introduce biases present in the LLMs' training data, which could negatively impact the quality and diversity of the synthetic data. The paper does not address this potential issue in depth.
-
Computational Costs: The paper does not provide a detailed analysis of the computational resources required to implement TOID, which may be a practical concern for some applications.
Despite these caveats, the TOID approach represents a promising direction in the field of data-driven knowledge transfer and task-specific data augmentation. Further research and refinement of the method could lead to significant advancements in improving model performance on a wide range of tasks and domains.
Conclusion
The "Task Oriented In-Domain Data Augmentation" (TOID) method introduced in this paper offers a novel approach to data augmentation that leverages the capabilities of large language models to generate synthetic data tailored to the target task and domain. By leveraging the rich knowledge and language understanding of LLMs, TOID can create additional training examples that are highly relevant and appropriate for the specific task, leading to significant performance improvements over traditional data augmentation techniques.
The paper demonstrates the effectiveness of TOID on various natural language processing tasks, showcasing its potential to enhance model performance in a wide range of applications. While the method faces some challenges, such as the complexity of prompt engineering and potential biases, the core idea of task-specific data augmentation using LLMs represents an exciting direction for future research in the field of machine learning and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Task Oriented In-Domain Data Augmentation
Xiao Liang, Xinyu Hu, Simiao Zuo, Yeyun Gong, Qiang Lou, Yi Liu, Shao-Lun Huang, Jian Jiao
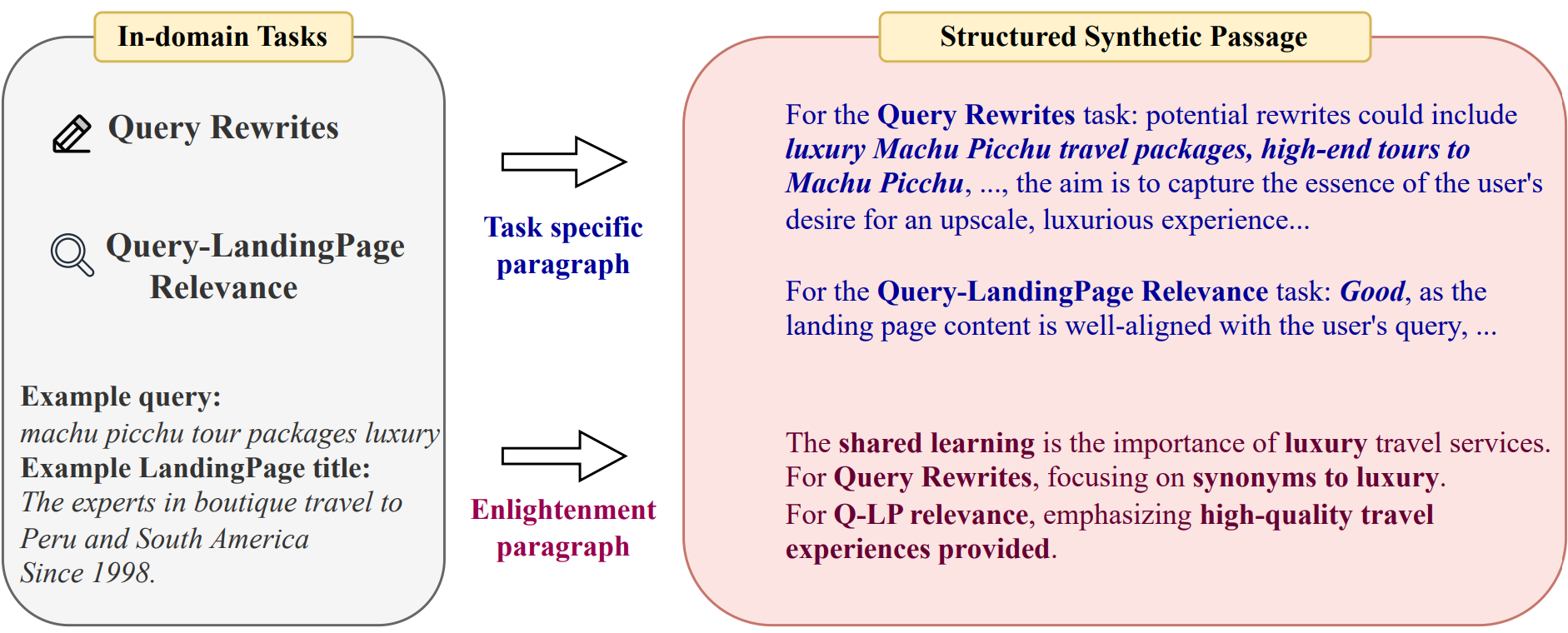
Large Language Models (LLMs) have shown superior performance in various applications and fields. To achieve better performance on specialized domains such as law and advertisement, LLMs are often continue pre-trained on in-domain data. However, existing approaches suffer from two major issues. First, in-domain data are scarce compared with general domain-agnostic data. Second, data used for continual pre-training are not task-aware, such that they may not be helpful to downstream applications. We propose TRAIT, a task-oriented in-domain data augmentation framework. Our framework is divided into two parts: in-domain data selection and task-oriented synthetic passage generation. The data selection strategy identifies and selects a large amount of in-domain data from general corpora, and thus significantly enriches domain knowledge in the continual pre-training data. The synthetic passages contain guidance on how to use domain knowledge to answer questions about downstream tasks. By training on such passages, the model aligns with the need of downstream applications. We adapt LLMs to two domains: advertisement and math. On average, TRAIT improves LLM performance by 8% in the advertisement domain and 7.5% in the math domain.
Read more6/26/2024

0
Knowledge-Based Domain-Oriented Data Augmentation for Enhancing Unsupervised Sentence Embedding
Peichao Lai, Zhengfeng Zhang, Bin Cui
Recently, unsupervised sentence embedding models have received significant attention in downstream natural language processing tasks. Using large language models (LLMs) for data augmentation has led to considerable improvements in previous studies. Nevertheless, these strategies emphasize data augmentation with extensive generic corpora, neglecting the consideration of few-shot domain data. The synthesized data lacks fine-grained information and may introduce negative sample noise. This study introduces a novel pipeline-based data augmentation method that leverages LLM to synthesize the domain-specific dataset. It produces both positive and negative samples through entity- and quantity-aware augmentation, utilizing an entity knowledge graph to synthesize samples with fine-grained semantic distinctions, increasing training sample diversity and relevance. We then present a Gaussian-decayed gradient-assisted Contrastive Sentence Embedding (GCSE) model to reduce synthetic data noise and improve model discrimination to reduce negative sample noise. Experimental results demonstrate that our approach achieves state-of-the-art semantic textual similarity performance with fewer synthetic data samples and lesser LLM parameters, demonstrating its efficiency and robustness in varied backbones.
Read more9/20/2024

0
Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges
Bosheng Ding, Chengwei Qin, Ruochen Zhao, Tianze Luo, Xinze Li, Guizhen Chen, Wenhan Xia, Junjie Hu, Anh Tuan Luu, Shafiq Joty
In the rapidly evolving field of large language models (LLMs), data augmentation (DA) has emerged as a pivotal technique for enhancing model performance by diversifying training examples without the need for additional data collection. This survey explores the transformative impact of LLMs on DA, particularly addressing the unique challenges and opportunities they present in the context of natural language processing (NLP) and beyond. From both data and learning perspectives, we examine various strategies that utilize LLMs for data augmentation, including a novel exploration of learning paradigms where LLM-generated data is used for diverse forms of further training. Additionally, this paper highlights the primary open challenges faced in this domain, ranging from controllable data augmentation to multi-modal data augmentation. This survey highlights a paradigm shift introduced by LLMs in DA, and aims to serve as a comprehensive guide for researchers and practitioners.
Read more7/1/2024

0
A synthetic data approach for domain generalization of NLI models
Mohammad Javad Hosseini, Andrey Petrov, Alex Fabrikant, Annie Louis
Natural Language Inference (NLI) remains an important benchmark task for LLMs. NLI datasets are a springboard for transfer learning to other semantic tasks, and NLI models are standard tools for identifying the faithfulness of model-generated text. There are several large scale NLI datasets today, and models have improved greatly by hill-climbing on these collections. Yet their realistic performance on out-of-distribution/domain data is less well-understood. We explore the opportunity for synthetic high-quality datasets to adapt NLI models for zero-shot use in downstream applications across new and unseen text domains. We demonstrate a new approach for generating NLI data in diverse domains and lengths, so far not covered by existing training sets. The resulting examples have meaningful premises, the hypotheses are formed in creative ways rather than simple edits to a few premise tokens, and the labels have high accuracy. We show that models trained on this data ($685$K synthetic examples) have the best generalization to completely new downstream test settings. On the TRUE benchmark, a T5-small model trained with our data improves around $7%$ on average compared to training on the best alternative dataset. The improvements are more pronounced for smaller models, while still meaningful on a T5 XXL model. We also demonstrate gains on test sets when in-domain training data is augmented with our domain-general synthetic data.
Read more7/1/2024